从原始数据到数据科学:使非结构化数据结构化,以推动产品开发
数据科学正在快速发展成所有行业开发人员和管理人员的关键技能,它看起来也十分有趣。但是,它非常复杂,虽有许多工程和分析工具助力,却也难清楚掌握现在做得对不对,哪里是不是有陷阱。在本系列中,我们解释了如何发挥数据科学的作用,理解哪里需要它,哪里不需要它,以及如何令它为你产生价值,如何从先行者那里获得有用的经验。
这是“ Getting A Handle On Data Science(理解数据科学) ”系列文章中的一部分。你可以通过RSS予以订阅。
- 本文要点
从非结构化的机器日志到提供当前特定信息的高度结构化的数据分析表,存在着不同层级的数据“结构”。
- 在使用结构化数据的同时,数据的体量和多样性也会降低,同样降低的还有操作数据需要的相关技术难度、数据分析前准备数据所花费的时间以及业务用户评估数据所花费的精力。
- 在做任何数据模型或开发数据管道之前,对非结构化数据进行分析并深入研究一两个真实业务问题将会受益良多。
- 要给非结构化数据增加结构,我们可以从三个方面入手:数据体现的人类真实的行为、所掌握的这些行为发起者的元数据、以及记录这些行为的技术手段所遗留的结构。
- 为了将结构应用到数据上,首先要定义一些可以用于识别相关业务概念或性质的可量化的信号,然后我们就可以使用这些信号来区分我们概念中定义的值。
引言
Cassandra、MongoDB以及在Postgres中存储JSON数据等非结构数据库技术已经能非常方便地对非结构化数据进行存储和处理。软件、数据工程师在大多数情况下也可以不使用数据模型而达到预期效果,数据模型不再是收集数据或提取数据价值的前提条件。我们可以从不同数据源大量收集数据,而不必知道收集它们的理由、或这些数据对达成产品整体开发和业务目标所产生的价值。
说到这里一些读者就开始警觉起来了。为什么要收集这些你根本不知其价值的数据呢?毕竟,在过去的数十年间,信息管理人员仅仅为了将数据展示给资深业务人员看,就需要花费数月时间,通过收集业务需求并建模来为数据增加结构。另一些读者也许在读到本文的标题时就想,“为什么要新增结构呢?”。毕竟,对数据工程师来说NoSQL运动意味着,在大多数用例中,不再需要为了将数据存入关系型数据库而建立数据结构了。
这两点说得都有道理,但事实上信息管理人员和一线数据工程师的这些观点都不完全正确。实际上数据在其生态系统的不同位置会存在不同的结构层级,为了正确地定义每一个层级,我们必须理解为数据增加结构所需的成本和能带来的好处。
完全非结构化数据生态系统所需的人力成本
尽管存储数据的设备成本相对来说已微乎其微,数据的体量与多样性却会导致人力成本指数级上升。
相对于传统的关系型数据库,使用非结构化的数据会需要更多数据工程师或高级分析师。对每个新的业务需求,分析师和业务、产品经理都需要花时间来理解所拥有的数据以及如何根据这些数据来作出他们的决断。毕竟,结构化的数据好比一份数据的菜单,而非结构化的数据更像一个大型的杂货店。
即便分析师熟悉相关的数据,对每个(新)业务问题,都会需要他们具备数据工程相关技能来应对潜在的复杂数据准备过程,分析师们都知道这步需要一系列特定的技能,并且非常耗时,因此用来支持分析和决策的时间就所剩无几了。
简而言之,非结构化数据导致的人力成本包括:
- 完全没有结构的数据制约了公司规模化高效预处理的收益,会需要花费更多时间来应对每个业务问题。
- 给分析师预留的空间不足以支持常规性业务分析,同时也没有用到他们高级的数据工程技能,这意味着需要雇佣并留住更多昂贵的分析师。
所以如果在数据生态系统中完全依赖于非结构化的数据,会给人力资源成本带来巨大压力!这包含对各个业务需求的响应时间以及业务分析团队员工所需具备的技能。
那么一个完全依赖结构化数据的生态系统会怎么样呢?
