宋睿华:好玩的文本生成

文本生成是比较学术的说法,通常在媒体上见到的“机器人写作”、“人工智能写作”、“自动对话生成”、“机器人写古诗”等,都属于文本生成的范畴。
二零一六年里,关于文本生成有许多的新闻事件,引起了学术界以外对这一话题的广泛关注。
- 2016年3月3日,MIT CSAIL【1】报道了,MIT计算机科学与人工智能实验室的一位博士后开发了一款推特机器人,叫DeepDrumpf,它可以模仿当时的美国总统候选人Donald Trump来发文。
- 2016年3月22日,日本共同社报道,由人工智能创作的小说作品《机器人写小说的那一天》入围了第三届星新一文学奖的初审。这一奖项以被誉为“日本微型小说之父”的科幻作家星新一命名。提交小说的是“任性的人工智能之我是作家”(简称“我是作家”)团队【2】。
- 2016年5月,美国多家媒体【3】【4】报道,谷歌的人工智能项目在学习了上千本浪漫小说之后写出后现代风格的诗歌。
基于人工智能的文本生成真的已经达到媒体宣传的水平了吗?这些事件背后是怎样的人工智能技术?关于机器人写小说的工作,我们会在另一篇文章《会有那么一天,机器人可以写小说吗?》里进行深入的讨论,他们的工作更多的是基于模板的生成。在这篇文章里,我们主要想通过三篇文章介绍另一大类方法,即基于统计的文本生成。
第一篇令人吃惊的Char-RNN
关于基于深度学习的文本生成,最入门级的读物包括Andrej Karpathy这篇博客【5】。他使用例子生动讲解了Char-RNN(Character based Recurrent Neural Network)如何用于从文本数据集里学习,然后自动生成像模像样的文本。
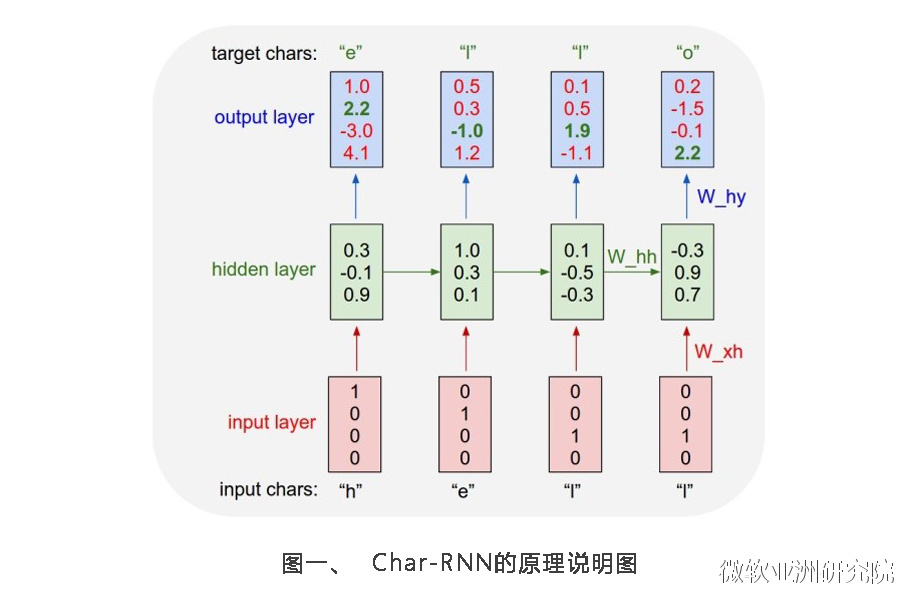
图一直观展示了Char-RNN的原理。以要让模型学习写出“hello”为例,Char-RNN的输入输出层都是以字符为单位。输入“h”,应该输出“e”;输入“e”,则应该输出后续的“l”。输入层我们可以用只有一个元素为1的向量来编码不同的字符,例如,h被编码为“1000”、“e”被编码为“0100”,而“l”被编码为“0010”。使用RNN的学习目标是,可以让生成的下一个字符尽量与训练样本里的目标输出一致。在图一的例子中,根据前两个字符产生的状态和第三个输入“l”预测出的下一个字符的向量为<0.1, 0.5, 1.9, -1.1>,最大的一维是第三维,对应的字符则为“0010”,正好是“l”。这就是一个正确的预测。但从第一个“h”得到的输出向量是第四维最大,对应的并不是“e”,这样就产生代价。学习的过程就是不断降低这个代价。学习到的模型,对任何输入字符可以很好地不断预测下一个字符,如此一来就能生成句子或段落。
