一个执行计划异常变更的案例 - 外传之查询执行计划的几种方法
之前的几篇文章:
《一个执行计划异常变更的案例 - 前传》
《一个执行计划异常变更的案例 - 外传之绑定变量窥探》
《一个执行计划异常变更的案例 - 外传之查看绑定变量值的几种方法》
《一个执行计划异常变更的案例 - 外传之rolling invalidation》
《一个执行计划异常变更的案例 - 外传之聚簇因子(Clustering Factor)》
本篇外传主要介绍一些常用的执行计划查看方法。
SQL的执行计划实际代表了目标SQL在Oracle数据库内部的具体执行步骤,作为调优,只有知道了优化器选择的执行计划是否为当前情形下最优的执行计划,才能够知道下一步往什么方向。
执行计划的定义:执行目标SQL的所有步骤的组合。
有很多查看执行计划的方法,不仅局限于以下几种。
方法1 explain plan命令
PL/SQL Developer中通过快捷键F5就可以查看目标SQL的执行计划了。但其实按下F5后,实际后台调用的就是explain plan命令,相当于封装了该命令。
explain plan使用方法:
(1) 执行explain plan for + SQL
(2) 执行select * from table(dbms_xplan.display);
实验表准备:
SQL> desc test1;
Name Null Type
----------------------------------------- -------- ----------------------------
T1ID NOT NULL NUMBER(38)
T1V VARCHAR2(10)
SQL> desc test2;
Name Null Type
----------------------------------------- -------- ----------------------------
T2ID NOT NULL NUMBER(38)
T2V VARCHAR2(10)
实验:
SQL> set linesize 100
SQL> explain plan for select t1id, t1v, t2id, t2v from test1, test2 where test1.t1id = test2.t2id;
Explained.
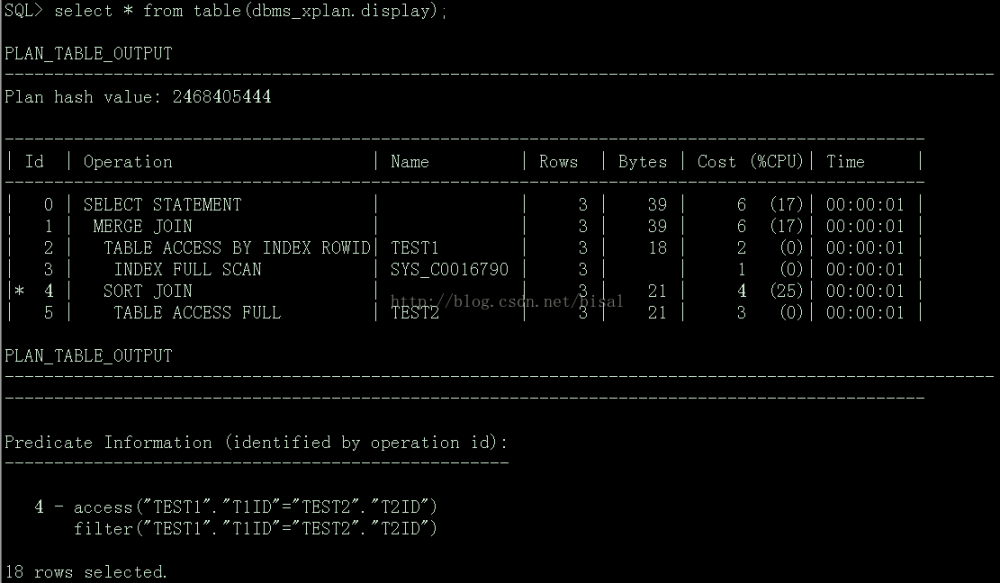
