Keras 教程: Python 深度学习终极入门指南
事实上, 我们将利用著名的 MNIST 数据集, 训练一个准确度超过 99% 的手写数字分类器.
开始之前, 请注意, 本指南是面向对应用深度学习感兴趣的初学者的.
我们旨在向你介绍一个最流行的同时也是功能最强大的, 用于建立神经网络的 Python 库. 这意味着我们将跳过许多理论与数学知识, 但我们还是会向你推荐一些学习这些的极好的资源.

开始之前
推荐的预备知识
本指南推荐的预备知识有:
机器学习的基本概念
Python 编程技能
为了能快速开始, 我们假设你已经具备了这方面的知识.
为什么要用 Keras?
Keras 是我们推荐的 Python 深度学习库, 尤其是对于初学者而言. 它很简约, 模块化的方法使建立并运行神经网络变得轻巧. 你可以在这里读到更多关于 Keras 的内容:
Keras, Python 的深度学习库
深度学习究竟是什么?
深度学习是指具有多隐层的神经网络, 其可以学习输入数据的抽象表示. 这个定义显然太简单了, 但对于现在的我们来说, 却是最有实际意义的.
比方说, 深度学习促进了计算机视觉的巨大进步. 现在, 我们能够对图片进行分类, 识别图片中的物体, 甚至给图片打标签. 要实现这些, 多隐层的深度神经网络可以从原始输入图片中按序学习更复杂的特征:
第一层隐层也许只能学习到局部边缘模式.
之后, 每一个后续层 (或过滤器) 将学习更复杂的表示.
最后, 最后一层可以对图片进行分类, 是猫还是袋鼠.
这类深度神经网络就称为卷积神经网络.
卷积神经网络究竟是什么?
简而言之, 卷积神经网络 (CNN) 就是将输入数据假设成图的多层神经网络 (有些时候, 会有多达 17 甚至更多层).
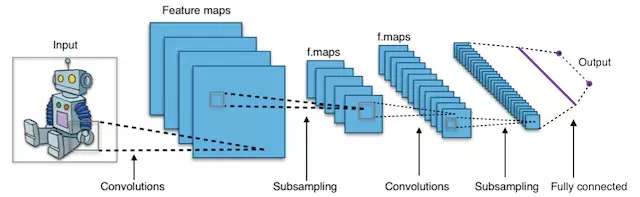
通过实现这个需求, CNN 可以大大减少需要调整的参数数量. 因此, CNN 可以高效处理高维原始图片.
卷积神经网络的底层机制已经超过了本教程的范围, 更多请看这里.
本教程不是什么:
这不是一门深度学习的完整课程. 相反地, 本教程旨在带你从零到一, 尽量”无痛”地建立卷积神经网络!
如果你有兴趣掌握深度学习背后的理论, 强烈推荐斯坦福大学的这门课:
CS231n: Convolutional Neural Networks for Visual Recognition
开始前的小提示:
我们试着让教程尽可能流线化, 这意味着任何一个主题, 我们都不会太深究细节. 万一你想要学习关于一个函数或模块更多的知识, 同时打开 Keras 文档 很有帮助.
Keras 教程目录
下面是创建你的第一个卷积神经网络 (CNN) 的步骤:
配置环境
安装 Keras
导入库和模块
从 MNIST 导入图片数据
预处理输入数据
预处理类标签
定义模型架构
编译模型
用训练数据拟合模型
用测试数据评估模型
第一步: 配置环境
首先, 挂一张励志海报:

可能没什么用- -.
然后, 确保你的计算机上已经安装了以下软件:
Python 2.7+ (Python 3 也可以, 但总体而言, Python 2.7 在数据科学领域依旧更受欢迎.)
Scipy 和 NumPy
Matplotlib (可选的, 推荐用于探索性分析)
Theano* (安装指南)
强烈建议使用 Anaconda 发行版 来安装 Python, NumPy, SciPy. 它自带所有这些包.
注意: 用 TensorFlow 也可以 (作为 Theano 的替代), 但我们将坚持使用 Theano, 以保持程序足够简单. 使用 TensorFlow 和 Theano 的主要区别在于, 数据输入神经网络之前, 需要简单地重塑.