Andrej Karpathy还共享了代码【6】,感兴趣的同学不妨下载来试试,效果会让你震惊。Andrej Karpathy在底层使用的RNN的具体实现是LSTM(Long-Short Term Memory),想了解LSTM可以阅读【7】,讲得再清楚不过。
研究人员用Char-RNN做了很多有趣的尝试,例如,用莎士比亚的作品来做训练,模型就能生成出类似莎士比亚的句子;利用金庸的小说来做训练,模型就能生成武侠小说式的句子;利用汪峰的歌词做训练,模型也能生成类似歌词的句子来。
在本文一开始提到的【1】,MIT计算机科学与人工智能实验室的博士后Bradley Hayes也正是利用类似的方法开发了一款模仿候任美国总统Donald Trump的推特机器人,叫DeepDrumpf。例如,图二中,这个机器人说,“我就是伊斯兰国不需要的。”
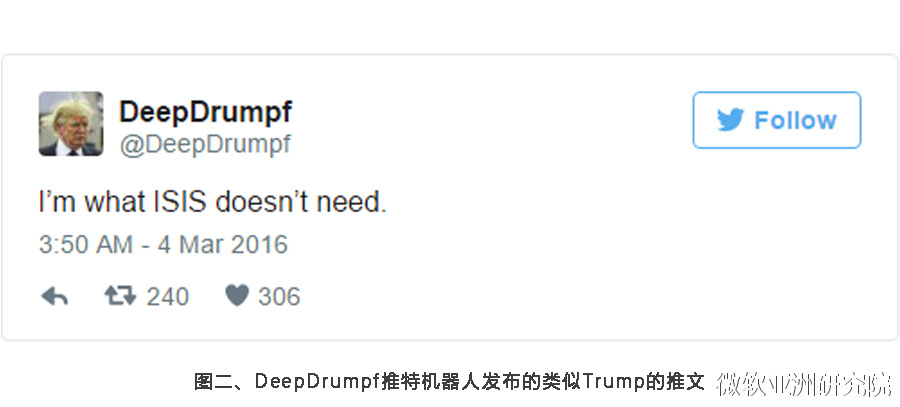
据作者介绍,他受到一篇模拟莎士比亚的论文启发,以Donald Trump的演讲和辩论(时常大约几个小时)的字幕作为训练语料,使用深度神经网络学习去训练Trump的模型。他也声称,因为有一篇文章调侃Trump的发言只有小学四年级的水平,因而想到用Trump的语料可能是最容易控制的。
这是一个有趣的应用,记者评论称这个机器人也并不是总能写出好的句子,但至少部分是通顺的。其实,风格并不是很难学到,只要使用的训练语料来自同一个人,而这个人的写作或者发言具有辨识度高的特点。
第二篇深度学习生成对话
推荐阅读的第二篇文章是诺亚方舟实验室的尚利峰、吕正东和李航在2015年ACL大会上发表的“Neural Responding Machine for Short-Text Conversation” 【9】。大家也许听说过微软小冰,它因为开创性的主要做闲聊(即以娱乐为目的的聊天)式对话,被哈尔滨工业大学的刘挺教授誉为是第二波人机对话的浪潮的代表【8】。小冰的出现也影响到了学术界。除了原来做知识性的问答,一些研究也开始关注闲聊,让机器人和人类搭话,这方面诺亚方舟实验室发表了一系列有影响力的文章。今天介绍的这篇文章在Arxiv.org上发布短短一年时间,已经有67次的引用。
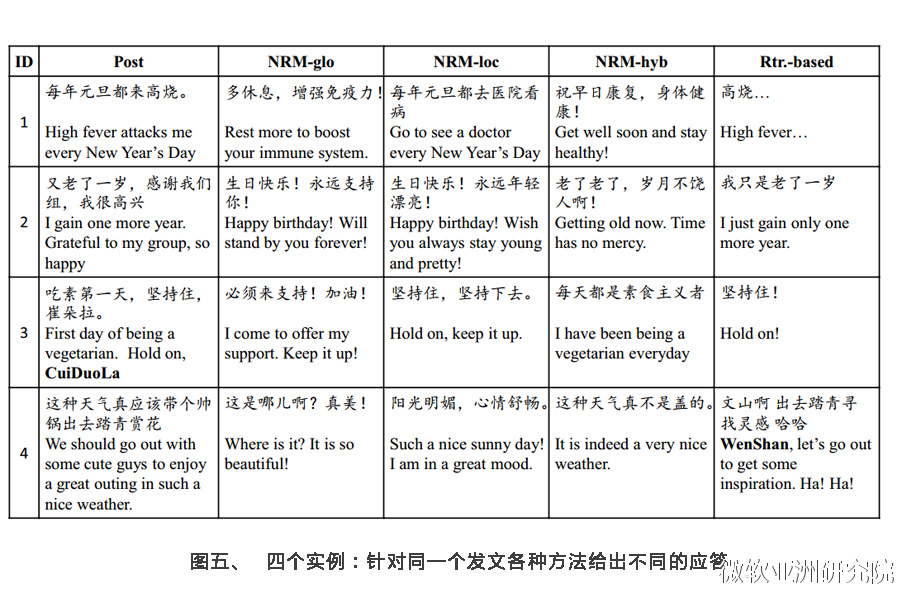