第一步使用explain plan对目标SQL进行了explain,第二步使用select * from table(dbms_xplan.display)语句展示出该SQL的执行计划。
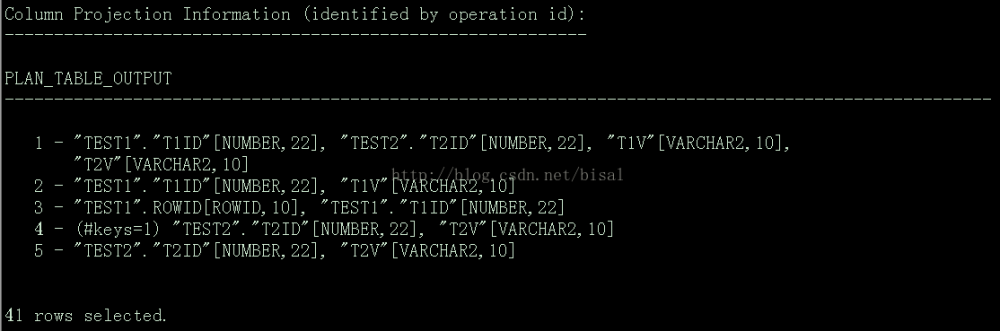
这里test2进行了全表扫描,test1由于其包含主键,所以用的是索引全扫描。左侧ID带*号的第四步操作,表示有谓词条件,这里可以看到既使用了主键索引(access),又使用了过滤条件(filter)。
方法2 DBMS_XPLAN包
(1) select * from table(dbms_xplan.display);
(2) select * from table(dbms_xplan.display_cursor(null, null, 'advanced'));
(3) select * from table(dbms_xplan.display_cursor('sql_id/hash_value', child_cursor_number, 'advanced'));
(4) select * from table(dbms_xplan.display_awr('sql_id'));
(1) select * from table(dbms_xplan.display);
方法1已说明。
(2) select * from table(dbms_xplan.display_cursor(null, null, 'advanced'));
主要用于SQLPLUS中查看刚执行过SQL的执行计划。首先第三个参数可以选择'advanced':

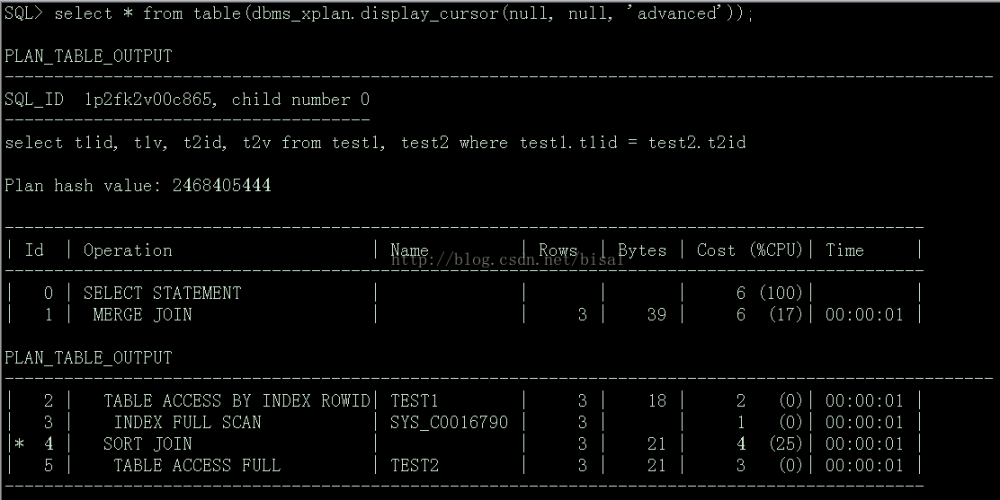
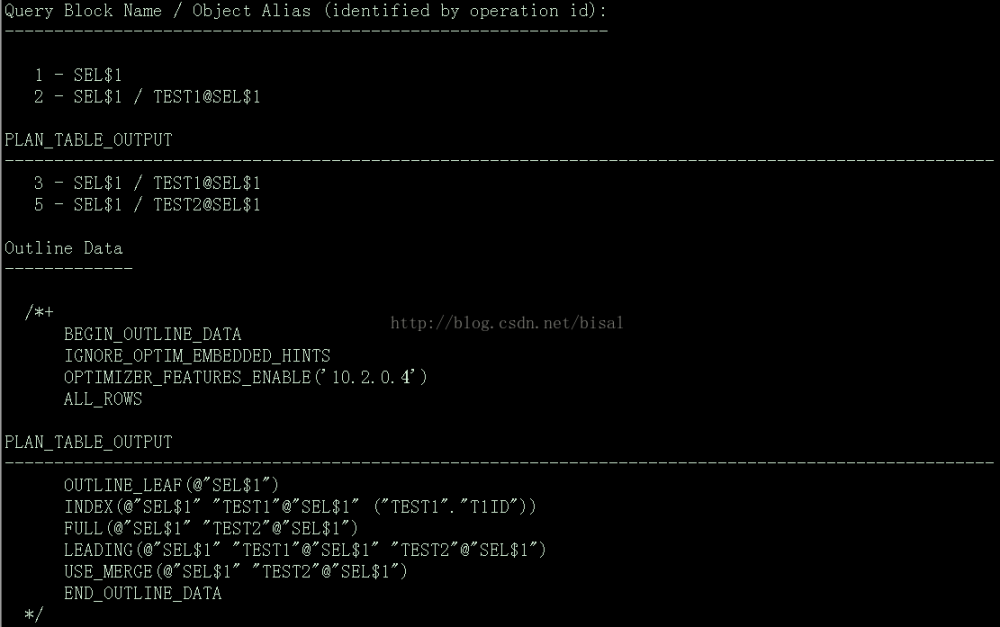
接下来,第三个参数使用'all':
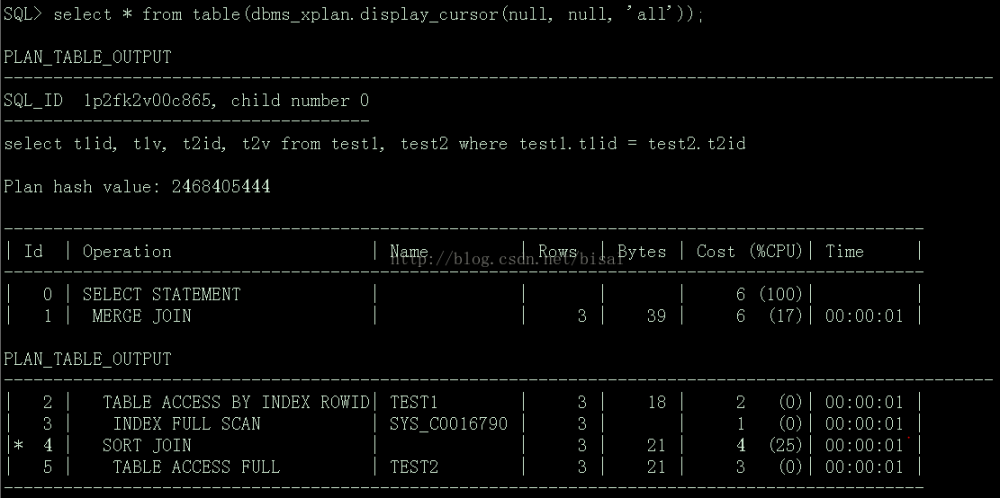

可以看出'advanced'记录的信息要比'all’多,主要就是多一个Outline Data。Outline Data主要是执行SQL时用于固定执行计划的内部HINT组合,可以将这部分内容摘出来加到目标SQL中以固定其执行计划。
(3) select * from table(dbms_xplan.display_cursor('sql_id/hash_value', child_cursor_number, 'advanced'));
