Flink运行时之生产端结果分区
生产者结果分区是生产端任务所产生的结果。以一个简单的MapReduce程序为例,从静态的角度来看,生产端的算子(Map)跟消费端的算子(Reduce),两者之间交换数据通过中间结果集(IntermediateResult)。形如下图:

而IntermediateResult只是在静态表述时的一种概念,在运行时,算子会被分布式部署、执行,我们假设两个算子的并行度都为2,那么对应的运行时模型如下图:
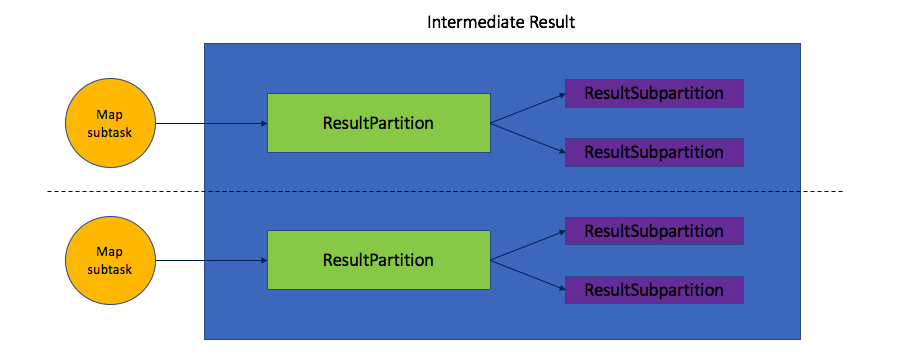
生产端的Map算子会产生两个子任务实例,它们各自都会产生结果分区(ResultPartition)。但ResultPartition并不会直接被处于消费端的Reduce的子任务实例消费,它会再次进行分区从而产生结果子分区(ResultSubpartition),ResultSubpartition是最终保存Buffer的地方。接下来的这一篇,我们就来详细分析生产者分区。
结果分区
在运行时,Flink使用结果分区(ResultPartition)来表示单一任务的子任务实例所生产的数据,这在其作业图中等价于中间结果分区(IntermediateResultPartition)。需要避免对这两个概念产生混淆,IntermediateResultPartition主要用于JobManager组织作业图的一种逻辑数据结构,ResultPartition是运行时的一种逻辑概念,两者处于不同的层面。
每个ResultPartition拥有一个BufferPool并且是被其包含的ResultSubPartition共享的。ResultSubPartition个数主要取决于消费任务的数目以及数据的分发模式(DistributionPattern)。任何想消费ResultPartition的任务,最终都是请求ResultPartition的某个ResultSubPartition。而请求要么是同一TaskManager中的本地请求要么是来自另外一个TaskManager中的消费子任务实例发起的远程请求。
每个ResultPartition的生命周期都有三个阶段:生产、消费和释放。
结果分区类型(ResultPartitionType)是一个枚举类型,指定了ResultPartition的不同属性,这些属性包括是否可被持久化、是否支持管道以及是否会产生反压。ResultPartitionType有三个枚举值:
- BLOCKING:持久化、非管道、无反压;
- PIPELINED:非持久化、支持管道、有反压;
- PIPELINED_PERSISTENT(当前暂不支持)
其中管道属性会对消费端任务的消费行为产生很大的影响。如果是管道型的,那么在结果分区接收到第一个Buffer时,消费者任务就可以进行准备消费(如果还没有部署则会先部署),而如果非管道型,那么消费者任务将等到生产端任务生产完数据之后才会着手进行消费。
结果分区编号(ResultPartitionID)用来标识ResultPartition。ResultPartitionID关联着IntermediateResultPartitionID(也即调度时的分区编号)和ExecutionAttemptID(部署时的生产者子任务实例编号)。在任务失败时,单靠IntermediateResultPartitionID无法鉴别ResultPartition,必须结合ExecutionAttemptID一起鉴别。
一个ResultPartition有多少个ResultSubPartition,是在构建ResultPartition就确定了的。当生产端任务调用记录写入器写入一个记录时,该记录先被序列化器序列化并放入Buffer中,然后通过ResultPartitionWriter加入到ResultPartition,具体被加入哪个子分区中取决于ChannelSelector,该加入方法实现如下:
public void add(Buffer buffer, int subpartitionIndex) throws IOException {
boolean success = false;
try {
//确认生产状态处于未完成状态
checkInProduceState();
//获取指定索引的子分区
final ResultSubpartition subpartition = subpartitions[subpartitionIndex];
synchronized (subpartition) {
//如果Buffer被加入子分区,则success被置为true
success = subpartition.add(buffer);
//更新统计信息
totalNumberOfBuffers++;
totalNumberOfBytes += buffer.getSize();
}
} finally {
//如果Buffer被加入成功,且当前的模式是管道模式,则立即通知消费者任务
if (success) {
notifyPipelinedConsumers();
}
//如果加入失败,则回收Buffer
else {
buffer.recycle();
}
}
}
在notifyPipelinedConsumers方法中,会通过分区可消费通知器(ResultPartitionConsumableNotifier)间接通知消费者任务(经过JobManager转发通知),它会携带两个信息:
- JobID
- ResultPartitionID
ResultPartition有一个标识变量hasNotifiedPipelinedConsumers,用来表示当前是否已通知过消费者,在notifyPipelinedConsumers中,一旦通知过,该标识将会被设置为true,所以该通知只会发生在第一个被成功加入的Buffer之后,后续便不再通知。
ResultPartitionConsumableNotifier当前只有一个实现JobManagerResultPartitionConsumableNotifier(位于NetworkEnvironment中的一个静态内部类),它会通过Actor网关向JobManager发送一条请求消息(ask模式,需要应答)。