完全结构化数据生态系统所需的时间成本
在传统的信息管理漏斗模型中,我们一开始会收集需求,定义目标的结构(例如,数据应该有怎么样的结构),之后开发对应的管道将数据从源转换到这个结构。是否在决策中使用新的数据不是一个孤立的过程。测试数据、评估数据、认同是否应该将数据引入到常规决策中都需要花费时间。这样一般都无法满足业务对数据的实时性需求,只能用于非实时的业务案例,即历史或假设的案例。
在一个完全结构化的数据系统中,分析师需要在使用数据进行业务决策前理解并模型化它们。如果拥有这么一个使用数据的先决条件,那么数据管理部门就不可能应对业务用户对数据日益增加的需求。用于做出当下及未来业务决策的关键数据可能会在到达决策支持分析师之前长时间被卡在信息管理管道中,更别说到达业务管理人员手中并用它们做出业务决策和行动了。
所以虽然传统的信息管理者倾向于把数据引入这种正常工作了20多年的信息管理漏斗模型中,但这样做永远无法成功地从这些数据中获得竞争优势。结构化数据存储的开发时间会十分漫长,并且会需要关注许多数据和业务资源方面的其他工作。
所以我们想要在我们的数据生态系统中平衡系统的灵活性、NoSQL的低单位成本和信息管理漏斗的高效率和低分析师成本。
结构化的业务利益
人们天生倾向于使用组织好的数据,同样地,业务期望其数据拥有大量结构,从而达到操作上对结构的需求。举一个例子,一个通用的业绩视图可以为大家提供一个通用的目标(例如减少关于对优秀业绩的定义及其衡量方式的争论,进而可以更多地讨论特定领域提高业绩的方法)。
在业务沟通和商业目标监控上,关键业绩指标,标准化用户、业务、产品维度,甚至一般用户行为数据等结构都有重要作用。不仅如此,结构化数据同时还可以为分析师间沟通实践经验提供支持。由于分析师必须科学地实施每个业务概念,在数据中建立一个通用语言或通用操作定义对于分离的数据分析师团队就很有必要。分析师之间可以用它来分享观点和技术,而不用相互争论如何将通用业务概念转换为数据对象。
更一般地说来,结构是收集特定真实生活现象或领域中信息的一套系统化方法。它是一套对这个现象准确的需求,并要求任何希望插入数据的系统提供这些信息(即数据对象)并在其中包含相应属性(即数据类型)。
达成平衡
所以虽然如今数据工程师和科学家倾向于使用没有结构的环境,但如果一个组织希望将数据运用于决策判断时,他们还是必须在数据上创建相应结构。
因此我们必须平衡的因素有,系统的灵活性、NoSQL单位存储成本的优势、高效的数据准备过程、低成本的业务分析师、和组织中不可避免的搭建结构化通用数据源的需求。
为了达到这点,我们必须定义一个数据管理漏斗,这并不是为了扩展非结构化数据,也不是为了给数据加以长度和结构限制。那它是一个怎么样的过程呢?
数据管理漏斗
结构化和非结构化数据的矛盾的根源是数据管理和软件管理的一个常见问题,即,是快速构建一个可用产品,还是在探索其潜在价值并获得相关经验后再大规模投入成本。数据产品包含以下的任意一种:
- 数据科学家的非结构化的数据集
- 数据分析师的结构化数据集
- 模型输出的数据集(例如价格弹性系数)
- 提供给业务用户或非专业分析师的自助应用
- 数据使能的产品或平台系统(例如在推荐引擎下训练过的神经网络)
在开发以上这些产品时,我们看到越来越多的软件管理原则进入数据科学领域并取得成功。数据团队可以使用非结构化的数据和最小可用产品来评估数据的价值,并将结构扩展到需要的地方以便让非专业分析师能够理解数据中的价值。这过程常常使用实时数据来解决真实的业务问题。这与信息管理漏斗不同,信息管理漏斗常使用历史或假设的需求来定义理想的结构。
那么我们在数据管理风格的漏斗模型中适应产品管理风格漏斗模型时,需要考虑哪些核心问题呢?
定义数据管理漏斗中的核心问题
- 数据集何时被应用于实时业务问题?
- 数据本身何时、如何评估其结构化的需求和价值?
- 你所在的组织内,结构化数据何时被增加到用于生产的数据中?