其中第一个参数可以输入SQL的sql_id或hash value,方法就是如果执行的SQL仍在库缓存中,则可以使用V$SQL查询:

其中,使用dbsnake书中介绍的SQL可以知道SQL_ID和HASH_VALUE的一一对应关系:

使用:
select * from table(dbms_xplan.display_cursor('1p2fk2v00c865', 0, 'advanced'));
或
select * from table(dbms_xplan.display_cursor('3221627077', 0, 'advanced'));
就可以查出对应这条SQL的执行计划,内容同(2)中的'advanced',这就不展示了。
注意这还有第二个参数child_cursor_number,指的是子游标编号,如果未生成新的子游标,则此处写的是0。
(2)和(3)的结论相近,区别就是(2)只是针对最近一次执行SQL查看执行计划,(3)可以针对仍在库缓存中的任意一次SQL查看执行计划。
(4) select * from table(dbms_xplan.display_awr('sql_id'));
上面介绍的方法中,(1)是使用explain plan for +SQL作为前提,(2)和(3)的前提则是SQL的执行计划还在共享池中,具体讲是在库缓存中。如果已经被age out交换出共享池,则不能用这两种方法了。若该SQL的执行计划被采集到AWR库中,则可以用(4)来查询历史执行计划。
注:
《一个执行计划异常变更的案例 - 外传之查看绑定变量值的几种方法》曾介绍了使用这篇文章《How to Control the Set of Top SQLs Captured During AWR Snapshot Generation (文档 ID 554831.1)》中的方法,修改AWR采集topnsql参数,换句话说,不会所有的SQL都会被捕获至AWR中,因此方法(4)有可能存在查询不出结果的情况。
方法3 AUTOTRACE开关

SQLPLUS中打开AUTOTRACE开关可以得到SQL的执行计划。
从提示可以看到AUTOTRACE有几个选项:
OFF/ON/TRACEONLY/EXPLAIN/STATISTICS。
实验:
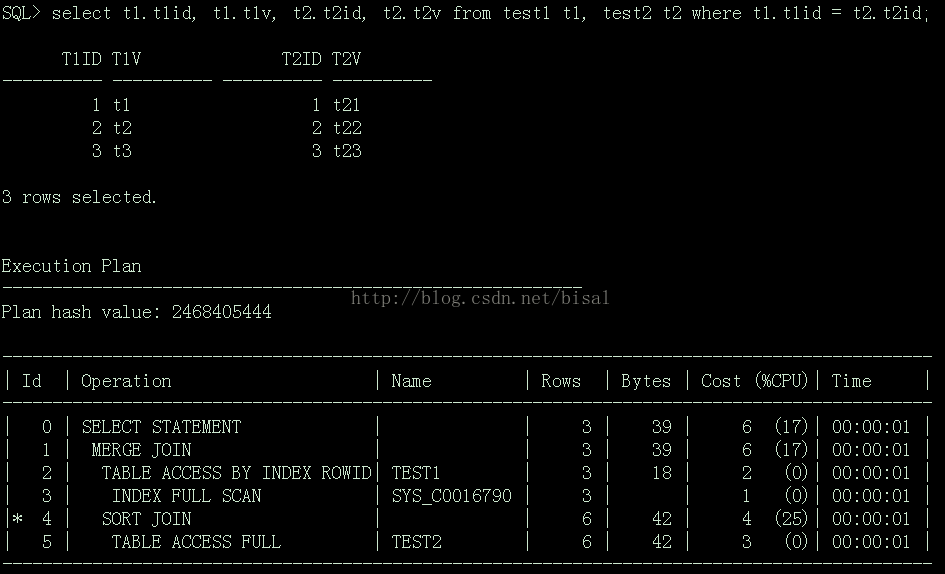