【9】这篇文章尝试用encoder-decoder(编码-解码)的框架解决短文本对话(Short Text Conversation,缩写为STC)的问题。虽然encoder-decoder框架已经被成功应用在机器翻译的任务中,但是对话与翻译不同,对应一个输入文本(post)往往有多种不同的应答(responses)。文中举了一个例子,一个人说“刚刚我吃了一个吞拿鱼三明治”,不同的应答可以是“天哪,才早晨11点”、“看起来很美味哟”或是“在哪里吃的”。这种一对多的情况在对话中很普遍也很自然。的确,不同的人会对同一句话做出不同的反应,即使是同一个人,如果每次回答都一模一样也是很无趣的。
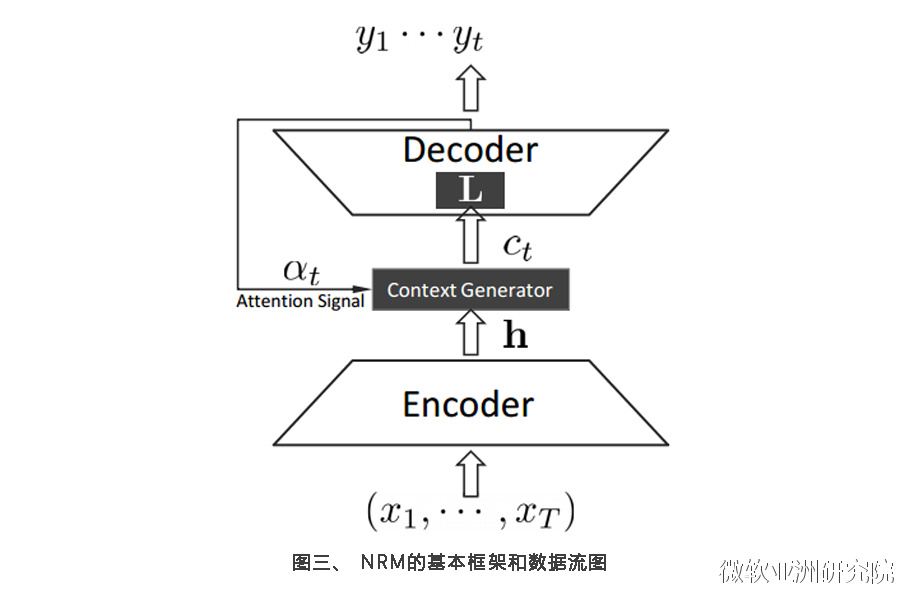
针对这一特点,作者们提出Neural Responding Machine(简称NRM,见图三)框架来解决短文本对话的问题。他们尝试了全局编码和局部编码,最终发现先分别训练,再用图四的结构来做微调训练,效果最佳。全局编码的优点是能够获得全局信息,同样的词在不同情境下会有不同的意义,全局信息可以部分解决这类情况;缺点是,它供给解码的输入比较固定。局部编码利用局部信息,比较灵活多样,刚好可以缓解全局编码的弱点。
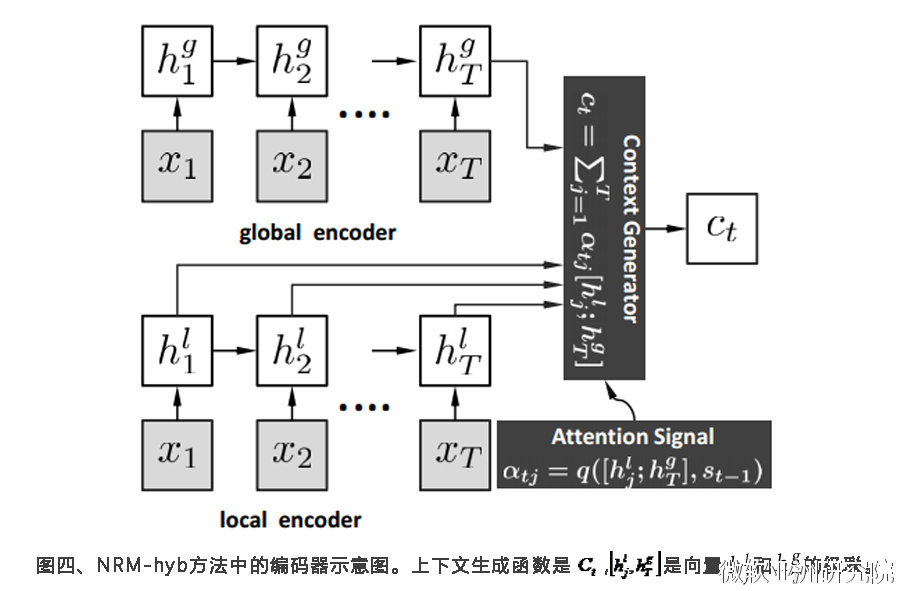
这篇论文的另一大贡献是构建了一个比较大的数据集和标注来评价不同的方法。通过对比,所提出的混合全局和局部的方法比以往基于搜索的方法和机器翻译的方法都要好很多。机器翻译的方法生成的句子往往不通顺,得分最低。能比基于搜索的方法好很多也非常不容易,因为基于搜索的方法得到的已经是人使用过的应答,不会不通顺。大家可以在图五的实例中直接感受一下生成的效果。NRM-glo是全局编码的模型,NRM-loc是局部编码的模型,NRM-hyb是混合了全局和局部的模型,Rtr.-based则是基于搜索的方法。
2015到2016年,这篇论文的作者组织了NTCIR-12 STC任务【10】,公开他们的数据集,并提供公共评测。有16个大学或研究机构参加了中文短文本对话任务的评测。2017年,他们将会继续组织NTCIR-13 STC【11】,现已开放注册【12】。除了上一届的基于搜索的子任务,这一次还设立了生成应答的子任务。我们预计今年的结果会更精彩。
第三篇被媒体误解的谷歌人工智能写诗
第三篇文章是Samuel Bowman等发表在Arxiv.org上的名为“Generating Sentences from a Continuous Space”的文章【13】。作者分别来自斯坦福大学、马萨诸塞大学阿姆斯特分校以及谷歌大脑部门,工作是在谷歌完成的。