这是针对管道模式的ResultPartition而言的,而针对阻塞模式的ResultPartition的通知时机却需要等到数据生产完成之后(ResultPartition的finish方法被调用),任务会向JobManager报告其状态变更为FINISHED。JobGraph根据执行图(ExecutionGraph)找到完成任务对应的IntermediateResultPartition的消费者任务并调度它们进行消费:
for (IntermediateResultPartition finishedPartition : getVertex().finishAllBlockingPartitions()) {
IntermediateResultPartition[] allPartitions = finishedPartition
.getIntermediateResult().getPartitions();
for (IntermediateResultPartition partition : allPartitions) {
scheduleOrUpdateConsumers(partition.getConsumers());
}
}
当每个子分区中的缓冲区数据被消费完后,它们会通知ResultPartition。因为一个ResultPartition包含若干个ResultSubPartition,那么ResultPartition如何判断所有的ResultSubPartition都被消费完了呢?它基于原子计数器(AtomicInteger),每个ResultSubPartition被消费完成之后都会回调ResultPartition的实例方法onConsumedSubpartition:
voidonConsumedSubpartition(intsubpartitionIndex){
//已被释放,则直接返回
if (isReleased.get()) {
return;
}
//计数器减一后获得未完成的子分区计数
int refCnt = pendingReferences.decrementAndGet();
//如果全部都已完成,则通知ResultPartitionManager,它会将ResultPartition直接释放
if (refCnt == 0) {
partitionManager.onConsumedPartition(this);
}
//异常
elseif(refCnt <0){
throw new IllegalStateException("All references released.");
}
LOG.debug("{}: Received release notification for subpartition {} (reference count now at: {}).",
this, subpartitionIndex, pendingReferences);
}
我们在add方法中看到,ResultPartition其实不保存Buffer,它只是起到一个分配或者转发的作用,Buffer真正会被保存到ResultSubPartition中。
ResultPartition会被消费端任务消费,但对消费者而言,其跟待消费的ResultPartition之间不同的位置消费方式却不一样。ResultPartitionLocation对不同的位置进行了定义和封装。目前支持三种位置类型:
- LOCAL:表示消费者任务被部署在跟生产该ResultPartition的生产者任务相同的实例上;
- REMOTE:表示消费者任务被部署在跟生产该ResultPartition的生产者任务不同的实例上;
- UNKNOWN:表示ResultPartition未被注册到生产者任务,当部署消费者任务时,其实例可能是确定的也可能是不确定的。
对ResultPartition进行管理的部件是结果分区管理器(ResultPartitionManager)。一个NetworkEnvironment对应一个ResultPartitionManager。
ResultPartitionManager会对某个TaskManager中已生产和已被消费的ResultPartition进行跟踪。具体而言,它采用Guava库里的Table这一集合类型来维护其所管理的ResultPartition。
Table是Guava集合库提供的一个多级映射容器类型。效仿了关系型数据库中的数据表结构,支持”row”、“column”、“value”。其结构等价于Map<R, Map<C,V>>且提供了针对多个Map的实现。
该数据结构的完整定义如下:
public final Table<ExecutionAttemptID, IntermediateResultPartitionID, ResultPartition>
registeredPartitions = HashBasedTable.create();
在NetworkEnvironment中注册Task时,会获取该Task所生产的ResultPartition数组。然后用ResultPartitionManager的registerResultPartition方法进行注册。同样,在对Task解除注册时,会调用ResultPartitionManager的releasePartitionsProducedBy方法,将相应的ExecutionAttemptID对应的信息从registeredPartitions表中移除。在releasePartitionsProducedBy方法中,所有的ResultPartition都会调用其release以释放各自占用的资源。
结果子分区
ResultPartition可以看作结果子分区(ResultSubpartition)的容器,而ResultSubpartition是真正存储供消费者消费Buffer的地方。ResultSubPartition是一个抽象类,针对不同类型的ResultPartition提供了两个实现:
- PipelinedSubpartition:基于内存的管道模式的结果子分区;
- SpillableSubpartition:基础模式下是基于内存的阻塞式的结果子分区,但数据量过大时可以将数据溢出到磁盘;
在ResultPartition的构造器中,会根据ResultPartitionType来实例化特定的结果子分区:
switch (partitionType) {
case BLOCKING:
for (int i = 0; i < subpartitions.length; i++) {
