深度学习在文本简化方面有什么最新应用进展?
雷锋网按:本文作者谭继伟、姚金戈,均为北京大学计算机科学与技术研究所在读博士生,研究方向主要包括文本信息推荐与自动摘要。
背景与介绍
近年来,机器翻译任务依靠深度学习技术取得了重大突破。最先进的神经机器翻译模型已经能够在多种语言上超越传统统计机器翻译模型的性能。在传统统计机器翻译模型上积累深厚的谷歌,也终于开始将最新的神经机器翻译系统逐步上线。
目前神经机器翻译的技术基础是端到端的编码器-解码器架构,以源语言句子作为输入,目标语言同义句作为输出。容易想象,只要具备充足的训练数据,类似架构完全有可能推广到其他涉及文本改写的任务上。例如,输入一段文字,希望系统输出一小段核心语义不变、但更为简洁的表达。这样的改写统称为 文本简化 (text simplification)。
近两年深度学习技术应用相对较多的是其中的一个实例,在自然语言生成研究中一般称为 语句压缩 (sentence compression)或 语句简化 (sentence simplification),即输入和输出均为语句。 语句简化任务要求神经网络结构能够编码输入句中的核心语义信息,才能够提炼出不改变原句主要意义的更简洁表达 。
深度学习技术在语句简化上的一个典型应用是 新闻标题生成 (headline generation)。新闻文章通常具有较为规范的写作形式:文章首句或者首段对新闻内容进行概括介绍,新闻标题则进一步精炼概括出新闻核心事件。目前基于深度学习技术的新闻标题生成研究中,一般以新闻文章的首句作为输入,生成该新闻文章的标题。现有的基于深度学习的新闻标题生成工作通常采用和神经机器翻译类似的编码器-解码器架构,一般不需要手动提取特征或语句改写文法。 最常见的仍然是序列到序列 (sequence-to-sequence, 简记为seq2seq)模型。典型的序列到序列模型如图1所示。
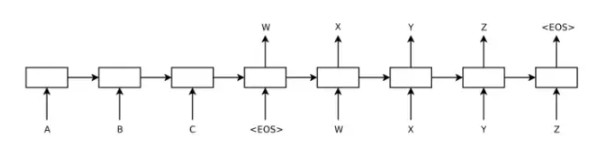
图1 典型的序列到序列生成模型 (Sutskever et al., 2014)
在图1中,以文本序列A-B-C-<EOS>输入给一个编码器,编码器用于将输入文本编码成一个语义向量表达(图中对应第四个节点处的隐状态)。输入序列的语义向量表达进而交由解码器用于目标文本序列W-X-Y-Z-<EOS>的生成。这里的<EOS>表示序列结束符号(end of sequence),标志着输入序列或输出序列的结束。解码器接收<EOS>符号后,开始解码的过程,直到生成<EOS>符号标志着解码过程的结束。
序列到序列模型是一个按照字符(或单词)序列逐个处理的过程,编码过程中编码器逐个接收输入字符,解码过程中解码器逐个输出生成的字符。在最原始的模型训练过程中,解码器每次接收答案序列中的一个字符(例:W),预测应该输出的下一个字符(例:X)。编码器-解码器架构的经典训练目标,是在给定编码器输入后,使解码器输出的结果能够最大程度地拟合训练集中的答案,在概率模型下即最大化数据似然。
在模型预测阶段,答案序列未知,解码器接收<EOS>作为解码开始符,并生成一个输出字符,然后将模型预测出的输出字符作为解码器的下一个输入,重复这个过程直到解码器生成<EOS>符号为止。预测阶段的一般目标是,给定输入句编码后,根据当前模型选择概率最大的解码器输出结果。精确搜索这个最优解一般复杂度极高,所以在实际应用中解码过程通常应用 集束搜索 (beam search,也可译作柱搜索)近似求解:在每一步保留K个最高得分的输出,最后从K个输出结果中选择得分最高的作为最终的输出。
这样的编码器-解码器模型一般可以处理变长的输入和输出序列,使得它可以被应用于多种文本改写任务上。形式上,给定一个包含M个词的输入文本序列x={x1,x2,…,xM},在模型中将每个词xt表示成一个向量。词的向量表示会在模型中进行学习,可以用无监督训练得到的一般word embedding向量作为初始化。语句简化的目标是生成输入句x的一个简化y={y1,y2,…,yN},一般要求y的长度比输入句更短,即N<M。标题生成的目标是寻找y ̂使得给定x的条件下y的条件概率最大化,即:y ̂=argmaxy〖P(y|x;θ)〗 ,其中θ代表需要学习的模型参数。条件概率P(y|x;θ)可以由链式法则分解为:
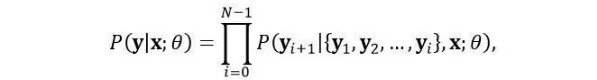
编码器一般能够处理长度不确定的输入文本序列,将每个词的词向量表示汇总,编码成一个定长的输入文本向量表示。这个编码过程可以采用不同的编码器,如卷积神经网络(CNN),循环神经网络(RNN)等。而解码的过程是根据输入文本序列生成输出文本序列的过程,在大多数模型中,解码器使用的是RNN,常用的RNN节点包括标准的RNN单元以及像LSTM、GRU这样记忆能力更强的带门限单元等。
RNN对序列中的每一个单元执行相同的运算过程,从而可以接受任意长的序列作为输入。具体来说,一个标准的RNN以及其按照输入序列展开形式如图2所示。
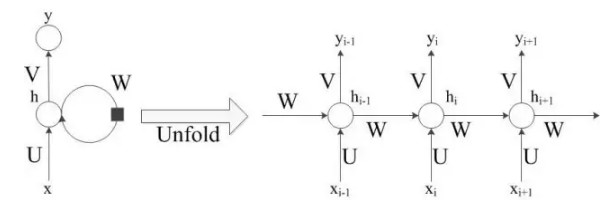
图2 标准RNN及其展开形式
在图2中,xi是第i个输入词语,hi是接收xi之后RNN隐单元的状态。hi+1基于前一个隐状态hi和当前的输入xi+1得到,即hi+1=f(Uxi+1+whi)。f是非线性函数,如tanh或者sigmoid。标准的RNN单元在每一步输出yi+1=g(Vhi+1),g是非线性函数。
在序列到序列模型中,如果选用RNN作为编码器,这一部分RNN的输出(yi)一般被忽略;而RNN作为解码器时,每一步输出yi+1对应规模为V的词表上所有词语的概率分布(通常选用softmax函数将V维得分向量标准化得到),产生yi+1的过程依赖于前一步状态hi以及前一步的输出yi。
解码过程中,生成单词yi+1的方法是 :
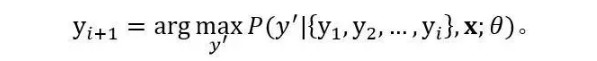
早期的编码器-解码器模型中,要求编码器结构的最后一个单元能很好地保留输入文本的信息编码。而在实际应用中,这样的定长文本编码并不一定能够捕捉输入句的所有重要信息,尤其是在输入文本较长的情况下。为解决这个问题,有研究工作(Bahdanau et al., 2015)在序列到序列神经机器翻译模型中引入了“注意力”(attention)机制,用于在生成目标文本序列的过程中,为生成每个目标词确定一个有注意力偏差的输入文本编码,使得模型可以学习输出序列到输入序列的一个软对齐(soft alignment)。
注意力机制的主要思想是:在每一步生成不同的yi+1时,侧重使用编码器中对应x的不同部分的隐状态信息,即使用编码器中各隐状态ht的加权和作为生成时所需要考虑的“上下文 ”:
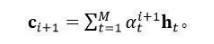
通过为生成不同的目标单词学习不同的
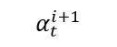
分布,使得生成不同单词时解码器可以将“注意力”集中在不同的输入词语上。注意力权值
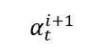
可以有多种不同的计算方法,一种常见的实现方法考虑编码器每个隐状态ht和解码器生成词语yi+1时的隐状态hyi+1的相近程度(内积),将权值定义为:
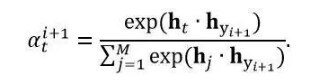
初探与进展
基于编码器-解码器架构和注意力机制的序列到序列学习模型最初用于神经机器翻译,但原理上可以直接照搬应用于 标题生成 (Lopyrev, 2015; Hu et al., 2015)。甚至不采用注意力机制的多层LSTM-RNN编码器-解码器也在一般基于词汇删除的语句压缩任务上取得了一定效果(Filippova et al., 2015)。
