分布式锁
分布式锁
0 背景
最近在业务中出现用户重复提交退款,因为重复提交时间差极端,在加上中间网络延迟,导致请求到达服务端时,出现两个请求的时间差在毫秒级,从而导致重复数据;后来在商户端也出现类似的情况,因此开始在关键业务中使用分布式锁来解决这类问题。
分布式锁 是控制分布式系统之前访问共享资源的一种方式。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
实现分布式锁,主要有以下三个方面为重点:
-
获取锁
在并发情况下,保证只有一个client能够获取到锁。
-
释放锁
client在正常处理业务结束之后主动释放锁;client处理过程中出现异常未能主动释放锁,需要系统能够主动释放锁,保证不会出现死锁。
-
其他client获知锁被释放
当锁被释放之后,其他client可以获知到锁已经被释放,并可以重新竞争锁。
1 数据库实现
1.1 悲观锁实现
使用MySQL的InnoDB的排他锁来实现加锁,通过释放链接的方式释放锁。使用select for update sql语句时,数据库会给数据表增加排他锁,当改跳记录加上排他锁之后,其他线程无法再对该记录增加排他锁。
``java
public void lock(){
connection.setAutoCommit(false)
try{
select * from lock where lock_name=xxx for update;
if(结果不为空){
//代表获取到锁
return;
}
}catch(Exception e){
}
//为空或者抛异常的话都表示没有获取到锁
sleep(1000);
count++;
}
throw new LockException();
}
public void release(){
connection.commit();
}
```
数据库的实现方式,性能不高,在获取锁和释放锁时都可能因为数据库异常而出现死锁,为避免出现死锁需要增加表设计的复杂度,如设置锁的超时时间,并需要有job来保证锁超时之后能够正确释放,实现成本相对较高。
1.2 唯一索引
将获取锁通过插入唯一索引来实现,释放锁则通过删除改唯一索引记录实现。
这种实现方式在实际业务中有变化的应用,一般实际业务会通过插入唯一索引获取锁,之后进行正常的业务处理,这个锁记录同时也是业务的一部分,因此不再执行释放锁的操作。比如在结算时,财务入账时会采用这种方式。
java
public void lock(){
int result =0
try{
result = execute("insert into lock values(uniqueid)")
if(result >0){
//获取到锁
//开始业务处理
return;
}
}catch(Exception e){
}
// 未获取到锁
//业务决定是否需要等待以重新获取锁
}
public void unlock(){
execute("delete from lock_table where uniqueid=id")
}
```
2 分布式缓存实现
redis和memcached是目前应用最广泛的分布式缓存,其中一些命令可用于实现分布式锁。
-
memecached
add() —— 在新增缓存时,如果key已经存在则调用失败
cas() —— 类似数据库中的乐观锁,通过比较key对应value的变化来检测是否获取到锁
-
redis
setnx() —— 设置key对应的value,如果该key已经存在,则设置失败。expire() 缓存失效。
因为在我们的生产环境中主要使用redis,因此在这里只介绍redis的实现方式。常规使用方式:
public void lock(){
try{
int result = redis.setnx(lock_key, current_time+lock_timeout)
if(result >0){
//获取到锁
//开始业务处理
return
}
}catch(Exception e){
}
//未获取到锁
//业务决定是否重复获取
}
public void unlock(){
redis.del(lock_key)
}
这种方式存在无法失效,但是当一个客户端获取到锁之后挂掉了就无法即使释放锁,会导致死锁的情况。因此现在主流的方式是为lock_key 设置一个过期时间,在读取key的时实时判断缓存是否过期。_
比如在文章 分布式锁的实现 的实现方式:
``python
# get lock
lock = 0
while lock != 1:
timestamp = current_unix_time + lock_timeout
