Flink运行时之通信层API
通信层API介于任务执行与通信细节之间,主要用于对上层任务执行提供记录的读写服务同时屏蔽底层的通信细节。主要包括三个部件:将记录写入结果分区的写入器、将数据从输入网关中读出并反序列化为记录的读取器以及周旋在记录和二进制的Buffer数据之间对数据表示进行转换的序列化器。
序列化器
为了使得记录以及事件能够被写入Buffer随后在消费时再从Buffer中读出,Flink提供了记录序列化器(RecordSerializer)与反序列化器(RecordDeserializer)以及事件序列化器(EventSerializer)。
我们先来分析RecordSerializer,作为一个接口,SpanningRecordSerializer是其唯一的实现。它是一种支持跨内存段的序列化器,其实现借助于中间缓冲区来缓存序列化后的数据,然后再往真正的目标Buffer里写,在写的时候会维护两个“指针”:一个是表示目标Buffer内存段长度的limit,还有一个是表示其当前写入位置的position。因为一个Buffer对应着一个内存段,当将数据序列化并存入内存段时,其空间有可能有剩余也有可能不够。因此,RecordSerializer定义了一个表示序列化结果的SerializationResult枚举。它提供了这么几个枚举值:
- PARTIAL_RECORD_MEMORY_SEGMENT_FULL:内存段已满但记录的数据只写入了部分,没有完全写完;
- FULL_RECORD_MEMORY_SEGMENT_FULL:内存段写满,记录的数据已全部写入;
- FULL_RECORD:记录的数据全部写入,但内存段并没有满;
一个记录的序列化过程通常由setNextBuffer和addRecord这两个方法共同配合完成。其中setNextBuffer方法的主要作用是重新初始化一个新的Buffer作为目标Buffer并刷出剩余数据;而addRecord方法则主要用于进行真正的序列化操作。这两个方法的调用结果都返回的是SerializationResult。那么具体的序列化结果是如何判断的呢?这个逻辑由getSerializationResult方法完成:
private SerializationResult getSerializationResult() {
//如果数据buffer中已没有更多的数据且长度buffer里也没有更多的数据,该判断可确认记录数据已全部写完
if (!this.dataBuffer.hasRemaining() && !this.lengthBuffer.hasRemaining()) {
//紧接着判断写入位置跟内存段的结束位置之间的关系,如果写入位置小于结束位置,则说明数据全部写入,
//否则说明数据全部写入且内存段也写满
return (this.position < this.limit)
? SerializationResult.FULL_RECORD
: SerializationResult.FULL_RECORD_MEMORY_SEGMENT_FULL;
}
//任何一个buffer中仍存有数据,则记录只能被标记为部分写入
return SerializationResult.PARTIAL_RECORD_MEMORY_SEGMENT_FULL;
}
下面我们来分析记录反序列化器(RecordDeserializer)。跟RecordSerializer类似,考虑到记录的数据大小以及Buffer对应的内存段的容量大小。在反序列化时也存在不同的反序列化结果,以枚举DeserializationResult表示:
- PARTIAL_RECORD:表示记录并未完全被读取,但缓冲中的数据已被消费完成;
- INTERMEDIATE_RECORD_FROM_BUFFER:表示记录的数据已被完全读取,但缓冲中的数据并未被完全消费;
- LAST_RECORD_FROM_BUFFER:记录被完全读取,且缓冲中的数据也正好被完全消费;
RecordDeserializer接口有两个实现,分别是:
- AdaptiveSpanningRecordDeserializer:适用于数据大小适中且跨段的记录的反序列化;
- SpillingAdaptiveSpanningRecordDeserializer:适用于数据大小相对较大且跨段的记录的反序列化,它支持将溢出的数据写入临时文件;
这两个实现在内部都某种程度上依赖于特定的数据输入视图(DataInputView),完整的类图如下:
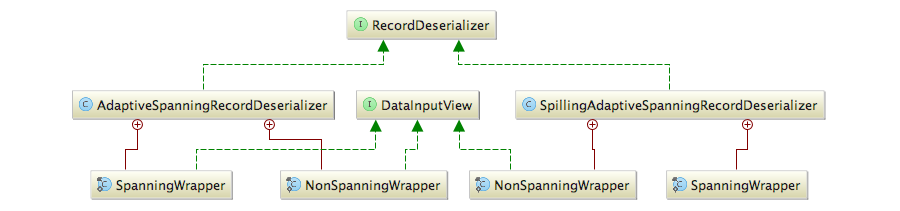
每个反序列化器内部都各自实现了跨段数据读取包装器和不跨段的数据读取包装器,其中跨段的数据读取包装器都依赖各自的不跨段的读取包装器。将Buffer中的数据反序列化为记录由getNextRecord方法和setNextBuffer方法协作完成。getNextRecord方法会传入目标记录的引用并在内部将数据填入目标记录。