为了高效解决以上问题,以下三个阶段必不可少,当然可能会需要其他阶段。
数据完备的三阶段
- 原始数据:大量,完全非结构化。数据源:常常直接从机器上得到(例如服务器日志、api输出)。访问:受操作、数据分析技术和隐私保护等限制的访问权限。典型用户:使用NoSQL语句或者利用python进行高级处理的数据工程师或者数据科学家。
- 便于分析的数据:由大量转换为中等大小,部分结构化或完全结构化的数据。数据源:将原始数据经过ETL处理后,存入表或NoSQL集合中的数据对象,理想情况下是以可分析的单元进行组织的数据(例如,基于用户的集合中描述了所有我们掌握的对用户的信息)。访问:由于数据的大小和不同类型的格式使其难以被查询,所以仅限掌握高级技能的分析师和数据科学家使用。
- 管理报表数据:完全结构化数据。数据源:从前两个阶段经过计算得到,同时包涵业务、产品经理在业务中需要的数字(例如KPI),以及聚合的业务驱动数据(例如,当公司报告财务增长时,常常同时列出价格、数量、汇率、并购等因素)。访问:由数据安全策略来控制访问权限。典型用户:商务智能(BI)分析师或业务、产品经理的自助分析。
在漏斗的每个阶段,会引入越来越多的业务逻辑和相关术语,当然还有越来越多的结构。数据对象在格式和数值范围上越来越稳定,同时使用的分析工具类型也越来越倾向于关系型数据库的形式。同时还有管理和隐私的问题,前期阶段比后期更可能包含个人识别信息和敏感信息。在漏斗模型的每个阶段你应该清楚谁有这些数据的访问权限,以及用户可能对这些数据做什么操作(然而本文并不解决这个问题)。
漏斗的第一阶段是不受限的落地操作,主要考虑单位存储的成本,这部分通常只能被核心的数据处理系统访问。系统和数据工程师将数据放在那里用于提供给他人进行研究。在该阶段产生数据是低效的,并且这个区域的数据很快就会变得混乱!
最后一个阶段就完全相反,它会落地一个高度受管理、高度结构化数据,并可以广泛地被访问(除了大型公开上市公司的市场敏感数据)。业务、产品经理使用这些数据来衡量他们决策的优劣,并从中获得对各因素的宏观理解,数据在到达这阶段时,应该已经拥有严格的定义和变量类型。
其中最重要的,也是最令人费解的部分是它们之间的中间层,这层将原始非结构化数据转换为具有高潜在价值的部分结构化数据。正是在这里各个因素达成平衡,实践社群产生作用,深入理解用户的行为,并发现绩效背后的真实原因。
从第一阶段(原始数据)转换到第二阶段(便于分析的数据)的过程会遇到很多困难!一段非结构化的数据能够生成一个完全易于分析的结构。例如,一个Twitter上分享的图片可以形成三个不同数据库表中的数据对象:
- 通过x坐标,y坐标,RGB表示的Tweet图片像素
- Tweet对应的文字和时间等
- Tweet的发布者和其账号、粉丝等
这些都是潜在的信息能帮助我们更好地利用这条Tweet数据。
漏斗模型并不是简单过滤多余繁杂的数据,相反,那些看似无用的数据的内部能体现出向结构化数据转换的具体需求,进一步解答可以从哪里着手处理这些原始非结构化数据。相对于从需求中寻找数据结构,在真实商业挑战环境中使用原始非结构化数据可以更有效且更高效地建立理想的数据结构。
解决这个挑战就意味着释放了观察、理解、预测和控制业务中的各个方面的潜能,尤其是在研究用户行为方面。因此在这上面花费时间和精力是值得的。显然,在该步骤中潜在价值超过了需要投入的资源,这也正是数据科学家的用武之地!
所以我们应该如何将混乱的非结构化数据转换到对组织有价值的数据,并从中提炼出常规所需的结构呢?
使用非结构化数据
目前的情况是,如果不在历史或现在真实的商业挑战环境中对数据集进行分析,极难理解其内部的价值。相对于从业务人员手上拿到数据需求,并用其定义数据的结构,在真实商业挑战中使用原始非结构化的数据是一种更有效、更高效的方式来建立理想的结构化数据。
所以在数据建模或开发数据管道之前,可以尝试先创建一个MVDP(minimum viable data product,最小可用数据产品)并用它深入研究一两个真实的业务问题。
那么哪些非结构化数据适用于MVDP呢?