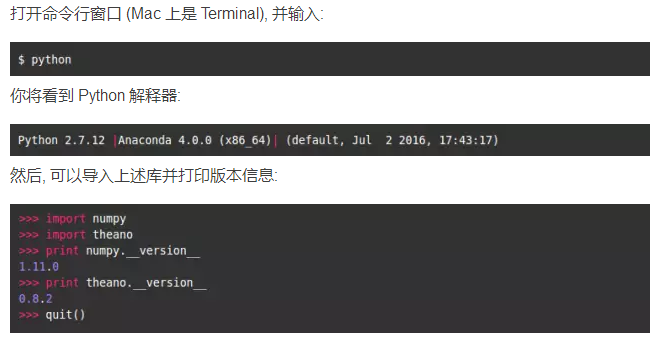
你可以检查一下是否都正确安装了:
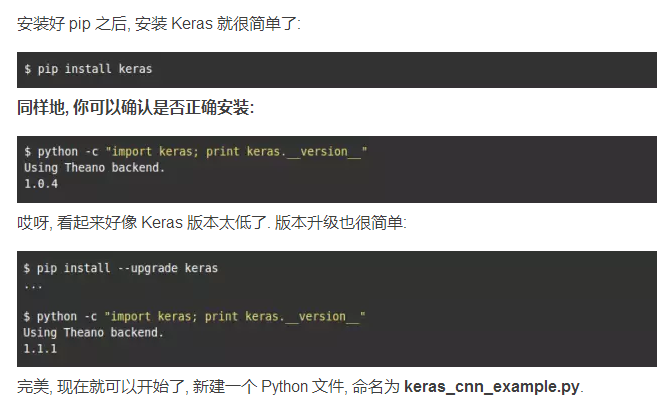
第二步: 安装 Keras
如果我们没有涵盖如何安装 Keras, 这就不是一篇 Keras 的教程.
好消息是, 如果你使用的 Anaconda, 你已经安装好了一个超赞的包管理系统: pip.
你可以在命令行输入 $ pip 确认安装. 这条命令将打印一个命令和选项的列表. 如果你还没有安装 pip, 参照这里进行安装.
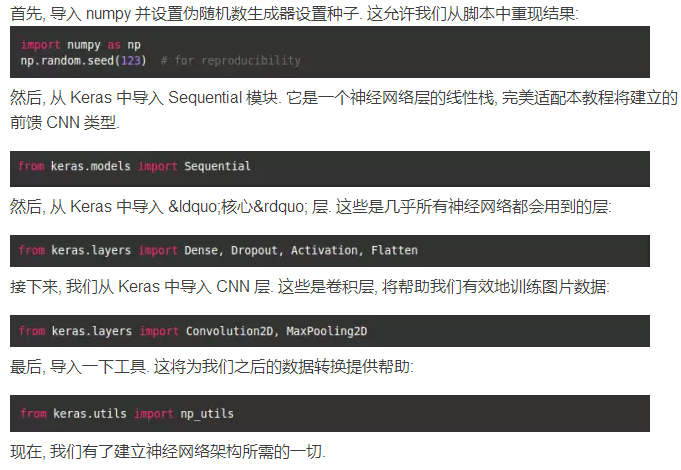
第三步: 导入库和模块
第四步: 从 MNIST 加载图片数据
MNIST 是深度学习和计算机视觉入门很好的数据集. 它很大, 这对于神经网络是一个巨大的挑战, 但它在单台计算机上又是可管理的. 我们将在另一个文章中对此进行更多的讨论: 6 Fun Machine Learning Projects for Beginners.
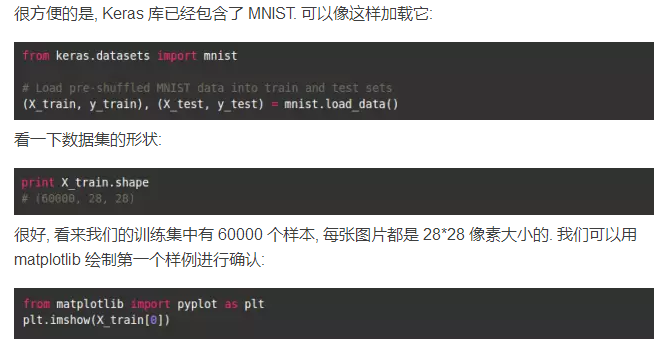
输出的图片是这样的:
总的来说, 做计算机视觉的, 在进行任何算法工作之前, 可视地绘制数据很有帮助. 这是一个快速明智的检查, 可以防止可避免的错误 (比如对数据维度的误解).