虽然不同的反序列化器有各自适用的场景,但它们的实现绝大部分是类似的,主要的差别在于两者对SpanningWrapper的实现上。AdaptiveSpanningRecordDeserializer主要应用了临时缓冲区在内存中处理跨段数据的读取,而SpillingAdaptiveSpanningRecordDeserializer则有一个溢出阈值(5MB),如果记录的数据大于这个阈值将会采用临时文件来将溢出数据写入到临时文件中,然后再从溢出文件对应的文件流构建数据输入视图(DataInputViewStreamWrapper)进行读取。由于支持大记录的SpillingAdaptiveSpanningRecordDeserializer在数据大小不大于溢出阈值时处理方式跟AdaptiveSpanningRecordDeserializer类似,所以SpillingAdaptiveSpanningRecordDeserializer能适应更一般的场景,更具实用性,这也导致了在源码中没有见到AdaptiveSpanningRecordDeserializer的使用踪迹。
除了记录序列化器与反序列化器之外,Flink为事件也提供了序列化器来进行序列化和反序列化操作。事件序列化器(EventSerializer)可将事件在AbstractEvent跟Buffer、ByteBuffer的表示之间进行转换。Flink为其所支持的事件类型进行了编号,这些事件大致分为如下几种:
- EndOfPartitionEvent:分区数据写入结束事件,类型编号为0;
- CheckpointBarrier:检查点屏障事件,类型编号为1;
- EndOfSuperstepEvent:超步结束事件,类型编号为2;
- 其他事件类型统一都编号为3;
事件被序列化为二进制表示时,首先写入事件编号,然后再写入具体数据。从二进制再反序列化为事件对象表示时,首先读取一个整形的字节数,也就是先读取事件类型编号,然后根据不同编号的事件针对性处理。
写入器
在通信层API提供了两种写入器,分别是记录写入器(RecordWriter)以及结果分区写入器(ResultPartitionWriter)。这两个写入器的主要差别是它们所面向的层级不同。RecordWriter面向记录,而ResultPartitionWriter面向的是Buffer,下面我们会分别对这两种写入器进行介绍。
RecordWriter相比ResultPartitionWriter所处的层面更高,并且它依赖于ResultPartitionWriter,所以我们先分析ResultPartitionWriter。一个ResultPartitionWriter通常负责为一个ResultPartition特定子分区生产Buffer和Event。同时还提供了将特定的事件广播到所有的子分区中的方法。
接下来,我们将关注点回到RecordWriter上来,记录写入器是对我们上文分析的ResultPartitionWriter进行了包装,同时添加了对记录的序列化功能,以使其可被放入Buffer。在构建RecordWriter时,允许指定通道选择器(ChannelSelector)。
所谓的通道选择器允许用户自定义某个记录的要存放在哪个输出通道中,如果不指定,那么Flink将会选择简单的顺序轮转选择器(RoundRobinChannelSelector)。
在RecordWriter被初始化时,它所对应的ResultPartition的每个ResultSubpartition(输出信道)都会有对应一个独立的RecordSerializer,具体的类型是我们之前分析的SpanningRecordSerializer。
RecordWriter会接收要写入的记录然后借助于ResultPartitionWriter将序列化后的Buffer写入特定的ResultSubpartition中去。它提供了单播、广播的写入方式,支持记录、事件的写入。
我们主要分析一下写入单个记录的emit方法的实现:
public void emit(T record) throws IOException, InterruptedException {
//遍历通道选择器选择出的通道(有可能选择多个通道),所谓的通道其实就是ResultSubpartition
for (int targetChannel : channelSelector.selectChannels(record, numChannels)) {
//获得当前通道对应的序列化器
RecordSerializer<T> serializer = serializers[targetChannel];
synchronized (serializer) {
//向序列化器中加入记录,加入的记录会被序列化并存入到序列化器内部的Buffer中
SerializationResult result = serializer.addRecord(record);
//如果Buffer已经存满
while (result.isFullBuffer()) {
//获得当前存储记录数据的Buffer
Buffer buffer = serializer.getCurrentBuffer();
//将Buffer写入ResultPartition中特定的ResultSubpartition
if (buffer != null) {
writeBuffer(buffer, targetChannel, serializer);
}
//向缓冲池请求一个新的Buffer
buffer = writer.getBufferProvider().requestBufferBlocking();
