如何设计友好的 WebHook
在一些工具流的设计中,经常遇到一个体验非常不好的情况:
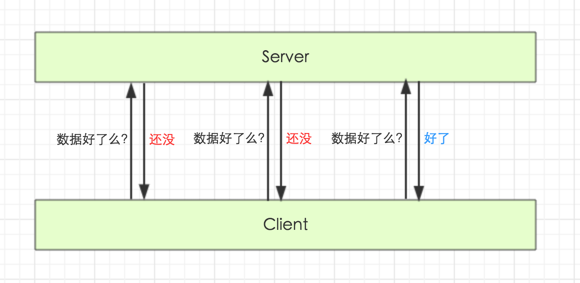
每次都需要采用长轮询或者隔一段时间再尝试的方式获取结果。其原因可能有两个:
- 调用方(Client)没有一个稳定的在线服务,Server 无法主动联系 Client
- Server 并没有考虑主动 Push 消息
WebHook 存在的前提也需要满足以上两点,基本交互流程如下图:
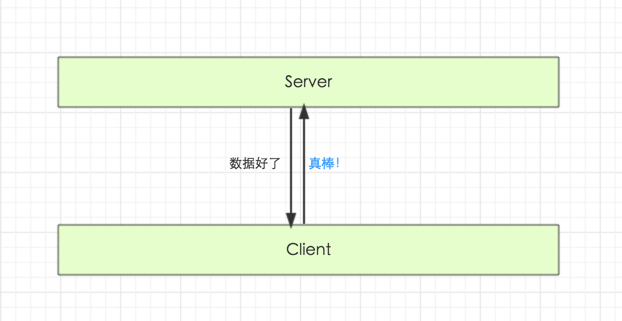
WebHook 的设计
1、接口设计
WebHook 需要具备良好的自解性,也就是调用 Client 接口时,将自己完整的信息传达到客户端:
// POST
{
"source": {
"platform": "A Niubility Platform",
"other": "other infomation"
},
"target": {
"name": "Barret Lee",
"version": "1.0.0",
"other": "other infomation"
},
"data": {
//...
},
"needCallback": true,
"serverTime": "2016-12-26 11:55:45"
}
在接口中需要详细说明,数据源从哪里来(source),数据需要穿给谁(target),传递那些数据(data),是否需要对方发送回执(needCallback),以及其他信息。
这样做的目的是为了避免发送出现错误,比如发错了对象;即便出错也方便通过日志记录排查问题。
2、多 Hook 设计
| URI | 备注 | 操作 |
|---|---|---|
| http://example.com/receiveHook | 通知小李修 bug | 删除 / 编辑 |
| http://example2.com/receiveHook | 通知小王修 bug | 删除 / 编辑 |
WebHook 的设计一定要支持多 Hook,你永远都不知道下一个系统对接需求会在什么时候到来。
对于复杂的 Hook 设计,表格中可能还有:是否需要回执、是否停用、安全 Token、数据配置等项。
3、安全性设计
这里的安全性是为 Client 考虑的,Client 可能对 refer 或者 origin 做了限制,但这远远不够。当用户在 Server 端注册 WebHook 时,就应该开始考虑 Hook 的安全性了:
// POST
response.setHeader("x-webhook-sign", SHA1(webhook));
Client 在接收到 WebHook 时需要验证 x-webhook-sign 字段,如果不正确应该向服务器响应的错误码(或许此时服务器收到错误码后应该停用这个 Hook)。
4、retry 机制
极有可能因为 Client 的不稳定,导致 Hook 调用失败,此时可以考虑多次尝试:
request({
url: webhookURL,
retryTimes: 2,
// ...
});
小结
对于阻塞链路的 WebHook,比如对页面进行性能检测,只有检测通过后页面才可以发布,Client 端可能也需要提供类似的 WebHook 回执。
随着应用的复杂度提升,系统解耦变得越来越重要,WebHook 作为一种通用的交互方案,在设计上多留一个心眼,十分有意义!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