1. 执行SET AUTOTRACE ON:

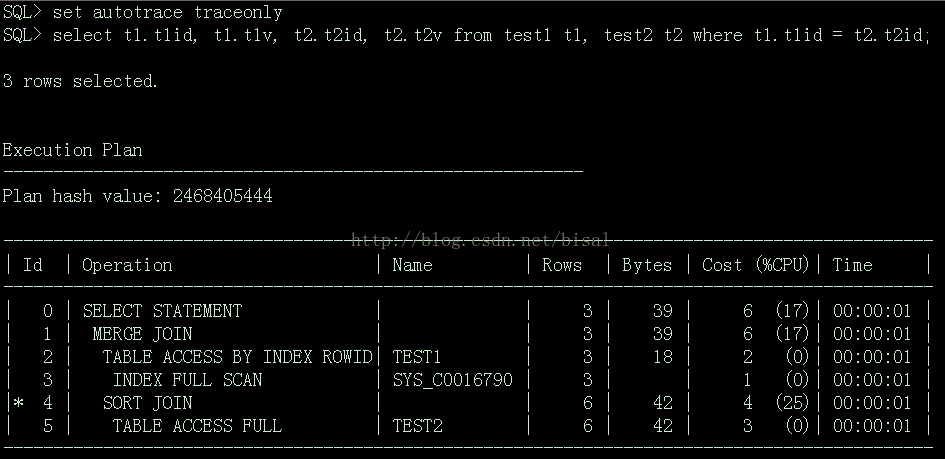
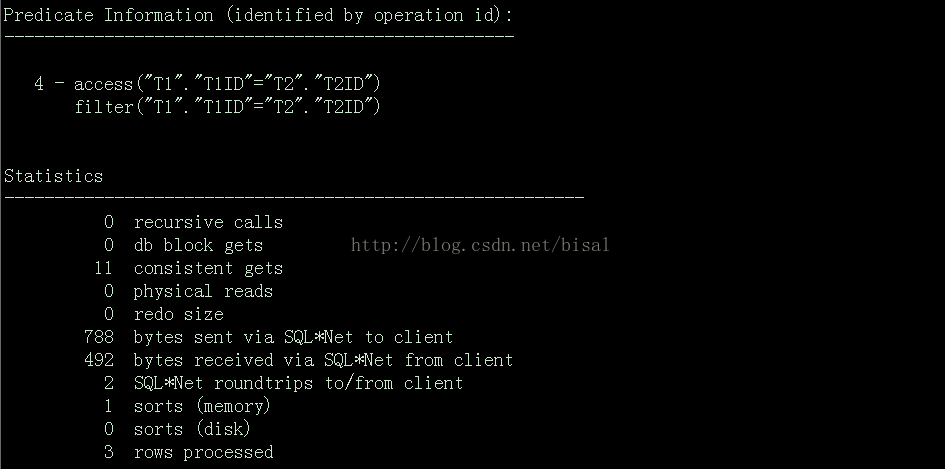
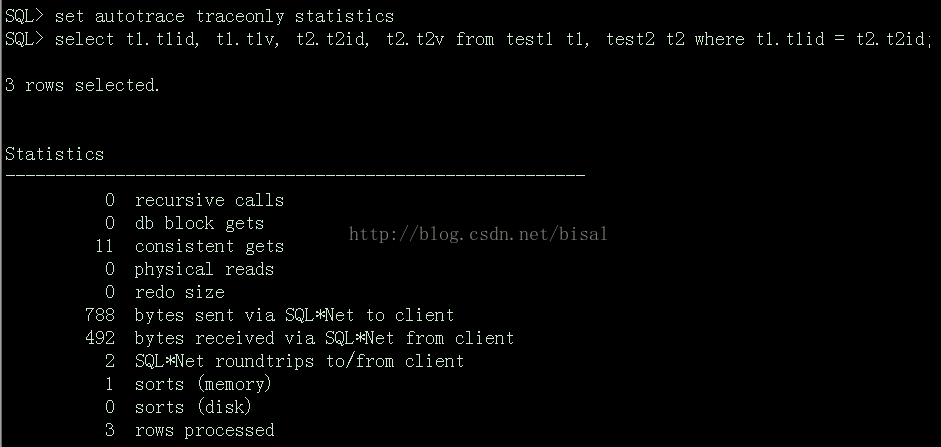
2. 执行SET AUTOTRACE TRACEONLY:
3. 执行SET AUTOTRACE TRACEONLY EXPLAIN:

4. 执行SET AUTOTRACE TRACEONLY STATISTICS:
AUTOTRACE开关小结:
OFF:默认选项,当前session执行SQL只会显示结果。
SET AUTOTRACE OFF(SET AUTOT OFF)
ON:除显示执行SQL结果外,还会显示对应的执行计划和资源消耗。
SET AUTOTRACE ON(SET AUTOT ON)
ON:除显示执行SQL结果外,还会显示对应的执行计划和资源消耗。
SET AUTOTRACE ON(SET AUTOT ON)
TRACEONLY:只会显示SQL执行结果的数量,不显示执行结果的内容,适用于刷屏的SQL,还会显示执行计划和资源消耗。
SET AUTOTRACE TRACEONLY(SET AUTOT TRACE)
EXPLAIN:只显示SQL执行计划,不显示SQL的资源消耗和执行结果。
SET AUTOTRACE TRACEONLY EXPLAIN(SET AUTOT TRACE EXP)
STATISTICS:只显示SQL的执行结果数量和资源消耗,不显示执行计划。
SET AUTOTRACE TRACEONLY STATISTICS(SET AUTOT TRACE STAT)
方法4 10046事件
通过10046事件也可以查看目标SQL的执行计划。像10046这种事件,都不是Oracle官方文档中可以查询到的,这些事件一般用于调试目的,因此往往可以使用他们找到问题更详细的信息。
10046事件和之前的explain plan、DBMS_XPLAN包以及AUTOTRACE开关的区别在于,10046事件产生的trc文件中明确显示了目标SQL实际执行计划中每一步所消耗的逻辑读、物理读和花费的时间,执行计划的成本分析,进而可以看出为什么Oracle对于SQL选择了这样的执行计划,而不是那样的执行计划,之所以说是实际的执行计划,从10046事件执行的过程就可以看出来:
(a) 在当前session激活10046事件。