这一工作曾被媒体广泛报道,但我发现很多报道(例如【3】【4】)都对论文的工作有一些误解。一些记者将图六所示的文字误认为是机器人写出来的后现代风格的诗歌,其实不然。这只是作者在展示他们的方法可以让句子级别的编码解码更连续。具体而言,在他们学习到的空间中,每个点可以对应一个句子,任意选定两个点,例如在图六中,一对点对应的句子分别是“i want to talk to you.”和“she didn’t want to be with him”,两点之间的连线上可以找出间隔均匀的几个点,将它们也解码成句子,会发现,这些句子好像是从第一句逐渐变化成了最后一句。
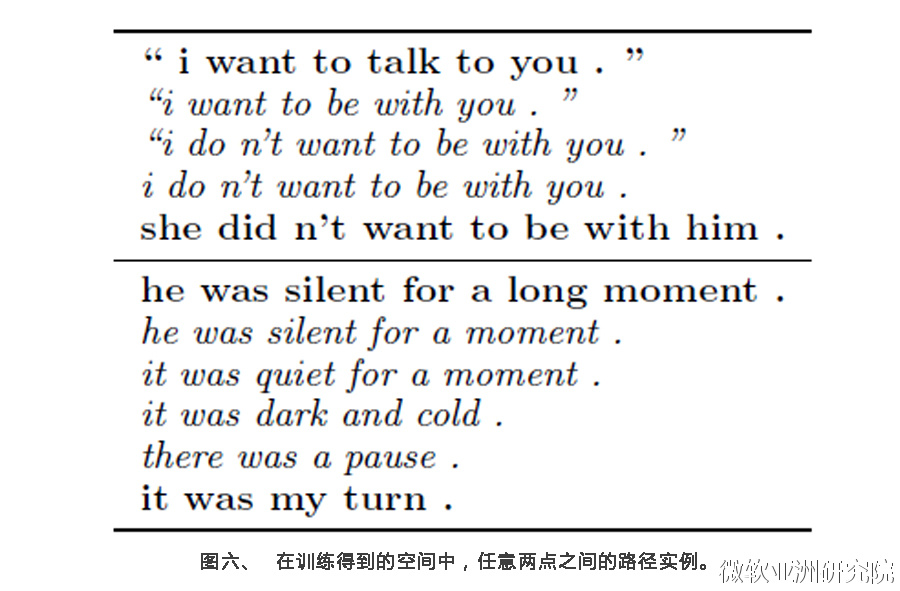
得到这样的结果实属不易。在文章的一开始,作者就给出了一个例子,来说明传统的自动解码并不能很好地编码完整的句子。如图七所示,从句子“i went to the store to buy some groceries”到句子“horses are my favorite animals”,中间取的点经过解码得到的句子呈现在它们之间。可以发现,这些句子未必是符合语法的英文句子。与之相比,图六呈现的句子质量要好很多,不仅语法正确,主题和句法也一致。

这篇文章的想法非常有意思,他们想使用VAE(varationalautoencoder的简称)学习到一个更连续的句子空间。如图八所示,作者使用了单层的LSTM 模型作为encoder(编码器)和decoder(解码器),并使用高斯先验作为regularizer(正规化项),形成一个序列的自动编码器。比起一般的编码解码框架得到的句子编码往往只会记住一些孤立的点,VAE框架学到的可以想象成是一个椭圆形区域,这样可以更好地充满整个空间。我的理解是,VAE框架将贝叶斯理论与深度神经网络相结合,在优化生成下一个词的目标的同时,也优化了跟先验有关的一些目标(例如KL cost和crossentropy两项,细节请参考论文),使对一个整句的表达更好。
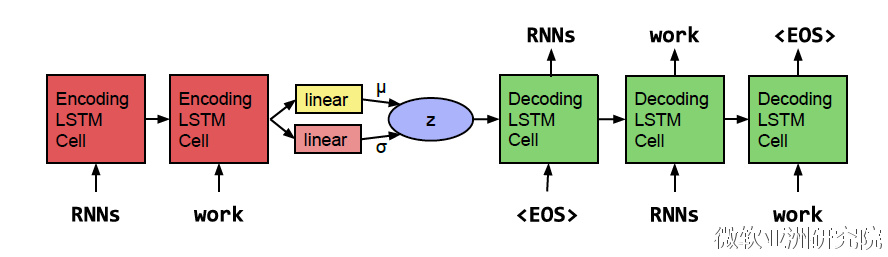
当然,为了实现这一想法,作者做了很多尝试。首先,对图八所展示的结构做一些变形并没有带来明显的区别。但在优化时,使用退火的技巧来降低KL cost和训练时把适当比例的词变为未知词(即word dropout)这两项技术就非常有效。
作者们通过两个有意思的实验来展示了他们的结果。一个是做填空题,如图九所示,隐藏句子的后20%,让模型来生成后面的部分。从几个例子看,VAE的方法比RNN语言模型(简称RNNLM)更加通顺和有信息量。第二个实验就是在两个句子之间做轮移(Homotopy,也就是线性插值),对比图六和图七,可以看出VAE给出的句子更平滑而且正确,这一点可以间接说明学习到的句子空间更好地被充满。

