Quartz 入门详解
入门简介:
基本上任何公司都会用到调度这个功能, 比如我们公司需要定期执行调度生成报表, 或者比如博客什么的定时更新之类的,都可以靠Quartz来完成。正如官网所说,小到独立应用大到大型电子商务网站, Quartz都能胜任。
Quartz体系结构:
明白Quartz怎么用,首先要了解Scheduler(调度器)、Job(任务)和Trigger(触发器)这3个核心的概念。
1. Job: 是一个接口,只定义一个方法execute(JobExecutionContext context),在实现接口的execute方法中编写所需要定时执行的Job(任务), JobExecutionContext类提供了调度应用的一些信息。Job运行时的信息保存在JobDataMap实例中;
2. JobDetail: Quartz每次调度Job时, 都重新创建一个Job实例, 所以它不直接接受一个Job的实例,相反它接收一个Job实现类(JobDetail:描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息),以便运行时通过newInstance()的反射机制实例化Job。
3. Trigger: 是一个类,描述触发Job执行的时间触发规则。主要有SimpleTrigger和CronTrigger这两个子类。当且仅当需调度一次或者以固定时间间隔周期执行调度,SimpleTrigger是最适合的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如工作日周一到周五的15:00~16:00执行调度等;
Cron表达式的格式:秒 分 时 日 月 周 年(可选)。
字段名 允许的值 允许的特殊字符
秒 0-59 , – * /
分 0-59 , – * /
小时 0-23 , – * /
日 1-31 , – * ? / L W C
月 1-12 or JAN-DEC , – * /
周几 1-7 or SUN-SAT , – * ? / L C # MON FRI
年 (可选字段) empty, 1970-2099 , – * /
“?”字符:表示不确定的值
“,”字符:指定数个值
“-”字符:指定一个值的范围
“/”字符:指定一个值的增加幅度。n/m表示从n开始,每次增加m
“L”字符:用在日表示一个月中的最后一天,用在周表示该月最后一个星期X
“W”字符:指定离给定日期最近的工作日(周一到周五)
“#”字符:表示该月第几个周X。6#3表示该月第3个周五
Cron表达式范例:
每隔5秒执行一次:*/5 * * * * ?
每隔1分钟执行一次:0 */1 * * * ?
每天23点执行一次:0 0 23 * * ?
每天凌晨1点执行一次:0 0 1 * * ?
每月1号凌晨1点执行一次:0 0 1 1 * ?
每月最后一天23点执行一次:0 0 23 L * ?
每周星期天凌晨1点实行一次:0 0 1 ? * L
在26分、29分、33分执行一次:0 26,29,33 * * * ?
每天的0点、13点、18点、21点都执行一次:0 0 0,13,18,21 * * ?
4. Calendar:org.quartz.Calendar和java.util.Calendar不同, 它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。 一个Trigger可以和多个Calendar关联, 以便排除或包含某些时间点。
假设,我们安排每周星期一早上10:00执行任务,但是如果碰到法定的节日,任务则不执行,这时就需要在Trigger触发机制的基础上使用Calendar进行定点排除。针对不同时间段类型,Quartz在org.quartz.impl.calendar包下提供了若干个Calendar的实现类,如AnnualCalendar、MonthlyCalendar、WeeklyCalendar分别针对每年、每月和每周进行定义;
5. Scheduler: 代表一个Quartz的独立运行容器, Trigger和JobDetail可以注册到Scheduler中, 两者在Scheduler中拥有各自的组及名称, 组及名称是Scheduler查找定位容器中某一对象的依据, Trigger的组及名称必须唯一, JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法, 允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
Scheduler可以将Trigger绑定到某一JobDetail中, 这样当Trigger触发时, 对应的Job就被执行。一个Job可以对应多个Trigger, 但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供了多个put()和getXxx()的方法。可以通过Scheduler# getContext()获取对应的SchedulerContext实例;
6. ThreadPool: Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
Job有一个StatefulJob子接口,代表有状态的任务,该接口是一个没有方法的标签接口,其目的是让Quartz知道任务的类型,以便采用不同的执行方案。无状态任务在执行时拥有自己的JobDataMap拷贝,对JobDataMap的更改不会影响下次的执行。而有状态任务共享共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改会保存下来,后面的执行可以看到这个更改,也即每次执行任务后都会对后面的执行发生影响。