(b) 在此session中执行SQL。
(c) 关闭此session的10046事件。
真正执行的SQL,对应的执行计划可以在trc文件中找到。这个trc文件会记录SQL的执行计划和资源消耗,命名格式“实例名_ora_当前session的spid.trc”。
(1). 激活10046事件:
有两种方法:
(a) alter session set events '10046 trace name context forever, level 12';
(b) oradebug setmypid/oradebug setospid SPID;
oradebug event 10046 trace name context forever, level 12;
(2). 查看10046产生的trc文件名和路径的方法:
(a) show parameter USER_DUMP_DEST显示trc文件存储的路径 -> 查找对应当前session的trc文件(若当前是单用户,则是最新产生的文件)。
实验:

(b) 使用上述(1)-(b)的ordebug产生trc文件,可以用oradebug tracefile_name得到trc文件名和路径。
oradebug有很多需要说的,首先这是sqlplus特有的命令,在PLSQL Developer中执行会提示无效的SQL语句,例如:
其次它是sysdba角色的命令,使用非sysdba执行会提示ORA-01031权限不足,例如:

使用sysdba登录后,可以查看oradebug的帮助:

尽管oradebug用的时候需要使用sysdba登录,看似有些麻烦,但和第一种alter session的方法相比,最大的好处就是alter session只能针对当前会话或系统级,即alter session或alter system设置,如果设置非本会话的跟踪,此时就可以用oradebug了,(据说dbms_system、dbms_monitor和dbms_support也可以实现相同的需求,但没有试过)。
使用oradebug设置10046事件之前需要首先设置待跟踪的会话:
(a) 跟踪本会话,使用:oradebug setmypid即可。
(b) 跟踪非本会话,使用:oradebug setospid SPID(来自v$process)。
查找SPID的方法:
(a) select * from v$session a where audsid = userenv('sessionid');