非结构化数据常见类型
- 网站应用数据格式(如JSON、HSTORE)
- 文档文件格式(如HTML、XML、pdf)
- 无格式文本(如pdf文本、tweet或博客文本)
- 图片(如jpg、png)
- GIS(地理信息系统)矢量和栅格(Raster)(有数据库可以存储这类数据类型,所以暂不把他们归类为非结构化数据)
大多数读者对网站应用数据和将其解析为结构化数据的过程比较熟悉。随处可见将JSON或其他类似的网站接口输入存储到数据库的需求,这也是一个开发NoSQL解决方案的动机。HTML和XML等文档文件格式可以使用Nokogiri等工具进行解析。大多数情况下,几乎所有pdf是无格式文本(当然扫描文档除外)。业界都在寻找方案来从以上这些常见类型、图片和无格式文本中提取内在价值。
在需要分析文本或图片时,有数不胜数的分析工具可以使用,这里我们并不推荐某个特定工具,而是要理解一个特殊的处理过程,这个过程包含:
- 从概念上将业务问题结构化
- 尽力将其中概念转换成可计算的信号
- 使用数据科学来建立从信号到业务问题单一结构概念的转换关系
为什么我们需要关心这个流程呢?为什么我们不直接使用现成工具来解析文本和图片?
当然,在分析图像时,有一个完美的图像识别解决方案十分方便。在这种理想解决方案下,你可以使用一个contains_couch(是否包含沙发)方法来识别图片中是否存在沙发,甚至可以返回一个只包含沙发的png文件和其相关的属性,如{colour: brown}。同样,在分析文本的理想环境中,一个完美的自然语言处理解决方案会包含is_sarcastic(是否包含讽刺内容)或contains_political_opinion(是否包含政治观点)方法,返回对应内容是否包含了讽刺或低劣的政治观点。这样我们就完成了非结构化数据到高度结构化或业务相关变量的转移。
但以我个人的经验来看,上述技术如今在某些方面虽然已经接近目标了,但还远远无法实现。并不是任何人都可以做到只安装一个python包或ruby的gem,并通过上述的方法来查询文本或图片并获得一个足够可靠的结果用于进行决策判断。在这理想解决方案和原始数据的中间地带,任何有助于增进理解、了解用户喜好或为业务、产品经理作出更好决策的过程都是有用的!
从概念上寻找非结构化数据结构的三个入手点
激增的数据相关投入得到的产出未必真有预想中的这么多,而潜藏在大多数数据背后的是技术环境下人们所表现的行为。我们真正投资的是整个观测体系和其对个人行为的理解,特别是那些和我们业务有关的行为。我们将使用这个基本的观点来定义我们在非结构化数据上增加结构的方法。
从概念上寻找结构可从三个方面入手:
- 元数据:在观测系统(即,使用的技术)中寻找创建数据所使用的结构。所有技术都是在一个高度结构化的方式下运行的,可以观察系统是否在数据中留下了结构相关的记录(例如,html中的css标签或服务器日志中的元数据)?
- 用户创建的数据:在产生数据的软件特定的界面中寻找结构。大部分软件在使用时都拥有独特的交互方式来转换相对应的结构。例如,一个“#”号在普通环境中并没有任何含义,但是在Twitter中“#”号用来表示将用户产生的内容按特定话题进行分类。同时它也被用来体现幽默,如#SorryNotSorry(中文意思为:抱歉,我没有任何歉意)。类似的,一个“@”号表示两个Twitter账号之间的互动。在你的站点或产品中用户产生的内容是否有类似独特的功能?是否这些功能对应着用户特殊的行为或业务概念?一条包含这些特性的数据可以提供大量的结构,用于表示用户当时的行为状态(包括,所在站点的位置、该站点所期望的操作、与其他人的互动等)。
- 用户自身产生的数据:这有时也被称为“根属性”,总而言之它参照外界对系统产生变更的对象,并同时产生对应数据,对软件用户来说,这个“根”就是和软件交互的用户。
一旦我们从以上三个方面的任意一个或其他更好的方向中建立了这么一个结构概念,我们如何将这个结构概念应用到数据中呢?