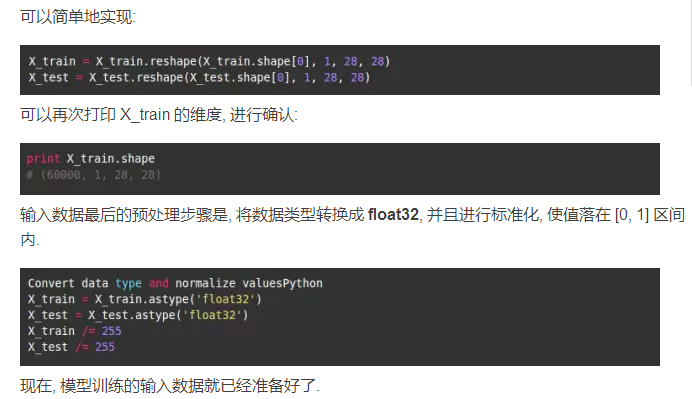
第五步: 输入数据预处理
在后端使用 Theano 时, 你必须显式地声明一个维度, 用于表示输入图片的深度. 举个例子, 一幅带有 RGB 3 个通道的全彩图片, 深度为 3.
MNIST 图片的深度为 1, 因此必须显式地进行声明.
换言之, 我们要将数据集从 (n, width, height) 转换成 (n, depth, width, height).
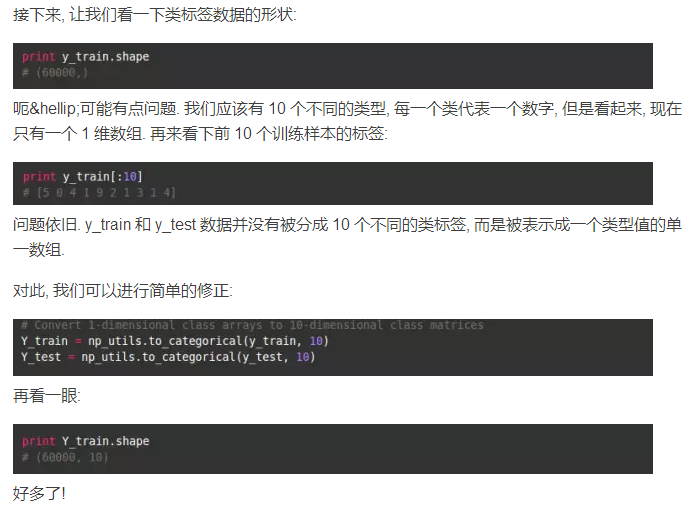
第六步: 预处理类标签
第七步: 定义模型架构
现在, 我们就可以定义我们的模型架构了. 在实际研发工作中, 研究员会花大量的时间研究模型架构.
在这里, 为了教程的继续, 我们不会讨论理论或数学. 这本身就是复杂的领域, 对于想要深入学习的同学, 建议看一下上文提到的 CS231n 课程.
另外, 刚开始时, 你可以使用现成的例子或者实现紫黯学术论文中已经证明的架构. 这里有一个 Keras 实现样例.
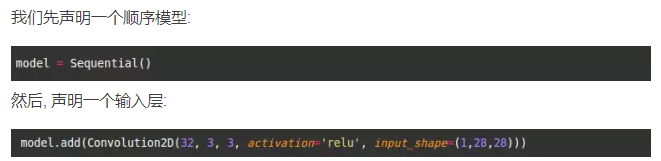
输的形状参数应为形状为 1 的样例. 本例中, 就是 (1, 28, 28), 与每张数字图片的 (depth, width, height) 相对应.
但是前 3 个参数又代表什么呢? 它们分别对应于要使用的卷积过滤器的数量, 每个卷积内核的行数与列数.
注意: 默认情况下, 步长为 (1, 1), 可以用 ‘subsample’ 参数进行调整.
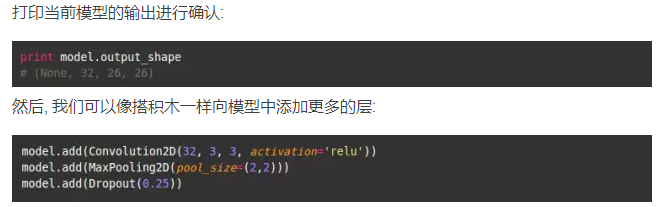
再次声明, 我们不会太深究理论的东西, 但有必要强调一下我们刚刚添加的 Dropout 层. 这是一个规范化模型的方法, 目的是防止过度拟合. 你可以在这里看到更多内容.