当然,作者们还给出了一些定量的比较结果。在比较填空结果时,他们使用了adversarial evaluation(对抗评价)。具体的做法是,他们取样50%的完整句子作为正例,再拿50%的由模型填空完成的句子作为负例。然后训练一个分类器,如果一个模型填的越难与正例分开,就说明这种模型的生成效果更好,更具欺骗性。因此,可以认为这一模型在填空任务上更出色。实验的结果也支持VAE比RNNLM更好。
问题与难点
人工智能真的会创作吗?使用深度学习技术写出的文章或者对话,的确是会出现训练集合里未见过的句子。例如,一个原句的前半段可能会跟上另一个原句的后半段;也可能除了词,搭配组合都是训练集里没有的。这看起来有些创作的意味,但是细究起来,往往是原句的部分更为通顺和有意义。目前的技术可以拼凑,偶尔出现一两个好玩的点,但是写得长了,读起来会觉得没头没脑,这是因为没有统领全篇的精神,跟人类的作家比当然还是相差很远。
机器学习到的还只是文字表面,没有具备人要写文章的内在动因。人写文章表达的是自己的思想和感受,这是机器所没有的。因此,即使是机器写文章,具体想要表达什么,似乎还要由人来控制。但如果控制得太多,看起来又不那么智能,少了些趣味。我认为,要想让机器更自由地写出合乎逻辑的话来,我们还需要类似VAE那篇文章一样更深入的研究,对句子甚至段落的内在逻辑进行学习。
另外,人在写一篇文章的时候,很容易自我衡量语句是否通顺、思想是否表达清楚以及文章的结构是否清晰有趣,机器却很难做到。因此,优化的目标很难与真正的质量相一致。目前的自然语言理解技术对于判断句法语法是否正确可能还有些办法,但要想判断内容和逻辑上是否顺畅,恐怕还需要常识和推理的帮助,这些部分暂时还比较薄弱。但也并非毫无办法,我相信未来对文本生成的研究一定会涉及这些方面。
期待更多的人来研究如此好玩的文本生成。
参考文献
【1】http://www.csail.mit.edu/deepdrumpf
【2】http://kotoba.nuee.nagoya-u.ac.jp/sc/gw/doc/20160321f.pdf
【3】https://www.theguardian.com/technology/2016/may/17/googles-ai-write-poetry-stark-dramatic-vogons
【4】http://www.androidauthority.com/google-ai-poetry-692231/
【5】http://karpathy.github.io/2015/05/21/rnn-effectiveness/