通过计算增加结构的第二、第三步
第一,我们需要定义信号。信号是一种业务概念量化的属性,用以帮助我们识别概念的存在及其性质。然而它们不等同于概念。例如,假设所有沙发都是棕色的,那么在图片中寻找所有棕色是一个合理的信号来判断其中是否存在沙发。
第二,我们通过建立计算出的信号和概念结构的关系,来区分我们定义的不同结构化的数据。这个关系可以是确定的(例如,contins_couch:TRUE或FALSE),也可以用可能性来标识(例如contins_couch:0.9)。
当信号和概念间的关系是基于可能性的,这常常就表示信号中没有足够的信息来唯一地定义概念的结构。一个图片包含棕色是图片中包含棕色沙发的一个信号,但是无法确定图片是否真的存在沙发。出于这个原因,从业人员会基于他们使用的非结构化数据,定义尽可能多的独立信号。通过这种方法他们必须达到三个竞争因素间的平衡,即信号的数量,信号间的独立性及计算信号和关系所需的计算成本(独立性尤其重要,如果两个信号提供同样的信息,并不会有助于提升对概念的识别能力,例如图片中暗棕色的占比和亮棕色的占比,并不会对结果有任何帮助)。
一开始,任何概念相关的量化属性都存在潜在价值。如果一个信号和对应概念一起出现一起消失,那么它就是一个理想的表示概念出现的信号。进一步,如果信号会随着对应概念的变化而变化(例如,不同棕色可以识别为不同颜色的沙发)那么这个信号可以唯一定义沙发这个概念!在实践中,很少有一个单独的信号可以用来解释期望的概念。相反,我们常常使用大量的信号来定义一个概念。上百个信号会被搜索引擎用于生成搜索的结果,即便你只是输入少量单词也是如此。
定义信号是一门科学同时也是一门艺术以及创造力的体现。另一方面,一旦定义完信号,在信号和概念的不同状态间建立关系更像是一门(数据)科学。
为了完成最后一步,首要考虑的就是什么数据结构是表达对应概念的最佳方式?例如,像contains_a_couch(是否包含沙发)、is_political(是否有政治倾向)这样的二元的概念可以是一个方法,把信号作为输入并输出一个布尔的结果。另一种情况,一个如text_topic_list(文本话题列表)这样的概念可以接收信号,并返回相应话题列表(当然,如果你拥有规格化的主表来记录话题本身,这里可以只返回话题的编号列表)。
当拥有了概念的一系列信号和目标数据结构后,机器学习就成为了你匹配工具列表中一个优先的工具,但不是必须的工具。在下面的例子中,我们将使用一个基于数字化信号的神经网络式的分类方法来演示如何完成这整个过程。
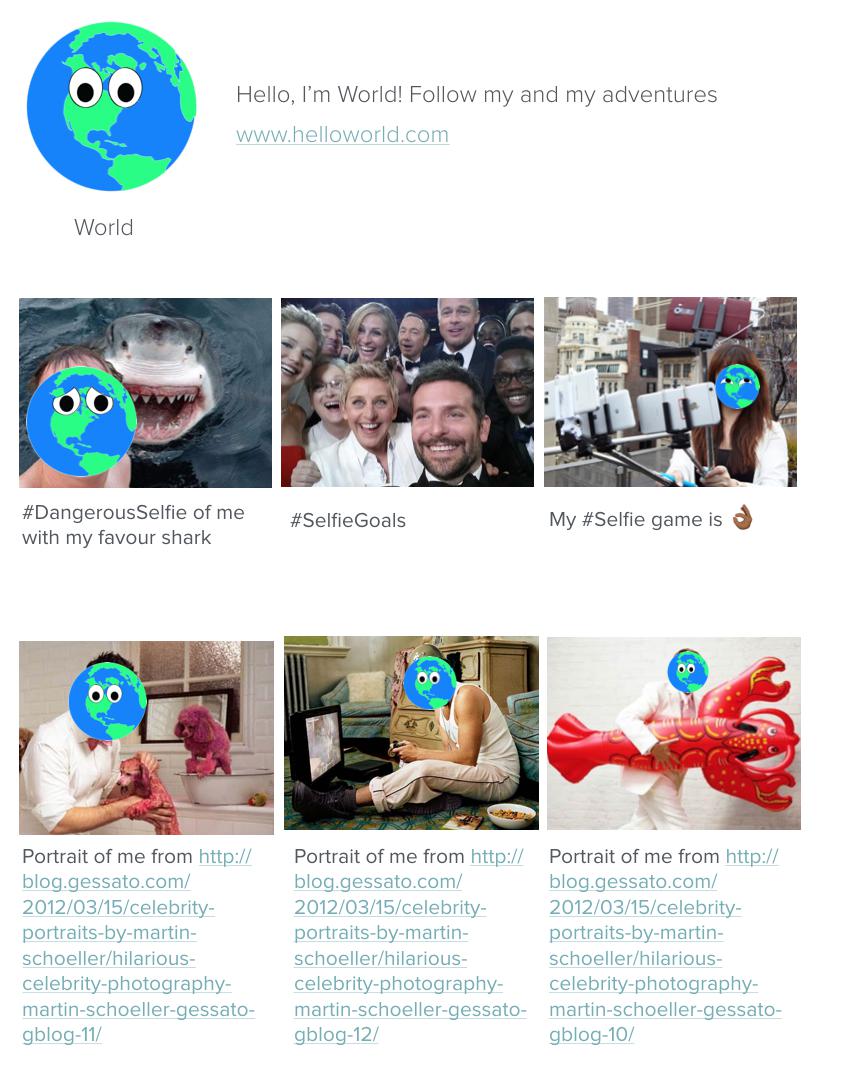
Hello, World!