而神经网络方法在语句简化、标题生成任务上最早的应用中,比较著名的当属Sasha Rush组的相关工作(Rush et al., 2015)。虽然同样是一种编码器-解码器神经网络,但在具体的架构设计上和基于RNN的序列到序列学习有一定差异。
这个工作中对P(y│x;θ)应用了C阶马尔科夫假设,即生成一个新的词语yi+1时只依赖于之前C个已经生成的词语yc=y[i-C+1,…,i],同时对P(y│x;θ)求对数将其分解为求和形式:
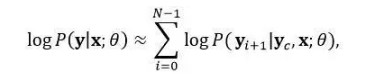
局部概率P(yi+1|yc,x;θ)定义为一个前馈神经网络:
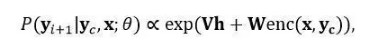
其中隐状态h由上下文yc的嵌入表示y ̃c通过一层变换得到:
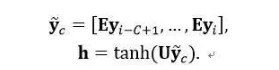
而enc是以x作为输入的编码器模块。文中尝试了三种不同的编码器,分别为词袋模型编码器enc1、卷积编码器enc2和注意力机制的编码器enc3。整个模型架构比较简单,如图3(a)所示。
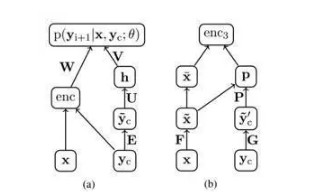
图3 ABS模型和注意力机制编码器 (Rush et al., 2015)
词袋模型编码器和卷积编码器不考虑注意力机制。词袋模型enc1定义为词向量的简单平均。记每个输入词xi为one-hot表示,左乘词向量编码矩阵F可以得到其对应的word embedding,整个词袋模型编码器可以写作:
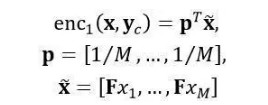
其中p∈[0,1]M是输入词语上的均匀分布,词袋模型编码器要学习的参数只有词向量编码矩阵F。这个编码器忽略输入词语序列的顺序和相邻词之间的关系。
卷积编码器enc2对词袋模型编码器不考虑词语之间关系的特点进行了改进,采用了一种标准的时延神经网络(time-delay neural network, TDNN),使得编码器可以利用词语之间的局部关系。这个编码器包含L层,每层主要由1维的卷积过滤器Q和max-pooling操作构成:
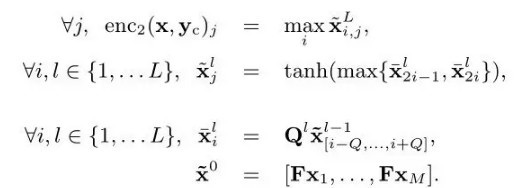
而enc3将注意力机制引入到词袋模型编码器中,使得enc3对x进行编码的过程中利用到之前C个已经生成的词语作为上下文yc。用G表示上下文编码矩阵,模型结构如图3(b)所示,形式上写作:
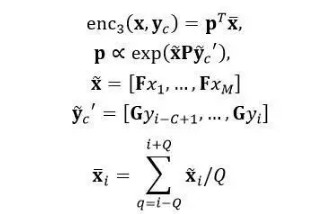
模型训练使用批量随机梯度法最小化训练数据
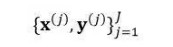
负对数似然:
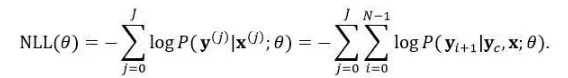
使用动态规划(Viterbi算法)精确求解这个问题的时间复杂度为O(NVC),而词汇表大小V一般较大。前文已经提到,实际应用中一般可以采用集束搜索近似求解,即在生成每一个yi的时候都只保存当前最优的K个部分解,之后仅从这K个部分解开始进行下一步生成。这样时间复杂度被降为O(KNV)。
直觉上,人工语句简化时一般仍会保留一些原句中的词汇。一个好的语句压缩模型最好既能够逐个从词汇表V生成目标压缩句中的词汇,又能够捕捉从原句中进行词汇抽取的过程。文中(Rush et al., 2015)给出了一个权衡“生成”和“抽取”的初步方案,称为抽取式调节(extractive tuning)。本质上就是经典统计机器翻译中的对数线性模型(Och and Ney, 2002),通过线性加权将多个特征组合起来定义概率:
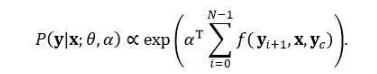
其中α为5维权向量,对应的5维特征f包括之前模型的概率估计,以及四个和输入句有关的示性函数特征(和输入句存在一元词、二元词、三元词匹配或调序):