正因为这个原因,无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行,这意味着如果前次的StatefulJob还没有执行完毕,下一次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往拥有更高的复杂度,因此除非必要,应该尽量使用无状态的Job。
如果Quartz使用了数据库持久化任务调度信息,无状态的JobDataMap仅会在Scheduler注册任务时保持一次,而有状态任务对应的JobDataMap在每次执行任务后都会进行保存。
Trigger自身也可以拥有一个JobDataMap,其关联的Job可以通过JobExecutionContext#getTrigger().getJobDataMap()获取Trigger中的JobDataMap。不管是有状态还是无状态的任务,在任务执行期间对Trigger的JobDataMap所做的更改都不会进行持久,也即不会对下次的执行产生影响。
Quartz拥有完善的事件和监听体系,大部分组件都拥有事件,如任务执行前事件、任务执行后事件、触发器触发前事件、触发后事件、调度器开始事件、关闭事件等等,可以注册相应的监听器处理感兴趣的事件。
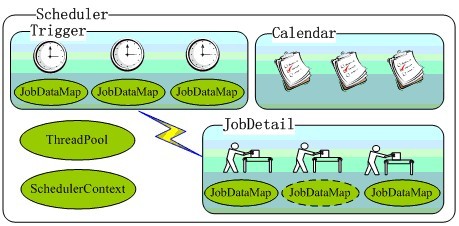
下图描述了Scheduler的内部组件结构,SchedulerContext提供Scheduler全局可见的上下文信息,每一个任务都对应一个JobDataMap,虚线表达的JobDataMap表示对应有状态的任务:
废话不多说, 上代码:
1. 最简单的Job代码(就打印Hello Quartz !):
package com.wenniuwuren.quartz;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class HelloQuartz implements Job {
public void execute(JobExecutionContext arg0) throws JobExecutionException {
System.out.println("Hello Quartz !");
}
}
2. 设置触发器
package com.wenniuwuren.quartz;
import org.quartz.CronScheduleBuilder;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
public class SchedulerTest {
public static void main(String[] args) throws InterruptedException {
//通过schedulerFactory获取一个调度器
SchedulerFactory schedulerfactory = new StdSchedulerFactory();
Scheduler scheduler=null;
try{
// 通过schedulerFactory获取一个调度器
scheduler = schedulerfactory.getScheduler();
// 创建jobDetail实例,绑定Job实现类
// 指明job的名称,所在组的名称,以及绑定job类
JobDetail job = JobBuilder.newJob(HelloQuartz.class).withIdentity("JobName", "JobGroupName").build();
// 定义调度触发规则
// SimpleTrigger
// Trigger trigger=TriggerBuilder.newTrigger().withIdentity("SimpleTrigger", "SimpleTriggerGroup")
// .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(3).withRepeatCount(6))
// .startNow().build();
// corn表达式 每五秒执行一次
Trigger trigger=TriggerBuilder.newTrigger().withIdentity("CronTrigger1", "CronTriggerGroup")
.withSchedule(CronScheduleBuilder.cronSchedule("*/5 * * * * ?"))
.startNow().build();
// 把作业和触发器注册到任务调度中
scheduler.scheduleJob(job, trigger);
// 启动调度
scheduler.start();
Thread.sleep(10000);
// 停止调度
scheduler.shutdown();
}catch(SchedulerException e){
e.printStackTrace();
}
}
}
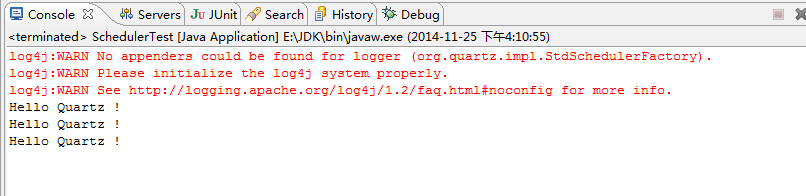
输出(设置了sleep10秒, 故在0秒调度一次, 5秒一次, 10秒最后一次):
正文到此结束
- 本文标签: tar IDE src JobDetail 调度器 数据 build 任务调度 StdSchedulerFactory servlet UI 实例 Quartz CronTrigger java map HTML ACE SimpleTrigger 网站 CTO 凌晨 JobExecutionException id cat 时间 博客 JobDataMap IO 线程 代码 http trigger 监听器 数据库 电子商务 entity Job 线程池
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