返回SID值。
(b)
select s.USERNAME, s.OSUSER, s.SID, s.PADDR, s.PROCESS, p.spid
os_process_id, p.pid oracle_process_id from v$session s, v$process p
where s.paddr = p.addr and s.username = upper('待跟踪session用户名') and s.SID
= (a)返回的SID;
例如:

其中:
v$process中的SPID是指操作系统的进程,即操作系统的PID。
v$session中的pid, serial#是oracle分配的PID。
此时如果需要跟踪24061这个session执行的SQL,可以用oradebug setospid 24061,然后oradebug event 10046 trace name context forever, level 12;就打开了10046事件。
接着可以通过oradebug tracefile_name查看trace文件名和路径,例如:

看下petest_ora_22756.trc的内容:
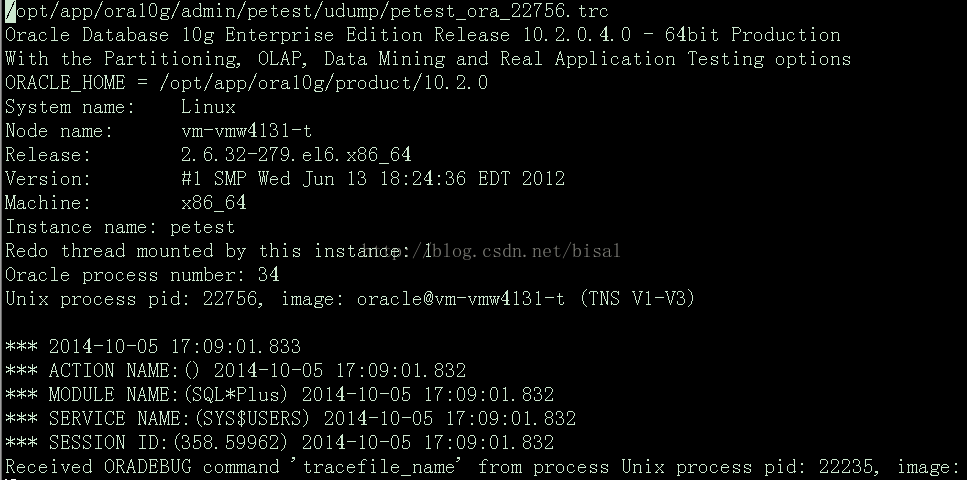
除了机器、实例、进程等基本信息外,真正写入的内容:
Received ORADEBUG command 'tracefile_name' from process Unix process pid: 22235, image:
表示接收到来自Unix的操作系统进程PID是22235的ORADEBUG命令,参数tracefile_name。
显然22235这个进程是sqlplus登陆后执行ORADEBUG的客户端,例如:

(3). 关闭10046的方法:
(a) alter session set events '10046 trace name context off';
(b) oradebug event10046 trace name context off;
分别对应两种打开10046事件的方法。
(4). 再说说oradebug和alter session打开10046事件产生trace文件的区别:
(a) 使用alter session打开10046事件时,如果未执行SQL,则不会产生trace文件。