MaxPooling2D 是一种减少模型参数数量的方式, 其通过在前一层上滑动一个 2*2 的滤波器, 再从这个 2*2 的滤波器的 4 个值中取最大值.
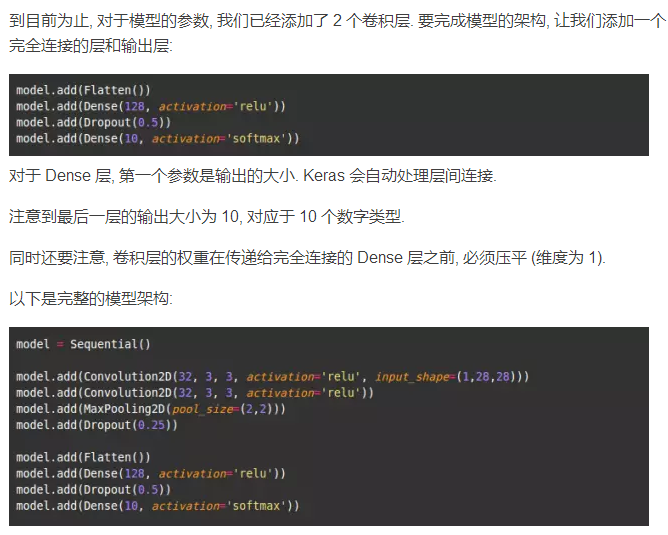
现在, 我们唯一需要做的就是定义损失函数和优化器, 然后就可以对模型进行训练了.
第八步: 编译模型
现在可以轻松一点了, 最难的部分已经过去了.
只需要编译模型, 然后我们就可以训练它了. 编译模型时, 我们需要声明损失函数和优化器 (SGD, Adam 等等).

Keras 有各种各样的 损失函数和开箱即用的优化器.
第九步: 用训练数据进行模型拟合
要拟合模型, 我们需要做的就是声明训练的批次大小以及训练次数, 然后传入训练数据.

简单吗?
你也可以使用各种回调函数来设置提前结束的规则, 保存模型权重, 或记录每次训练的历史.
第十步: 用测试数据评估模型
最后, 可以用测试数据对模型进行评估:

恭喜! 你已经完成了本 Keras 教程.
我们刚刚体验了 Keras 的核心功能, 但也仅仅是体验. 希望通过本教程, 你已经获得了进一步探索 Keras 所有功能的基础.
如果希望继续学习, 我们推荐学习其他的 Keras 样例模型 和斯坦福大学的计算机视觉课程.
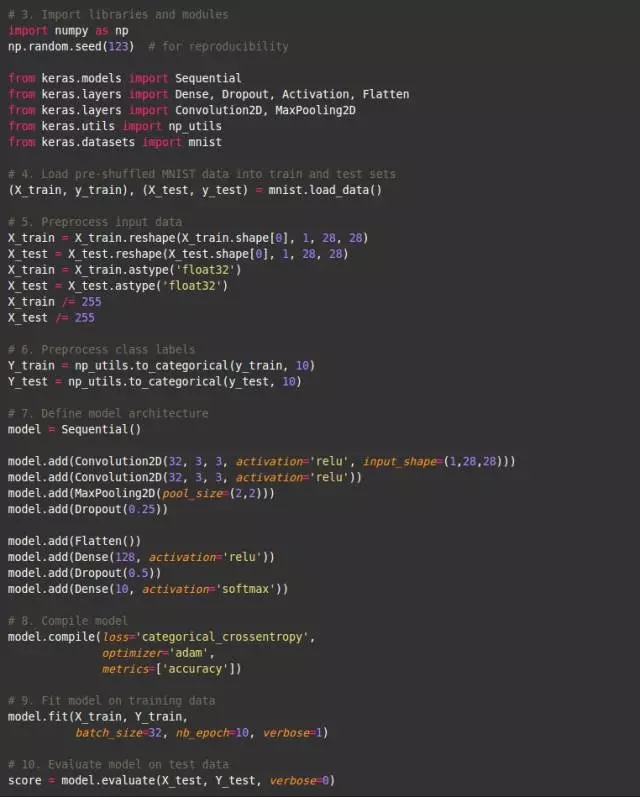
完整的代码
以下就是本教程的所有代码, 保存为一个脚本:
英文原文:https://elitedatascience.com/keras-tutorial-deep-learning-in-python
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