在我研究生的机器学习及人工智能课程中,椅子和沙发的识别常被作为课本上的例子。这是因为像椅子这么一个平凡的概念很容易从概念上创建结构,因此可以方便地通过计算的方式对数据进行研究,但是在实践中这是很复杂的。在我们下面的例子中,情况相反:这个概念在实践中很难创建结构,但是可以理想化地使用简化的方法使其方便地进行结构化。
我们的例子是,分析一个叫World(地球)的角色的社交媒体行为。World不是一个真实的人,这个例子极度形式化地展现了以上所讨论的概念。我们非结构化数据的来源是一个HTML形式的社交媒体个人页面。我们将要对这个个人页面增加自拍相似度这个结构,并以浮点小数形式表示World个人页面中自拍照的占比。这里我将使用Ruby来演示这个方法,你同样也可以使用Python或其他语言来处理图片。
(点击放大图像)
第一步,使用网页元数据创建结构化数据集
在此警告!网页抓取是不恰当的,甚至很多情况下会破坏网站的使用条款。在抓取网页前,你应该检查网站是否提供对应API,阅读相关条款并查看你是否可以抓取网站上的数据,以及抓取的数据的使用范围。
首先要从数据创建技术的实现方式来寻找结构。网页是高度结构化的数据,尤其是javascript和html,大量的结构可以直接从里面得到。在我们的例子中,我们将使用html文件中的css标签来解析出帖子、帖子文本和帖子图片,我们会用这些来定义页面的自拍比例。
为了实现这点我们会使用如下方法来解析html,其中用到了 Nokogiri.org :
def generate_structured_post_array(web_page_html)
post_array = []
css_selectors = {
posts: ".post",
post_img_url: "img_src"
}
@profile_html = Nokogiri::HTML(web_page_html)
@profile_html.css_selector(css_selectors[:posts]).each do |post|
post_image_url = post[css_selectors[:post_img_url:]] #你可以将文件打开并保存到一个服务器上
post_text = post.text.gsub(//s+/,’ ') #去除多余空行和空格
post_data = {
post_image_url: post_image_url,
post_text: post_text
}
post_array+=[post_data]
end
return post_array
end
到这里,我们已经将网页转换成包含账号相关信息的JSON格式的帖子数组。此时,我们已足以可以开始提取相关结构化信息,例如post_array的长度表示帖子的数量。HTML和XML文件等是理想的“非结构化”格式,这是由于这些格式的创建者(机器或个人)使用这个语法来增加结构信息,从而使机器在读取数据后可以使用这个结构来可视化信息或进行后续操作。换而言之,这个语法是创建者和消费者之间的一种协议,而每个协议都需要一定的可预测结构。正是这样的结构常常包含着数据分析所需的宝贵的元数据。