//将新Buffer继续用来序列化记录的剩余数据,然后再次循环这段逻辑,直到数据全部被写入Buffer
result = serializer.setNextBuffer(buffer);
}
}
}
}
从上述代码段中我们可以看到,如果记录的数据无法被单个Buffer所容纳,将会被拆分成多个Buffer存储,直到数据写完。而如果是广播记录或者广播事件,整个过程也是类似的,只不过变成了挨个遍历写入每个ResultSubpartition,而不是像上面这样通过通道选择器来选择。
当所有数据都写入完成后需要调用flush方法将可能残留在序列化器Buffer中的数据都强制输出。flush方法会遍历每个ResultSubpartition,然后依次取出该ResultSubpartition对应的序列化器,如果其中还有残留的数据,则将数据全部输出。这也是每个ResultSubpartition都对应一个序列化器的原因。
读取器
写入器负责将生产者任务产生的中间结果数据写入到ResultSubpartition供消费者任务消费,而读取器则读取消费者任务所消费的数据并反序列化为记录。
读取器有着比写入器相对复杂的设计,总得来说可以按照两个维度来进行分类:
- 层级:底层的Buffer读取器(BufferReader)和高层的记录读取器(RecordReader);
- 可变性:不可变记录读取器(RecordReader)和可变记录读取器(MutableRecordReader);
整体的类关系图如下:
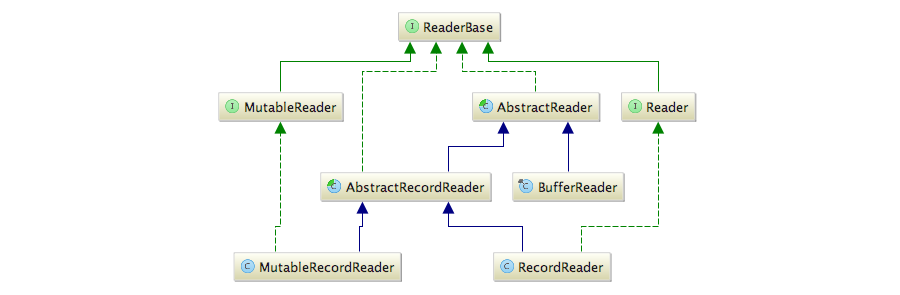
这其中,最关键的是两个抽象类:AbstractReader和AbstractRecordReader。从类图来看,AbstractReader提供了最基础的实现。在分析写入器时,每个写入器都关联着结果分区(ResultPartition)。相应地,每个读取器也关联着对等的输入网关(InputGate)。AbstractReader主要对读取到的事件提供处理,以下代码段是处理事件的主逻辑:
protected boolean handleEvent(AbstractEvent event) throws IOException {
final Class<?> eventType = event.getClass();
try {
//如果事件为消费完的特定结果子分区中的数据,则直接返回true
if (eventType == EndOfPartitionEvent.class) {
return true;
}
//如果事件是针对迭代的超步完成,则增加相应的超步完成计数
else if (eventType == EndOfSuperstepEvent.class) {
return incrementEndOfSuperstepEventAndCheck();
}
//如果事件是TaskEvent,则直接用任务事件处理器发布
else if (event instanceof TaskEvent) {
taskEventHandler.publish((TaskEvent) event);
return false;
}
else {
throw new IllegalStateException("Received unexpected event of type "
+ eventType + " at reader.");
}
}
catch (Throwable t) {
throw new IOException("Error while handling event of type " + eventType + ": " + t.getMessage(), t);
}
}
AbstractReader对迭代的超步提供了统计,它内部维护了一个超步事件计数器currentNumberOfEndOfSuperstepEvents。这一点的实现跟检查点的屏障对齐机制类似。当计数器跟InputGate所包含的InputChannel数量相等时,说明超步事件已到达每个InputChannel,则可认为超步结束。
接下来我们来分析直接继承自AbstractReader的面向Buffer的读取器BufferReader。其主要借助于AbstractReader的handleEvent方法对事件进行处理,而对于普通的数据Buffer则直接放行。
public BuffergetNextBuffer()throwsIOException, InterruptedException{
while (true) {
final BufferOrEvent bufferOrEvent = inputGate.getNextBufferOrEvent();
if (bufferOrEvent.isBuffer()) {
returnbufferOrEvent.getBuffer();
}
else {
if (handleEvent(bufferOrEvent.getEvent())) {
return null;
}
}
}
}
从以上代码段中可见,代码逻辑处于 while(true) 块中。因此当调用handleEvent方法返回false时将会重复从InputGate里获取Buffer并处理。
