密歇根州立大学教授刘小明讲解:人脸识别的新技术 | 大牛讲堂
雷锋网 (公众号:雷锋网) 按:本文作者刘小明,密歇根州立大学计算机科学与工程系助理教授,计算机视觉、模式识别、生物识别和机器学习领域专家。曾任ICPR,WACV和CVPR等多个计算机视觉及图像处理国际顶尖会议主席,获得多项国际学术大奖。共发表或出版100余本学术文章,持有22项美国专利。
在计算机视觉领域,人脸识别一直以来都是学术界和工业界的双重宠儿。学术上的热门和工业市场的迫切需求,使得围绕该方向的核心技术自深度学习爆发以来,得到了更为迅猛的发展。
得益于深度学习,当前计算机对人脸属性的分析判断在某些(姿态、光照)限制条件下已经媲美甚至超越人类,但是如何在非限制条件下,使计算机获取和人类一样,从姿态万千的人脸图像中依然能够进行识别的能力,是一项非常具有挑战性的工作。
地平线《大牛讲堂》邀请到美国密歇根州立大学刘小明教授,他将结合自己近年来有关人脸识别的研究成果和发表在多篇世界顶级期刊(CVPR,TPAMI等)的论文,为大家带来分享——2D/3D shape estimation and recognition for large-pose faces。
| 神奇idea:大姿态下人脸图像矫正算法
人脸矫正是人脸属性分析中至关重要的一步,能够直接影响整体性能的好坏。在深度学习之前就有许多优秀的方法被提出,例如知名度较高的ASM和AAM,这些方法能够在人脸变化不大的条件下取得比较好的效果,但是对于一些发生遮挡或者姿态角度偏大的情况就差强人意了;在深度学习出来之后,一些基于深度学习的方法虽然能够解决上述部分问题,但是对姿态角度偏大的情况仍然无能为力。
针对上述问题,刘小明教授在2016年CVPR的一篇论文中有提出一个神奇的idea,利用3D人脸可变模型来解决2D图像中姿态角度偏大问题,该方法神奇之处在于 能够 使3D人脸模型“学习”2D图像中人脸在拍照时候的姿势状态 。如下图左边的第一步,给神经网络输入通用正面人脸模板模型和2D图像,神经网络识别获取图像中人脸的姿态角度参数矩阵,利用这些参数就可以使模型“做出”和图像中人脸同样的脸部朝向。
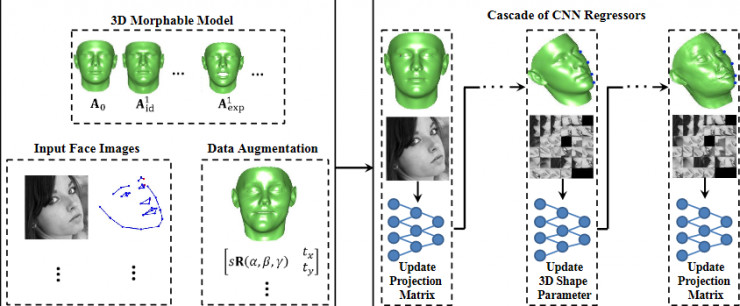
反过来,对改变姿态之后的3D模型,我们给它“拍个照”,变成2D图像,那么3D模型上的关键点通过“拍照”,就映射到2D图像上来了,得到一个初步的粗定位;此时,再根据关键点坐标,把原始图像切片,输入到另外的网络来调整3D模型的形状参数,使得模型更加精确的拟合2D图像,这样多次迭代之后,关键点便被精确定位出来。该方法开创性地利用3D人脸可变模型来学习2D图像,并且通过级联CNN神经网络回归来提高精确度,使得即使大姿态下,被遮挡的关键点也能被很好的定位出来。
 (论文参考:Large-pose FaceAlignment via CNN-based Dense 3D Model Fitting)
(论文参考:Large-pose FaceAlignment via CNN-based Dense 3D Model Fitting)
| 一个经典的问题:三维人脸重构
三维人脸重构在3D动画、犯罪侦查以及身份识别等领域有着广阔的应用前景,当使用在不固定场景下获取的人脸图像来重构人脸时,由于光照表情的变化,使得任务变的非常困难,刘小明教授结合近几年的研究提出了基于关键点和光照变换的人脸三维重构技术。
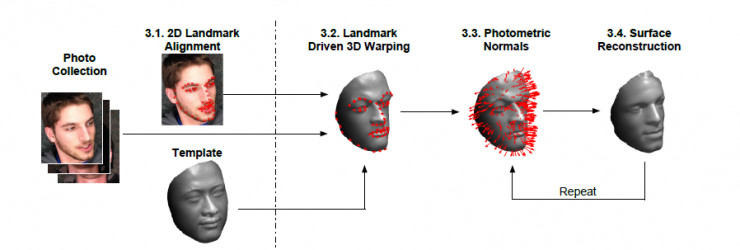
该方法首先通过人脸关键点检测技术,将2D图像中人脸经神经网络映射,使通用人面模型拟合2D图像,然后利用Lambertian反射模型统一光照,最后通过3D模型的法向量反复迭代来重构模型表面。
| 更接近真实场景: 多角度人脸识别技术
随着深度学习的发展,很多深度学习算法在正面脸情况下,对人脸识别的能力已经超越了人类,但是实际场景中,很多时候都是非正面的;基于此,刘小明教授给我们分享了他在人脸识别方面的最新成果—— 多角度人脸识别技术。
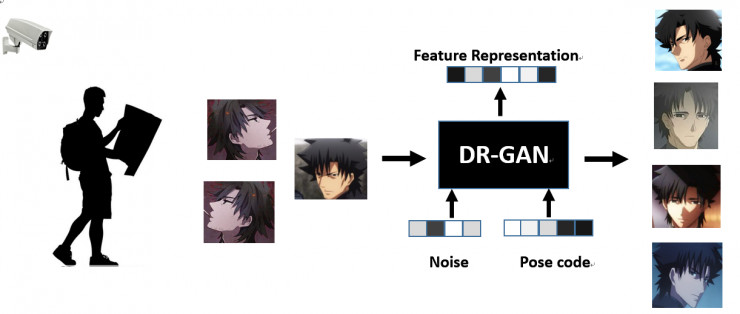
(卡通图像非实际效果,仅供参考示意)
该技术包含两个核心部分, 表示学习和图像生成 。表示学习是指在某一个场景下获取的多张不同姿态的图像,将这些图像作为输入,通过提出的DR-GAN网络模型,产生一个固定长度的特征向量,该向量表示的是这个人的特征,与姿态光照无关,同时该网络还可以根据输入的Noise/Pose编码,生成不同姿态的人脸。
以上即为刘小明教授的分享摘要,感谢地平线员工梁柱锦、李奇协助整理。未来,地平线还将继续推出系列大牛分享,为大家带来更多的技术干货,请多多关注地平线《大牛讲堂》。
雷锋网注:本文由大牛讲堂授权发布雷锋网,如需转载请联系原作者,并注明作者和出处,不得删减内容。有兴趣可以关注公号【地平线机器人技术】,了解最新消息。
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