【6】https://github.com/karpathy/char-rnn
【7】http://colah.github.io/posts/2015-08-Understanding-LSTMs/
【8】刘挺,人机对话浪潮:语音助手、聊天机器人、机器伴侣,中国计算机学会通讯,2015年第10期,2015
【9】Lifeng Shang, Zhengdong Lu, Hang Li. Neural Responding Machine for Short Text Conversation. Proceedings of the 53th Annual Meeting of Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP'15), 1577-1586, 2015.
【10】http://ntcir12.noahlab.com.hk/stc.htm
【11】http://ntcirstc.noahlab.com.hk/STC2/stc-cn.htm
【12】http://research.nii.ac.jp/ntcir/ntcir-13/howto.html
【13】Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, Andrew M. Dai, Rafal Jozefowicz, Samy Bengio. Generating Sentences from a Continuous Space. arXiv preprint, arXiv:1511.06349, 2015.
作者简介

宋睿华博士现任微软亚洲研究院主管研究员,从事信息检索、数据挖掘和人工智能方面的研究。她的研究兴趣包括互联网搜索与评价、数据抽取和挖掘、社交和移动数据挖掘、以及基于人工智能技术的文本生成。近期特别对个性化文本对话以及人工智能写作感兴趣。宋睿华博士在国内外顶级会议和杂志上发表论文40余篇,并曾任SIGIR、SIGKDD、CIKM、WWW、WSDM等国际会议和TKDE、TOIS、Information Retrieval等国际杂志的评审委员。她是EVIA2013和2014的主席。她还提出并组织了NTCIR Intent tasks。
宋睿华于2000年和2003年在清华计算接科学与技术系获得学士和硕士学位。之后,加入微软亚洲研究院工作至今。工作的同时,她于2010年取得了上海交通大学计算机系博士学位。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