lock = SETNX lock.foo timestamp
if lock == 1 or (now() > (GET lock.foo) and now() > (GETSET lock.foo timestamp)):
break;
else:
sleep(10ms)
# do your job
do_job()
# release
if now() < GET lock.foo:
DEL lock.foo
```
Redis从 2.6.12 版本开始,Redis中的SET命令可以通过EX second,PX millisecond,NX,XX进行修改,命令SET key value [EX seconds] [PX milliseconds] [NX|XX]
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecondvalue 。
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
因为 SET 命令可以通过参数来实现和 SETNX 、 SETEX 和 PSETEX 三个命令的效果,所以将来的 Redis 版本可能会废弃并最终移除SETNX 、 SETEX 和 PSETEX
这三个命令。
因此上面的代码可以简单修改为如下模式:
``java
public void lock(){
try{
int result = redis.set(lock_key, value,EX 1000,"NX")
if(result >0){
//获取到锁
//开始业务处理
return
}
}catch(Exception e){
}
//未获取到锁
//业务决定是否重复获取
}
public void unlock(){
redis.del(lock_key)
}
```
redis官方也推荐了 Redlock 的分布式锁实现方案,不过目前针对其中的算法还有争论,在线上也没有出现大规模使用,在这里不做过多讨论;
2.1 优点
性能出色,实现相对简单。
2.2 缺点
- redis是内存数据库,虽然redis自身有AOF和RDB的数据恢复机制,并自带复制功能,但在出现宕机的情况下,锁数据很难保证。
- 通过锁超时时间设置来保证锁的最后释放,这要求client在获取锁之后必须在超时时间内完成业务处理,否则超时之后会出现并发问题;且redis是分布式缓存,超时时间还需要考虑网络时间消耗。
- redis单机情况下,存在redis单点故障的问题。如果为了解决单点故障而使用redis的sentinel或者cluster方案,则更加复杂,引入的问题更多。
3 zookeeper实现
zookeeper实现了类似paxos协议,是一个拥有多个节点分布式协调服务。对zookeeper写入请求会转发到leader,leader写入完成,并同步到其他节点,直到所有节点都写入完成,才返回客户端写入成功。
zookeeper一下特点使其非常适合用于实现分布式锁:
- 支持watcher机制,通过watch锁数据来实现锁,采用删除数据的方式来释放锁,删除数据时可以通知到其他client;
- 支持临时节点,如果客户端获取到锁之后出现异常司机,临时节点会被删除,从而释放锁,无需通过设置超时时间的方式来避免死锁。
zookeeper实现锁的方式是客户端一起竞争写某条数据,比如/path/lock,只有第一个客户端能写入成功,其他的客户端都会写入失败。写入成功的客户端就获得了锁,写入失败的客户端,注册watch事件,等待锁的释放,从而继续竞争该锁。
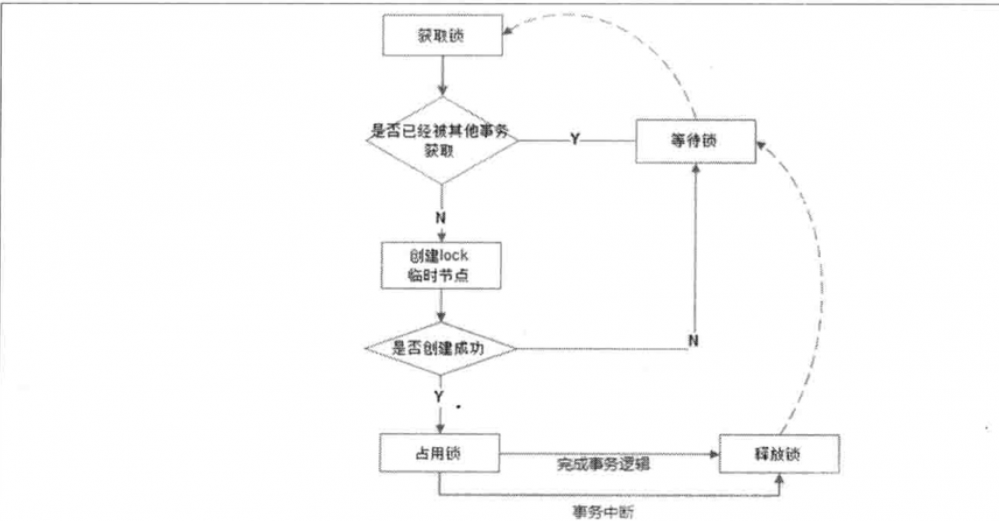
4 etcd 实现分布式锁
etcd 是与zookeeper类似的高可用强一致性的服务发现仓库,使用key-value的存储方式。相对于zookeeper具有以下优点:
- 简单:使用Golang编写,部署更简单;使用HTTP 作为接口使用简单;使用Raft算法保证强一致性,便于理解。
- 数据持久化:默认数据一更新就进行持久化。
- 安全:支持SSL客户端安全认证。
etcd作为后起之秀,处于告诉发展中,目前引用尚不及zookeeper广泛。
References
分布式锁的实现
聊一聊分布式锁的设计
ZooKeeper示例 分布式锁
跟着实例学习ZooKeeper的用法: 分布式锁
etcd:从应用场景到实现原理的全方位解读
从Paxos到Zookeeper:分布式一致性原理与实践
Redis 命令参考正文到此结束
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