(b) 使用oradebug event 10046 trace name context forever, level 12;打开10046事件,此时就已经产生trace文件,除基本信息外,主要是一行:
WAIT #0: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1379395297285576
当使用oradebug event 10046 trace name context off;关闭10046事件,会写入一行:
WAIT #0: nam='SQL*Net message from client' ela= 30946429 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1379395328232564
(5). trace跟踪文件:
上面说了打开和关闭10046的两种常用方法,下面简单看看trace文件都包含了什么,为什么说10046这种事件是用于调试的,我现在不能精通所有内容,大概谈谈理解。
首先执行命令打开10046事件、执行SQL、关闭10046事件,例如:
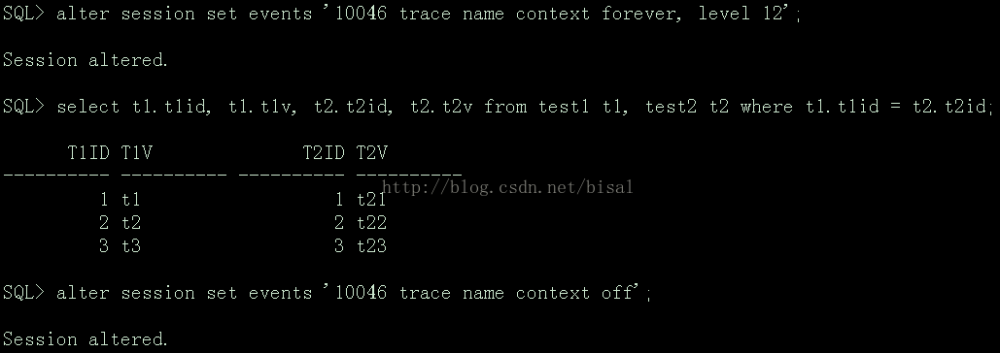
查看产生的trace文件:
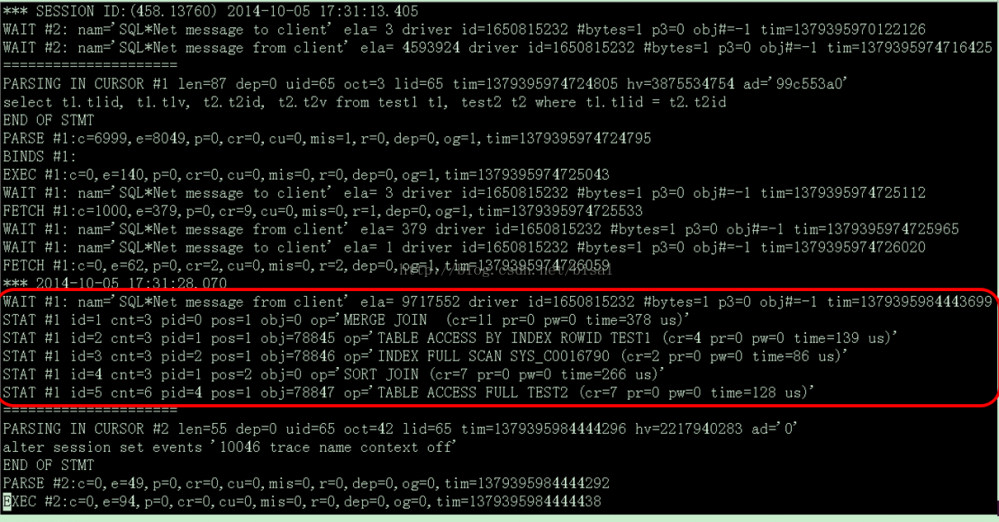
两个"============"之前的内容,是执行SQL产生的信息,之前和之后的内容,应该是打开和关闭10046事件的信息。
红线框内的是这条SQL用的执行计划,从文件中看,一共有5步,括号内的是相关消耗:
执行计划第一步:MERGE JOIN,逻辑读(cr)是11,物理读(pr)是0,时间(time)是378微秒。
执行计划第二步:TABLE ACCESS BY INDEX ROWID TEST1,逻辑读(cr)是4,物理读(pr)是0,时间(time)是139微秒。
执行计划第三步:INDEX FULL SCAN SYS_C0016790,逻辑读(cr)是2,物理读(pr)是0,时间(time)是86微秒。
执行计划第四步:SORT JOIN,逻辑读(cr)是7,物理读(pr)是0,时间(time)是266微秒。
执行计划第五步:TABLE ACCESS FULL TEST2,逻辑读(cr)是7,物理读(pr)是0,时间(time)是128微秒。
这里trc文件是一种裸trace文件,内容可看,但不是那么直观,可以使用tkprof命令翻译trc文件。例如:
查看生成的tkprof文件:
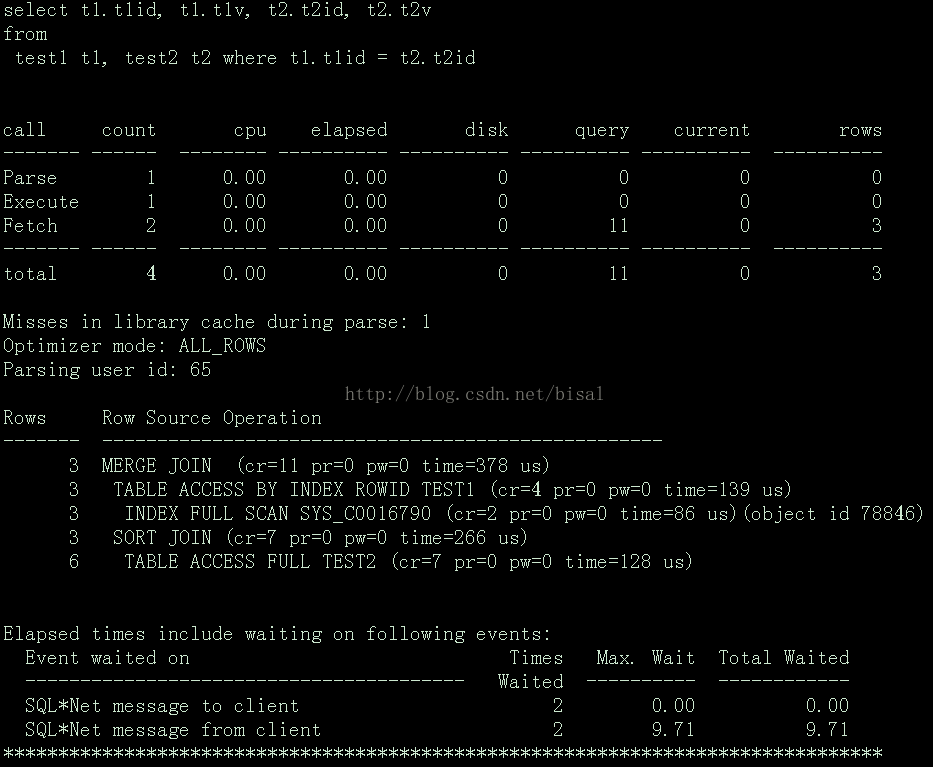
从这里可以更清楚地看到每步执行计划返回的行数,以及顺序关系,按照dbsnake的执行计划读取口诀:“先从最开头一直连续往右看,直到看到最右边的并列的地方;对于不并列的,靠右的先执行;如果见到并列的,就从上往下看,对于并列的部分,靠上的先执行”。简单分析下:
(a) INDEX FULL ...
先使用SYS_C0016790主键索引进行索引全扫描,这里SYS_C0016790是TEST1的主键,即t1id列。
(b) TABLE ACCESS FULL ...
全表扫描TEST2表。(c) TABLE ACCESS BY ...
根据TEST1主键索引返回的ROWID,查询对应数据项。产生结果集1。
(d) SORT JOIN
按照TEST2的t2id列排序。产生结果集2。
(e) MERGE JOIN
遍历结果集1,即取出结果集1的第1条记录,和结果集2中按照t1.t1id=t2.t2id的条件判断是否存在匹配记录,再取出结果集1的第2条记录继续判断,直到遍历完成结果集1。
这里用到的是“排序合并连接”,执行计划中对应的关键字是“MERGE JOIN”和“SORT JOIN”,正常来讲,两个表第二步都应该是SORT JOIN,但这里表TEST1却是TABLE ACCESS BY INDEX ROWID TEST1,我想原因应该是:
(a) 对TEST2表的扫描使用的是INDEX FULL SCAN SYS_C0016790,即使用索引全扫描,扫描t1id的主键索引数据块。
(b) 索引都是有序的,因此INDEX FULL SCAN SYS_C0016790的结果也是相当于排序的。
(c) 既然之前已经是排序的结果,那么按照有序索引对应的ROWID,找到对应的记录也是有序的,TABLE ACCESS BY INDEX ROWID TEST1,所以不用显示SORT JOIN再次排序了。
总结:
查看SQL执行计划,是对SQL进行调优的基础,一方面要能读懂执行计划,理解每一步每一个参数的含义,另一方面要清楚产生执行计划的常用方法,以及各种方法之间的联系和区别,才能在合适的场景选择正确的方法,为下一步调优做好准备工作。正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

