用深度神经网络生成以假乱真的“照片”
2016年12月20日,The Verge发布了一篇报道《 Artificial intelligence is going to make it easier than ever to fake images and video 》(姑且译为《AI,人类再也无法阻挡的P图大师》)。其中,进化AI实验室 Evolving AI Lab 的实验室主任 Jeff Clune 分享了大量近年来AI在图像处理方面的进展。
本文整理出该报道中提及的论文和项目,以供参考。此外,Evolving AI Lab近年来还有 很多各方面的有趣成果 ,也在此推荐。
从DeepVis到PPGN
2015年,深度神经网络(DNN)已经能够比较准确的识别照片类图像中的各种对象。然而,当人们尝试用DNN去生成指定对象类型的图像(比如,一辆校车)时,却发现完全不是那么一回事。

图:DNN生成的“校车”
Anh Nguyen、Jason Yosinski和Jeff Clune在CPVR'15发布了一篇论文 Deep neural networks are easily fooled ,介绍他们把此类生成的图像丢给其他的DNN(包括当时最前沿的LeNet)进行辨认,结果发现大部分DNN都开始“犯傻”:

图:LeNet认为上面这几张图都是手写的数字“0”
接下来,该研究组进一步深入探索:DNN在学习过程中究竟发生了什么?其识别一粒棒球、一辆校车或一个手写数字的依据是什么,为何会把在人眼看来完全无意义的图像识别为有意义的对象?同年,他们在ICML上又发布了一篇报告 Understanding Neural Networks Through Deep Visualization ( 论文下载 ),并在Github上分享了论文中用到的工具 DeepVis Toolbox 。通过该工具,人可以直观的看到当DNN接受到一张图片时,具体活跃的是哪些神经节点,以及不同的神经节点是因为哪些特征而被触发。
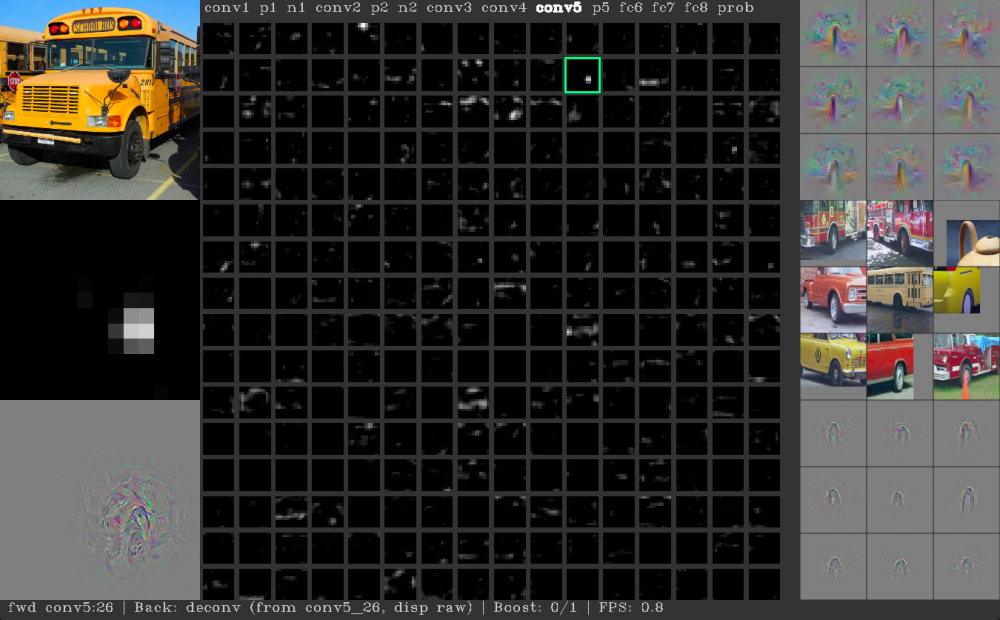
图:当前选中的神经节点对“车轮”产生了反应
由此,研究组得以发现,当时大部分的DNN在识别图像中对象的过程中主要依据的特征是一些局部的独特痕迹(如豹子身上的斑点、校车的黑黄色),而忽略了整体特征(如海星的五角星形状、豹子长了四条腿)。
知道了DNN所忽略的特征,从而有针对性的进行算法的改进,就有可能大幅提升DNN生成指定图像的能力。2016年,该研究组先后发布了两篇论文介绍 Deep Generator Networks(DGN) 以及其改良版 Plug & Play Generative Networks(PPGN) ,这些改良后的神经网络——创作网络 Generator Network——足以生成以假乱真的图片:

图:PPGN生成的火山“照片”

图:向PPGN输入词组“a_church_steeple_that_has_a_clock_on_it”所获得的图像
现在,深度神经网络的“创作能力”已经能够胜任很多复杂的工作,比如各种“玩脸”、改图,甚至还能够给视频自动配音。
2015-2016,AI的创作力
用2D照片创建人脸3D模型
Shunsuke Saito等人 于2016年12月发布在ArXiv的论文 中介绍了一种方法,通过深度神经网络提取2D照片中的人脸特征,创建出完整的面部3D模型。 点击这里查看该论文在YouTube上的介绍视频 。

图:根据低分辨率照片生成的面部3D模型
Smile Vector
Tom White ( @dribnet )在2016年5月上线了一个Twitter机器人 Smile Vector ,可自动为图片中的人脸添加微笑(以及其他表情)。相关论文 Sampling Generative Networks 在2016年9月发布,并 在2016年12月的NIPS大会上进行了演示 。

Face2Face
Justus Thies 等人发布在CVPR 2016上的报告 Face2Face: Real-time Face Capture and Reenactment of RGB Videos 中介绍了一种方法,将摄像头前(就是普通的消费级摄像头)的演员的面部表情“实时移植”到一段视频中的人物脸上。
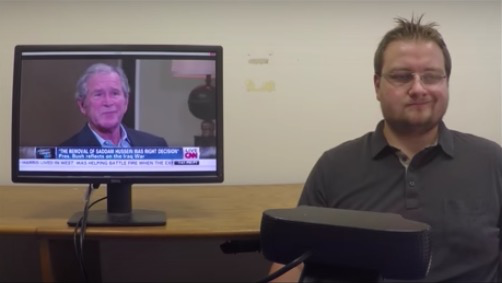
图:“表情移植”
川普变光头
Samson ,一个 将辩论视频中的川普实时替换成光头 的小程序。

图:变成光头的川普
永驻银屏的Joey
Virtual Immortality,来自英国利兹大学的研究成果,发布在 2016年10月的VARVAI Workshop 。该研究组让神经网络学习了236集《老友记》,实现了一个“ 可以在任何视频中乱入、做各种Joey风格动作、讲各种Joey风格台词的Joey ”( 论文下载 )。

图:AI生成的乱入Joey
照片补光(Image Relighting)
微软研究院在SIGGRAPH 2015上发布的报告 Image Based Relighting Using Neural Networks 介绍了一种给照片补光的深度学习方法。该成果被 Two Minute Papers 做成了视频短片 发布在YouTube 。

图:用深度神经网络给照片补光
把照片变成梵高的画
画风移植(Style Transfer)是一项已经在图像处理领域发展了多年的技术。The Verge的这篇报道中提及了一个用神经网络进行艺术作品画风移植的实现,源自Leon A. Gatys等人在2015年8月发布的一篇论文 A Neural Algorithm of Artistic Style ,其效果如下:

该研究组已经将论文中使用的代码 分享至Github ,普通用户可以在 Deepart网站 或者 Prisma App 上体验该算法的效果。此外,Facebook App也 在2016年底上线了类似的实现 ( 相关论文在此查看 )。
看图创作配音
MIT AI实验室在2015年12月发布的论文 Visually Indicated Sounds ( 下载 ),介绍一种根据图像生成匹配声音的算法。该算法使用一个循环神经网络 recurrent neural network,根据视频中的图像内容(如草坪、水、塑料袋或布料被其他物体触碰)预测声音的特征,并基于声音库生成对应的波形。
总结
如上所述,AI的“创作能力”正在快速提升。此类创作能力将适用于图像、音视频、文字等各种媒介,并且快速的从实验室走到普通消费者的手中。在这一过程中,相信无论对于开发者还是对于内容创作者,都蕴藏着大量的机遇。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