这样的分数定义在形式上仍然根据每一步i来分解,所以不需要修改使用动态规划或者柱搜索进行解码的过程。而调节权向量α的过程也可以像经典统计机器翻译一样采用最小错误率训练(minimum error rate training, MERT)(Och, 2003)来完成。
这个工作完成时间相对较早,并没有使用最适合对序列数据建模的RNN结构。同研究组今年的后续工作(Chopra et al., 2016)中,将解码器由前馈神经网络替换为RNN,并改变了编码器结构:同时为输入词及其所在位置学习embedding,并用卷积计算当前位置上下文表示,作为解码过程中注意力权重计算的依据。最后得到的架构中不再需要前文所述的“抽取式调节”模块,成为更纯粹的端到端系统;在Gigaword数据集上的实验结果也取得了更优的性能。
基于神经网络的语句简化与标题生成后续也在不同方面取得进展。目前生成类任务训练指标主要为训练集数据的似然函数,但生成类任务的常用自动评价准则是ROUGE或BLEU,本质上大约相当于系统生成结果和参考答案之间关于n-gram(连续若干个词)的匹配程度。
近期有工作尝试利用最小化风险训练(minimum risk training, MRT)思想(Och, 2003; Smith and Eisner, 2006)改进神经机器翻译,直接对BLEU值进行优化。这一策略在标题生成任务上也同样适用,只需用类似的方式去优化训练集生成结果的ROUGE值(Ayana et al., 2016)。具体而言,用∆(y',y)表示任务相关的实际损失函数,如标题生成任务中将其设为生成结果y'在参考答案y上计算的ROUGE值(这里表达为风险最小化问题,所以还需要取负)。训练目标是最小化期望风险:
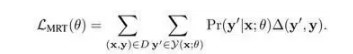
最小化期望风险的一个好处在于: 即使原本损失函数∆(y',y)是定义在离散结构上的离散函数,训练目标关于概率模型的参数也还是连续函数,所以仍然可以求导进行反向传播更新参数 。然而,穷举所有可能产生的结果y’开销过大,并不可行。所以只在上面取一个显著抽样S(x;θ)来近似整个概率分布,并引入一个较小的超参数ϵ尝试让近似分布更为平滑:
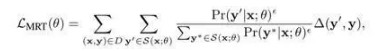
实际上,如果固定超参数ϵ为1,这一近似计算最小化期望风险的做法就和强化学习早期工作中的REINFORCE算法(Williams, 1992)不谋而合。近期也有工作从REINFORCE算法出发,对随机初始化概率模型的做法进行改进,提出首先根据正确答案用交叉熵损失学习若干轮、得到较好的初始概率模型,然后利用退火机制逐步将训练过程转向REINFORCE算法(Ranzato et al., 2016)。实验表明,这些对训练目标的改进都可以显著改善自动评价指标所度量的性能。
另一方面, 原句中可能存在模型词汇表中所没有的词(out of vocabulary, OOV),尤其是很多专有名词,并不在生成词汇的范围V之中 。实现上为了降低解码复杂度,一般都会采用相对较小的词汇表。如果系统不能输出原句中的OOV词、仅能用<UNK>等占位符代替,显然有可能会造成关键信息损失。
受指针网(pointer networks,一种输出序列中每个元素分别指向输入序列中元素的编码器-解码器网络)(Vinyals et al., 2015)启发,近期已有多个工作都不约而同地考虑了一种解决思路:在解码的过程中以一部分概率根据当前状态来生成、一部分概率直接从原句中抽取(Gu et al., 2016; Gulcehre et al., 2016; Nallapati et al., 2016)。
另一方面, 如何利用其它任务数据作为辅助性监督信息也是一个正在被考虑的方向 。例如今年有工作在同一个多层双向RNN网络中进行语句压缩、阅读视线预测(gaze prediction)、组合范畴文法(combinatory category grammar, CCG)超标注(supertagging)的多任务学习,使得语句压缩任务的性能得到改善(Klerke et al., 2016)。这几个任务在直觉上具有一定相关性,有机会起到相互强化的效果。