第二步,使用用户产生的数据
到目前为止,我们只建立了该账户创建了多少帖子和每篇帖子包含的图片地址和帖子文本。图片和无格式文本是传统的非结构化格式,因此我们需要在判断帖子是否包含自拍之前为每篇帖子增加更多结构。
幸运的是,World是一个井井有条且相貌独特的人,他创建的帖子中表达自拍的信号很清晰。例如,所有有World的自拍都用#selfie标签或其变体来标示(例如#DangerousSelfie、#Selfie)。然而,我们并不能只简单查看这些标签,因为在帖子2中你可以看到,World也标识了#SelfieGoals。同样也存在World发出自己的照片却不属于自拍。所以我们需要同时使用这两个信号来判断每个帖子是否是自拍。下图是判断的主要过程:
(点击放大图像)
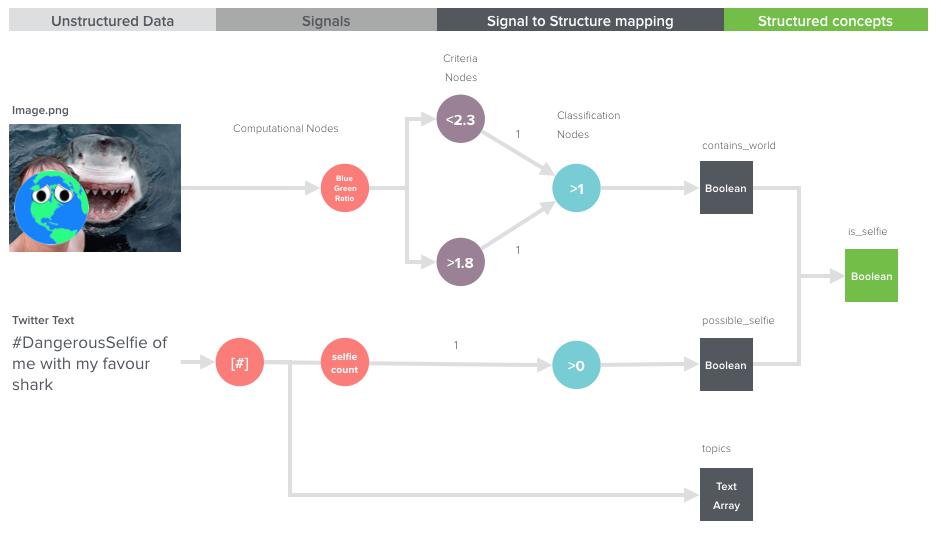
当处理无格式文本时,建议使用能想到的最简单的分析方法来处理,这样你可以逐渐解决问题,并能为你下一个(稍微)更复杂的步骤提供宝贵的经验。除非你对你的数据和主题领域极其确信,不然不要直接挑战最高级的解决方案(如自然语言解析)。如不这样,你也可以通过对一些简单的属性进行分析来达到两者的平衡:
- 二元单向变量->判断文本是否拥有一些特定的属性。例如,是否包含自拍这个词?是否大于100个字符?等。
- 数值变量->文本的任何数字形式的属性,如,“#”号的数量、字数、词数(包括空格数)。
- 文本数组->将整篇无格式文本分割成相关单词的数组或使用更常见的N元语法模型(n-grams)。还有 流行的开源包 用于分割不同推特类型数组(如“#”号)。
在我们的例子中,我们要分割所有“#”号,再计算contains_selfie(包含自拍)这个二元单向变量,代码如下:
def classification_topics_array(post_text)
return post_text.split("#").map{|h|h.split(" ")[0]}
end
def classification_possible_selfie(topics_array)
keyword= "selfie"
lower_threshold = 1
keyword_count = 0
topics_array.each do |t|
count+=1 if t.downcase.includes?(selfie_keyword.downcase)
end
return (keyword_count>lower_threshold)
end
接下来,是时候来判断哪些图片真的包含World了。再一次强调,当处理图片时最好使用尽可能简单的分析方法,尽管本例这么做的话无法达到预期目的。与前面的步骤不同,受限于时间和其他资源因素,创建你自己满足需求的图片处理过程可能会比较困难甚至无法实现。但是,这仍值得思考一下!
