谈一谈复杂的正则表达式分析
PHPMailer里面对于Email的正则表达式让很多人看了头疼,其实我看了也头疼,但借助一些工具,加上一些经验,还是能慢慢把有效信息剥离出来的。
首先推荐一个分析正则表达式的网站 https://regex101.com/ 。之前的很多网站,遇到今天这个正则表达式就都蔫儿了,实际上正则表达式的语法也不尽相同,比如PHP的正则和JavaScript就有区别,所以一定要找对正则表达式分析引擎。
regex101就可以选择多个正则表达式引擎,我这里选择pcre(php): https://regex101.com/r/aGGWWw/2
这个网站的诸多好处,自己使用去体会吧。
我们首先输入我们需要分析的正则表达式,然后慢慢分析。
(?1) 的分析
这个正则表达式看似很长很乱,其实主要用到的也就是下面三种语法:
(?!xxx) 断言,匹配后面不是xxx的位置
(?>xxx) 一次性子组 ,见 http://php.net/manual/zh/regexp.reference.onlyonce.php
(?n) 子匹配,等同于第n组正则
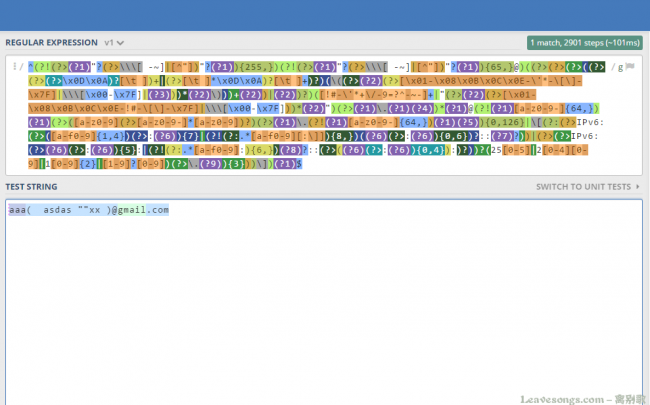
先来分析第一个子组,第一个子组在这里:
你说为什么不从头开始分析?因为前面有多处用到 (?1) ,如果不分析第一个组,前面的正则是看不懂的。
(?1) 又分为两部分:
-
((?>(?>(?>/x0D/x0A)?[/t ])+|(?>[/t ]*/x0D/x0A)?[/t ]+)?) -
(/((?>(?2)(?>[/x01-/x08/x0B/x0C/x0E-/'*-/[/]-/x7F]|///[/x00-/x7F]|(?3)))*(?2)/))
其实这两部分也就是第2/3组,这也是为什么regex101右侧边栏中没有2/3组的原因,因为2/3组是包含在第1组中的。
第2组主要匹配了换行(/x0D/x0A)和空白符(/t/x20),所以我们测试一下 $str = "/x0D/x0A".' aaaa@gmail.com'; ,发现其实是可以匹配上的。
那为什么我们不能直接 /t-X/home/www/success.php @gmail.com ?因为,邮箱地址在检测前进行了trim。这个方法gg。
第3组其实就是我发现的绕过validateAddress方法,分析可知:在 /( 和 /) 中间可以填入包括 (?2) 、空白符、引号等在内的大量字符,并且还是递归的(也就是说3里还能有3)。
所以可知,通过使用括号,我们就可以构造空白符了。
(?4) 的分析
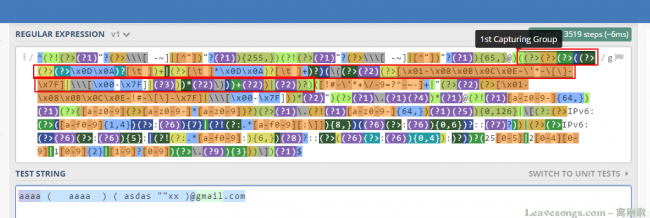
第4组如下:

可见支持如下一些字符,其中是不包含空白符的: [!#-/'*+//-9=?^-~-] 。但如果两边有 " ,那么支持的字符就多了: [/x01-/x08/x0B/x0C/x0E-!#-/[/]-/x7F] ,包括空白符。
这也就是漏洞发现者给出的POC使用的方法:将Payload用双引号包裹。
@前的其余部分分析
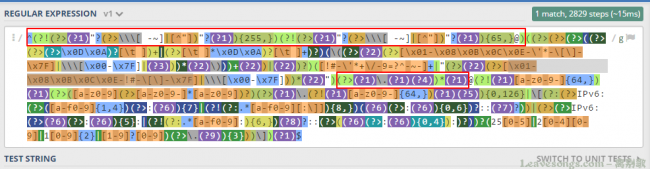
如上图,在 (?1) 前面的部分,是两个消极断言 (?!) ,实际上是不允许的内容,但又不会捕捉,这就不会影响正则的走向,因为后面的1组还是会捕捉它。所以这两句对我们绕过没有任何帮助。
在 (?4) 后面的部分,其实比较有趣。 (?>(?1)/.(?1)(?4)) 这里这句话导致了另一个绕过:
aaa. -X/tmp/test.php @gmail.com
原因是 (?1) 是可以包含空白符的,只要有一个空白符, (?4) 就能逃出来了。
从 (?>(?1)/.(?1)(?4)) 再往后看,这里再次调用一个 (?1) ,所以又可以如下绕过:
(aaaa) -X/tmp/test.php (xxxx)@gmail.com
配合下图,其实就很好理解了:

Group 1是可以包含空格的,因为两处都调用的Group 1,所以夹在中间的部分Group 4也就是Payload了。
尾记
@后面的部分留给大家自己去分析。
那么本文叫“谈一谈复杂的正则表达式分析”,其实我也只分析了半个表达式而已。但诀窍已经在这里了:
- 找一个好的辅助工具
- 理解断言、递归组、子匹配、一次性子组等概念
- 一段段分析,不要害怕
最后一条很重要,正则也是人写出来的,所以没有看不懂的道理。而且,在代码审计的过程中,基本上你并不需要完全理解一个正则(比如本文中的正则我也有很多地方没有分析,但这不妨碍我发现问题),你真正需要理解的是编写者的意愿,他为什么会这么写。
那么,PHPMailer中这个正则为什么会这么写?
可能是作者为了完全实现RFC的一些规则,才会这样编写正则吧。
参考:
- http://php.net/manual/zh/reference.pcre.pattern.syntax.php
- https://regex101.com/r/aGGWWw/2
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