subpartitions[i] = new SpillableSubpartition(i, this, ioManager, defaultIoMode);
}
break;
case PIPELINED:
for (int i = 0; i < subpartitions.length; i++) {
subpartitions[i] = new PipelinedSubpartition(i, this);
}
break;
default:
throw new IllegalArgumentException("Unsupported result partition type.");
}
PipelinedSubpartition会将数据保存在双端队列中(ArrayDeque),在ResultPartition完成数据生产时,其finish方法会得到调用,该方法会依次触发它所包含的所有的ResultSubpartition的finish方法,作为结束的标记,一个EndOfPartitionEvent事件会作为一个特殊的Buffer加入到双端队列中去。
SpillableSubpartition结合了内存缓存和磁盘持久化的能力。最初,Buffer被加入进来时是以一个ArrayList来缓存,当BufferPoolOwner也就是SpillableSubpartition的父容器ResultPartition因为Buffer资源紧张决定释放一定数量的Buffer时,其releaseMemory方法会间接被触发(这对于SpillableSubpartition来说意味着将没有足够的内存资源来容纳生产者的数据了)。这时,它会通过IOManager的createBufferFileWriter方法来创建一个BufferFileWriter(通过该写入器可以以阻塞的模式将Buffer写到磁盘上),这时所有ArrayList内的Buffer都将被写入磁盘。注意,BufferFileWriter的实例一旦被创建之后,所有再加入进来的Buffer都将被直接写入磁盘,而不再加入到ArrayList。维护两个“Buffer源”并不是一个明智的选择,并且当BufferFileWriter被创建,也意味着内存不再宽裕。同样,其finish方法也会加入一个EndOfPartitionEvent来标记结束。
结果子分区视图
ResultSubpartition负责容纳Buffer,但考虑到它对Buffer提供了不同的存储实现,所以又提供了结果子分区视图(ResultSubpartitionView)抽象出从不同的存储机制中读取Buffer的方式。因此,ResultSubpartitionView才是对接数据消费端的对象。当前的ResultSubpartitionView的实现有:

其中跟SpillableSubpartition相关的就有三个,它们的差异如下:
- SpillableSubpartitionView:通用的基于内存、磁盘的读取视图,如果数据溢出到磁盘,则借助于另外两个基于磁盘的读取视图;
- SpilledSubpartitionViewSyncIO:溢出到磁盘以同步模式读取的视图;
- SpilledSubpartitionViewAsyncIO:溢出到磁盘以异步模式读取的视图;
这些视图的选择逻辑封装在SpillableSubpartition的createReadView方法中。而对于PipelinedSubpartitionView,很显然它是关联着PipelinedSubpartition的。
ResultSubpartitionView提供了获取Buffer的接口方法getNextBuffer。因为每个ResultSubpartition存储这些Buffer的机制不一,这才是为什么需要ResultSubpartitionView的原因。
其实,ResultSubpartitionView并不是针对PipelinedSubpartition而构建的,更主要的是针对SpillableSubpartition。
PipelinedSubpartitionView的实现我们就不多说了,它就是从PipelinedSubpartition存储Buffer的队列出队一条记录。
我们的重点将会放在由SpillableSubpartition所衍生出的三个视图对象上。
对于SpilledSubpartitionViewSyncIO,其以同步的形式(SynchronousBufferFileReader)从磁盘读取,读取器读取的单位就是Buffer。SpilledSubpartitionViewSyncIO自己在内部实现了一个缓冲池SpillReadBufferPool,其缓冲池里的内存段并非池化的,而是直接申请,缓冲池被销毁时所有的内存段随即被释放。
SpilledSubpartitionViewAsyncIO采用的是AsynchronousBufferFileReader这一异步Buffer读取器,该读取器采用的是批量读取的模式从磁盘读取,默认单批次读取数量为2。该读取器会启动一个独立的I/O线程来读取,读取完成之后会触发一个RequestDoneCallback类型的异步回调,SpilledSubpartitionViewAsyncIO内部实现了这一接口,在读取完成之后会触发returnBufferFromIOThread方法,它会把读取到的Buffer加入到ConcurrentLinkedQueue<Buffer>类型的队列中去。SpilledSubpartitionViewAsyncIO中用于填充从文件读取到数据的Buffer是从ResultPartition的BufferPool中获取到的。既然是从池中获取Buffer,那么就会存在没有Buffer可用的情况,这里还是通过事件回调的机制在有可用Buffer时触发处理逻辑。
最后再讲一下SpillableSubpartitionView,它依赖于上面两个基于文件读取的视图。具体而言,跟SpillableSubpartition类似,它会判断其对应的SpillableSubpartition实例的spillWriter变量以及用于支持基于文件读取的视图对象spilledView是否为空,以将读取的场景划分为三种:在内存中、已溢出到磁盘、正在溢出到磁盘。在内存中,直接从集合中返回;已溢出到磁盘,则直接调用基于文件的读取视图返回;正在溢出则返回null,因为在写磁盘没有完全结束时,不会进行消费。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

