苹果首份AI论文横空出世,提出SimGAN训练方法

当AI浪潮袭来,谷歌、Facebook、微软等几个山头恨不得把自己都浸没在潮水里,可劲打滚儿的时候,苹果这座孤岛却始终有一种不愿被沾湿的姿态。
12月初,在洒满阳光的西班牙NIPS大会上,苹果AI研究团队负责人Russ Salakhutdinov曾兴奋地宣布,苹果将允许其AI研究人员对外发布论文。那之后,众人都在翘首以待,巴巴等着这个这个世界上市值最高的公司(截至12月23日市值6172.34亿美元)的第一篇AI论文将以何种面目出现。

今天,这篇论文出来了。苹果伸出了手指,试探了一下海水。
这篇题为《通过对抗训练从模拟的和无监督的图像中学习》(Learning from Simulated and Unsupervised Images through Adversarial Training)的论文于12月22日提交给了arXiv.org,一经发布迅速点燃了媒体头条。
苹果这篇图像识别领域的论文,提出了一个所谓“模拟+无监督学习”(simulated + unsupervised learning),使用了如今最炙手可热的深度学习“对抗训练”。
而有着“GANs之父”之称的Ian Goodfellow在推特里直接评论道:“苹果第一份机器学习论文是关于GANs的。”
于是,GANs又借势火了一把。
生成对抗网络(GANs)的经典过程
所谓的GANs模型,就是让两个网络相互竞争,玩一个“猫鼠游戏”。
-
一个叫做生成器网络G( Generator Network),它不断捕捉训练库里真实图片的概率分布,将输入的随机向量转变成新的样本。一句话,G负责生成假图片。
-
另一个叫做判别器网络D(Discriminator Network),它可以同时观察真实和假造的数据,判断这个图片到底是不是真的。
G尝试用自己的赝品来“蒙骗”D,而D也不断提高自己鉴别赝品的水平。这样G的造假能力和D的鉴别能力都会越来越高超。
在机器学习领域,需要海量的数据来训练模型,而海量数据本身的获取都成问题。AI界常有这么个说法:
“谁手握了数据,谁就占据了人工智能的制高点。”
南京大学周志华教授也曾经在演讲中提到机器学习应用的限制因素:
机器学习虽然能力很强,但它并不是一个万能的东西 。至少有两件事,我们经常都要提醒自己,机器学习可能是做不了的。
第一种情况,如果我们的拿到的数据特征信息不够充分,那么机器学习可能就帮不上忙;第二种情况,如果数据样本的信息非常不充分,那么这种情况也基本上解决不了问题。
所以,GANs最具革命性的地方在于,它的生成器G自己产出数据,而人只需要最初输入一些随机向量。无怪乎,Yann LeCun曾评价说:
“ 对抗训练是切片面包以来最酷的事情 (Adversarial training is the coolest thing since sliced bread)。”
苹果的SimGAN训练方法
但是苹果这份论文里提到的模型,与GANs还是有些微不同的。他们想要解决的问题就是:提升合成图像的质量。他们对GANs稍加修改,提出了“SimGAN”训练方法,其中的“Sim”指的就是单词“模拟器”。论文摘要里提到:
“我们的模拟+无监督学习方法,使用的对抗网络跟GANs很类似。但是,输入值是合成图像,而不是随机向量。”
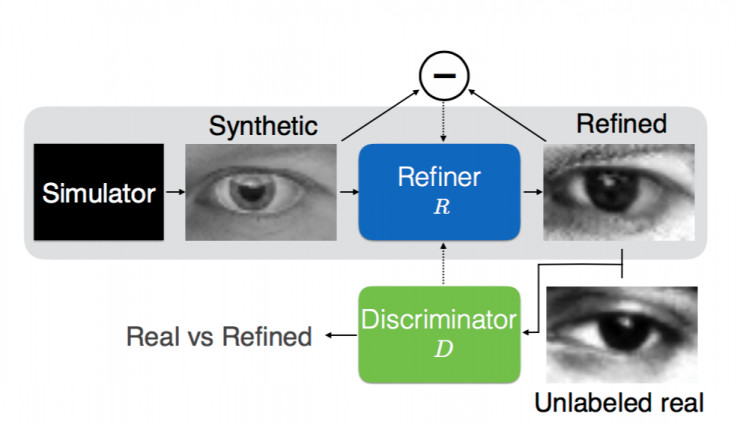
苹果的SimGAN其实包括三部分:模拟器(Simulator)和精制器(Refiner),然后再加上一个判别器(Discriminator)。模拟器合成图像,再用精制器优化,最后喂给判别器训练。
有学术圈内人士对这篇论文的“含金量”表示怀疑,然而苹果这份论文“试水”的意义其实远大于论文本身的意义。Forbes评论道: 这篇AI论文,是苹果标志性的一步 。
对于AI业界来说,这表明苹果要迈开步子、扛着大旗来搅动海水了。
这篇论文的第一作者是Ashish Shrivastava,其个人主页上显示为马里兰大学计算机视觉博士。

其它共同作者还有5人,分别是Tomas Pfister, Oncel Tuzel, Wenda Wang(华裔), Russ Webb 和Josh Susskind。但是苹果的“秘密文化”并没有一下子就敞开大口,这6名研究人员,除了Tomas Pfister之外,雷锋网 (公众号:雷锋网) 在Twitter上很难找到其它5人的踪迹,而Tomas Pfister这位剑桥、牛津双名校的高材生,至今发过的推文也只有5条而已。
相关文章:
百度硅谷 AI 实验室主任 Adam Coates:企业级 AI 的未来展望及人才竞争
AI+时代,做一名焦虑的产品经理不如训练迁移思维
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