分析完了面向Buffer的读取器BufferReader,接下来我们来分析面向记录的读取器。面向记录的读取器分为可变记录和不可变记录读取器。无论是哪种读取器都继承自AbstractRecordReader。记录读取器需要从二进制表示反序列化为记录,这依赖于我们之前分析的反序列化器。正如我们在分析序列化时所提及的,反序列化器的实例对应着InputChannel的实例。记录读取器关联着InputGate,因而它内部维护了一组反序列化器,且反序列化器类型为支持大记录溢出到磁盘的SpillingAdaptiveSpanningRecordDeserializer。
接下来,我们来看一下它获得记录的getNextRecord方法的实现,它是可变记录读取器和非可变记录读取器的基础,其返回值是一个布尔值表示是否还有下一条记录。
protected booleangetNextRecord(Ttarget)throwsIOException, InterruptedException{
if (isFinished) {
return false;
}
while (true) {
//如果当前反序列化器已被初始化,说明它当前正在序列化一个记录
if (currentRecordDeserializer != null) {
//以当前反序列化器对记录进行反序列化,并返回反序列化结果枚举DeserializationResult
DeserializationResult result = currentRecordDeserializer.getNextRecord(target);
//如果获得结果是当前的Buffer已被消费(还不是记录的完整结果),获得当前的Buffer,将其回收,
//后续会继续反序列化当前记录的剩余数据
if (result.isBufferConsumed()) {
final Buffer currentBuffer = currentRecordDeserializer.getCurrentBuffer();
currentBuffer.recycle();
currentRecordDeserializer = null;
}
//如果结果表示记录已被完全消费,则返回true,跳出循环
if (result.isFullRecord()) {
return true;
}
}
//从输入闸门获得下一个Buffer或者事件对象
final BufferOrEvent bufferOrEvent = inputGate.getNextBufferOrEvent();
//如果是Buffer
if (bufferOrEvent.isBuffer()) {
//设置当前的反序列化器,并将当前记录对应的Buffer给反序列化器
currentRecordDeserializer = recordDeserializers[bufferOrEvent.getChannelIndex()];
currentRecordDeserializer.setNextBuffer(bufferOrEvent.getBuffer());
}
else {
//如果不是Buffer而是事件,则根据其对应的通道索引拿到对应的反序列化器判断其是否还有未完成的数据,
//如果有则抛出异常,因为这是一个新的事件,在处理它之前,反序列化器中不应该存在残留数据
if (recordDeserializers[bufferOrEvent.getChannelIndex()].hasUnfinishedData()) {
throw new IOException(
"Received an event in channel " + bufferOrEvent.getChannelIndex()
+ " while still having "
+ "data from a record. This indicates broken serialization logic. "
+ "If you are using custom serialization code (Writable or Value types), check their "
+ "serialization routines. In the case of Kryo, check the respective Kryo serializer.");
}
//处理事件,当该事件表示分区的子分区消费完成或者超步整体结束
if (handleEvent(bufferOrEvent.getEvent())) {
//如果是整个ResultPartition都消费完成
if (inputGate.isFinished()) {
isFinished = true;
return false;
}
//否则判断如果到达超步尾部
else if (hasReachedEndOfSuperstep()) {
return false;
}
//剩下的可能就是还有部分结果分区的子分区没有消费完成
}
}
}
}
可变记录读取器和不可变记录读取器的差别是:不可变记录读取器的getNextRecord方法的record参数是其内部实例化的而可变记录读取器中该引用是外部提供的。事实上,Flink源码中没有找到可变记录读取器(RecordReader)的使用场景。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