第三步,使用我们对现实生活的知识
幸运的是World比较独特。退一步考虑现实生活中自拍这个概念,我们可以问自己:有什么关于World的量化属性能唯一视觉化定义它?是的,World是由蓝色海洋和绿色的大陆组成的。World在照片上的尺寸各不相同,但是它上面海洋和陆地的构造是不变的。啊!我们很幸运发现了这点。能唯一定义World的量化参数正是World的蓝色和绿色的比例。
到了这里,还是会有一些变化。当World在笑时,它的眼睛变小,更多的绿色和蓝色显现出来。当Word受惊吓,眼睛下移,同样显现出更多蓝色和绿色。这两个例子都不能精确保证这个比例,所以我们不定义蓝色的固定占比,我们定义蓝色的一个范围(如,当这个蓝绿比在可接受范围内,我们就认为这张图片包含蓝色)。
要实现这点,我将使用 开源包 。首先,这里有一个使用 教程 。它会教你起步并制作一个直方图(左边的是原图):
def compute_colour_ratio_signal(hex_distribution,top_colour,bottom_colour)
bottom_colour_volume = 1
top_colour_volume = 0
@hex_distribution.each do |pixel_volume,hex_code|
case hex_code
when top_colour
top_colour_volume = pixel_volume
when bottom_colour
bottom_colour_volume = pixel_volume
end
end
r = top_colour_volume/bottom_colour_volume*1.0
return r
end
一旦定义好这个比值信号,常常使用机器学习来建立用于分类的阈值。

这里我用肉眼估计一个范围。并使用下面这个分类方法。
def classification_contains_world(image_url)
world_blue = "#1683FB"
world_green = "#2AFD85"
upper_threshold = 2.3
lower_threshold = 1.8
@rmagic_image_object = Magick::Image.read(image_url).first
@hex_distribution = generate_hex_distribution(@rmagic_image_object) #hint: use quantize method and loop through all the pixels
colour_ratio = compute_colour_ratio_signal(@hex_distribution,world_blue,world_green)
return (ratio <upper_threshold && ratio>lower_threshold)
end
针对所有图片运行这个方法的结果如下:
- "图片1的比例1.9686841390724195包含World可能是自拍"
- "图片2的比例0不包含World可能是自拍"
- "图片3的比例2.1200486683790727包含World可能是自拍"
- "图片4的比例1.8354139761802266但不可能是自拍"
- "图片5的比例2.215403012087131但不可能是自拍"
- "图片6的比例2.256290438533429但不可能是自拍"
在我们的神经网络中,只有当两个判断同时返回真时,我们才将其归类为自拍。本例只有图片1和3满足,所以World“自拍率”这个非结构性概念的结果是33%(2/6)!
关于作者
 Rishi Nalin Kumar 是 eBench.com 的联合创始人和首席数据科学家,eBench是一家致力于数据驱动的数字化营销顾问和SaaS(软件即服务)平台的初创公司。他也是一位DataKind英国分会领导,这是一个运用数据进行关爱慈善活动的组织,它和第三方部门组织合作,将数据科学应用于人道主义活动。他曾就职于Unilever(联合利华)、The Guardian(卫报)和Spotify,进行数据挖掘方面的开发,涵盖从产品开发到人权维护等不同领域,并为其开发数据战略,将数据科学及数据科学家引入到这些组织的决策过程中。
Rishi Nalin Kumar 是 eBench.com 的联合创始人和首席数据科学家,eBench是一家致力于数据驱动的数字化营销顾问和SaaS(软件即服务)平台的初创公司。他也是一位DataKind英国分会领导,这是一个运用数据进行关爱慈善活动的组织,它和第三方部门组织合作,将数据科学应用于人道主义活动。他曾就职于Unilever(联合利华)、The Guardian(卫报)和Spotify,进行数据挖掘方面的开发,涵盖从产品开发到人权维护等不同领域,并为其开发数据战略,将数据科学及数据科学家引入到这些组织的决策过程中。
数据科学正在快速发展成所有行业开发人员和管理人员的关键技能,它看起来也十分有趣。但是,它非常复杂,虽有许多工程和分析工具助力,却也难清楚掌握现在做得对不对,哪里是不是有陷阱。在本系列中,我们解释了如何发挥数据科学的作用,理解哪里需要它,哪里不需要它,以及如何令它为你产生价值,如何从先行者那里获得有用的经验。
这是“ Getting A Handle On Data Science(理解数据科学) ”系列文章中的一部分。你可以通过RSS予以订阅。
查看英文原文: From Raw Data to Data Science: Adding Structure to Unstructured Data to Support Product Development
正文到此结束
- 本文标签: 压力 NOSQL API 智能 XML 投资 数据挖掘 NIO 协议 数据库 sql 管理 CTO json 开源 python 图片 服务器 安全 领导 空间 Select 开发 数据模型 Twitter 站点 搜索引擎 CSS 创始人 HTML文件 参数 Word 数据科学 web js 标题 数据 地球 解析 软件 博客 JavaScript java struct 网站 UI 时间 MongoDB 组织 http 神经网络 希望 ip cat 安装 需求 Cassandra list src 营销 十年 db 产品 map 代码 HTML key dist 文章 IO 测试
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