上面所介绍的架构都属于直接对条件概率P(y│x;θ)建模的判别式模型范畴。近期也有 利用深层产生式模型来对语句压缩任务建模 的工作。常见神经网络结构中,自编码器被广泛应用于表示学习和降维,将类似思想对文本数据建模自然也可能学习到更紧凑的表示。最近就有尝试在变分自编码器(variational auto-encoder, VAE)架构下得到语句压缩模型的工作(Miao and Blunsom, 2016)。关于一般VAE模型的详细信息本文不予赘述,感兴趣的读者可参考相关教程 (Doersch 2016)。原始的VAE可以将输入数据压缩到低维表示,而这个工作类比提出将输入的长句压缩为更紧凑的短句,得到如图4所示的自编码压缩模型。
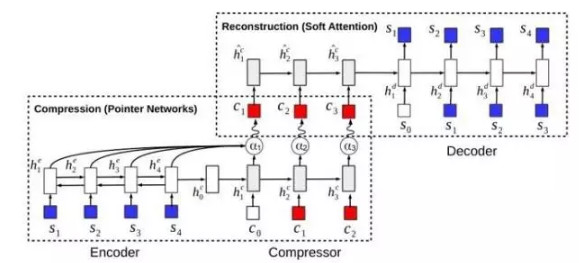
图4 自编码语句压缩模型
用s和c分别记原始输入句和压缩句,整个模型包含两部分:
-
(1) 压缩模型(图4左下部分虚线框,由编码器连接压缩器组成)为以s作输入、c作输出的推断网络qφ (c│s)
-
(2) 重构模型(图4右上部分虚线框,由压缩器连接解码器组成)为基于压缩表示c重构原始输入句s的生成网络pθ (s│c)。
为了让压缩句中仅使用原句中出现过的词,文中选用了指针网(Vinyals et al., 2015)作为压缩模型qφ (c│s),同时将编码器设计为双向LSTM-RNN,压缩器使用带有注意机制的单向LSTM-RNN。而重构模型pθ (s│c)则直接使用经典的序列到序列结构,即带注意机制的RNN,以压缩器端的c作输入,从解码器端产生原句s。
模型训练过程中需要对两组网络参数φ和θ进行更新。与最原始的VAE一样,只需要无标记数据作为输入,使用变分推断来优化数据对数似然的一个下界L:
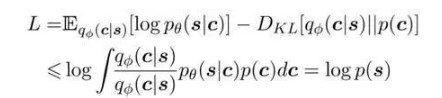
其中需要计算变分分布qφ (c│s)和一个先验语言模型p(c)的KL散度。本文讨论的任务是语句压缩,需要同时保证压缩句尽可能流畅和简洁,所以预训练了一个偏好短句的语言模型作为p(c)。
由于不易对从变分分布q中随机产生的值进行反向传播,原始VAE推断过程使用重参数化(reparameterization)技巧,将产生样本的随机性全部转移到一个辅助的噪声随机变量中,保持和参数直接相关的部分相对固定,从而可以通过对这些非随机部分求导进行反向传播参数更新。但自编码语句压缩模型处理对象为离散结构的文本,重参数化技巧不能直接使用。因此文中使用了前面提到的REINFORCE算法,根据一组随机采样的误差进行反向传播,近似最小化期望损失,并引入偏置项来降低梯度估计的方差。
VAE变分推断进行模型训练的效率十分依赖推断网络q(对应这个工作中的压缩模型部分)的梯度估计质量。为了在训练过程初期就能引导压缩模型产生较好的压缩结果,文中进一步提出另一个模型,称为强制注意力语句压缩(forced-attention sentence compression;图5),强制让注意力的学习和额外的有标记语句压缩数据更吻合。本质上是通过有监督训练来实现前面提到的一种语句简化策略:以一部分概率根据指针网直接从原句中抽词(对应图5中的α)、一部分概率根据当前状态来生成整个词汇表V中可能的词(对应图5中的β)。这样就可以引入语句简化任务的有标记平行语料,进行半监督学习。
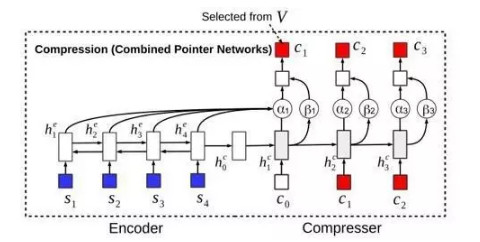
图5 强制注意力语句压缩
局限与展望
需要指出的是, 对于 任何涉及自然语言生成的任务而言,像ROUGE、BLEU那样基于局部单元匹配的自动指标并不能完全取代基于语义理解的人工评价 。目前基于神经网络的相关工作几乎全部缺少人工对语义完整性、流畅度等关键指标的评分(这一点在相关论文的审稿环节理应有人指出;也有可能竞标这类论文的审稿人主要来自对神经网络了解甚于自然语言生成的研究人员)。所以不同方法的实际性能差异究竟有多少,其实尚不明确。
细心的读者可能已经注意到,虽然本文介绍的相关文献标题中有些包含“语句摘要(sentence summarization)”甚至“文本摘要(text summarization)”这样的字眼,但我们在本文的描述中尚未开始使用“摘要”一词。因为目前提出的方法大多仅能够应用于将一两句话作为输入的情形,实际上只是语句级别的压缩或简化。
语句简化的最终目标仍然还是对更大范围内的信息摘要,比如用几句话去概况整篇文档中的主要内容。目前的神经网络方法大多以短文本(如句子、微博)作为输入,鲜有直接对文档结构进行编码的架构,最终解码也只能得到标题长度的信息,尚不足以作为整篇文档的内容总结。对于自动标题生成而言,是否只需要去利用每篇文档最开始一两句话中的信息,也仍有待商榷;这个问题在非新闻语料上可能更为明显。另一方面,对本身已经较短的文本再做进一步简化的实用价值,可能也无法和文档信息摘要相提并论。
关于文档摘要任务, 现有的基于神经网络的模型仍以抽取式摘要 (即从输入文档中直接抽取若干关键句作为摘要) 居多 ,此时神经网络模型起到的作用也仅限于对文档中每个句子进行估分、排序,这和从文档到摘要进行端到端训练、直接逐词“生成”摘要的理想目标仍有距离。经典序列到序列架构在语句简化、标题生成任务可以取得不错的效果,但在文档摘要任务上还没有出现较为成功的应用。一个可能的原因在于整篇文档篇幅过长,不适合直接套用经典序列架构来编码和解码。
因此,对句子和词进行分级层次化编码(Li et al., 2015)可能是一种可以尝试的路线。今年提出的一种端到端神经摘要模型(Cheng and Lapata, 2016)中,将文档视为语句的序列,用各语句的编码作为编码器RNN中每个单元的输入,而语句的编码由一个CNN通过卷积和池化操作将词汇级信息汇总得到(图6)。
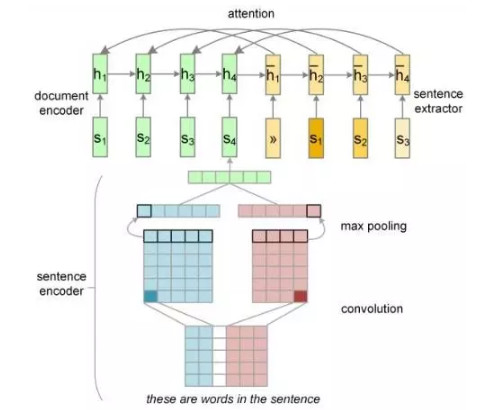
图6 CNN句子编码作为序列到序列模型输入(Cheng and Lapata, 2016)
这样可以直接实现句子级抽取,比如文中的做法是用一个多层感知机根据当前状态来估计是否抽取该句的概率(pt-1表示前一句应当被抽取的概率):
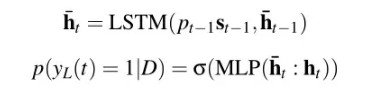
为了进一步能够通过原文词汇重组构建和生成“非抽取式”摘要,文中提出一种层次化注意力架构,利用句子级的注意力权值作为输入来计算句子中每一个词的注意力权值。

图7 词汇级抽取(Cheng and Lapata, 2016)
这个工作在句子抽取上能取得一定效果,但词汇级生成摘要仍有待提高,不论在自动评价和人工评价结果上都还不够理想。
而另一个侧重于标题生成的工作(Nallapati et al., 2016)中也提出了一种层次化编码思想:使用两级双向RNN分别刻画词和句子的序列结构,解码过程计算每个词的注意力权值时,用所在句子的注意力权值予以加权(reweight)。但很遗憾这样的设计暂时也并没有使得生成多句摘要的任务得到性能上的提升。
总而言之, 目前的编码器-解码器架构在短文本简化任务上取得了一定进展 。现在应用于文本简化的编码器-解码器架构设计也比较多样,可以为各种不同需求下文本简化的后续研究工作提供多种可能的参考思路。然而,深度学习方法在文档摘要任务上仍存在巨大的提升空间。如果期望使用完全端到端的方式训练文档级摘要模型,可能还需要在编码器和解码器的设计上产生一些新的突破,使得模型可以更好地表示和生成结构性更明显、篇幅更长的内容。
雷锋网注:本文由深度学习大讲堂授权雷锋网 (公众号:雷锋网) 发布,如需转载请注明作者和出处,不得删减内容。
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

