谷歌、微软、OpenAI 等巨头的七大机器学习开源项目 看这篇就够了
在人工智能行业,2015-2016 出现了一个不同寻常的趋势:许多重量级机器学习项目纷纷走向开源,与全世界的开发者共享。 加入这开源大潮的,不仅有学界师生,更有国内外的互联网巨头们:国内有百度和腾讯,国外的有谷歌、微软、IBM、Facebook、OpenAI 等等。本文总结了国外各家互联网巨头的七大开源机器学习项目:
Google:TensorFlow

TensorFlow 发布于 2015 年 11 月,是谷歌基于 DistBelief 研发的第二代机器学习系统。它是一个能处理多种语言理解和认知任务的开源软件库。它最初由谷歌大脑(Google Brain)的研究人员开发出来,用于机器学习和深度神经网络方面的研究。但它的通用性使其也可广泛用于其他计算领域。在谷歌,TensorFlow 已用来支持Gmail、谷歌相册、语音识别、搜索等旗下多款商业化应用。许多开发者把它看作是 Theano 的替代品:这两者都采用了计算图( computational graph)。
现在, TensorFlow 发布已超过一周年, 它已成为 GitHub 上最受欢迎的机器学习开源项目 。并且,谷歌已为它加入了官方 Windows 支持。
优点:
-
谷歌表示,TensorFlow 的优点在于:通用,灵活,可移动,容易上手并且完全开源。对于部分任务,它的运行速度能达到上代 DistBelief 的两倍。
-
TensorFlow 不仅仅是深度学习工具,它还支持强化学习以及其他算法。
-
它既可用来做研究,又适用于产品开发。
-
但 TensorFlow 最大的优点,应该是 用的人多 ——它是 AI 开发者社区参与度和普及程度最高的开源项目之一。Cambrio 的 CEO Daniel Kuster 表示:“写出能让机器编译、执行的代码或许不难,但让同行们接受就十分不容易了。越多人用,越多的人分担(难题)。”
缺点:
计算资源分配机制使系统更复杂:为使用户精确控制 GPU 节点的使用情况,TensorFlow 牺牲了简洁。另外,启动时它会试图占用全部的可用显存。
评价:
微软机器学习研究员彭河森表示, TensorFlow 是非常优秀的 跨界 平台:它吸取了已有平台的长处,既能让用户触碰底层数据,又具有现成的神经网络模块,可以让用户非常快速的实现建模。
更多请参考,雷锋网整理的 真正从零开始,TensorFlow详细安装入门图文教程! 以及 谷歌 TensorFlow 一岁啦,它是最受欢迎的机器学习开源项目 。
Google:DeepMind Lab

这家精通 AI 训练的公司,以在围棋上五局四胜击败李世石的 ALphaGo 扬名于世。这成为 2016 年的 AI 里程碑事件。被谷歌收购后,更使后者的江湖地位得到巩固。
本月初,DeepMind 宣布把 AI 训练平台 Labyrinth 开源,并改名为 DeepMind Lab。
没错,这就是之前的那个“迷宫游戏”:
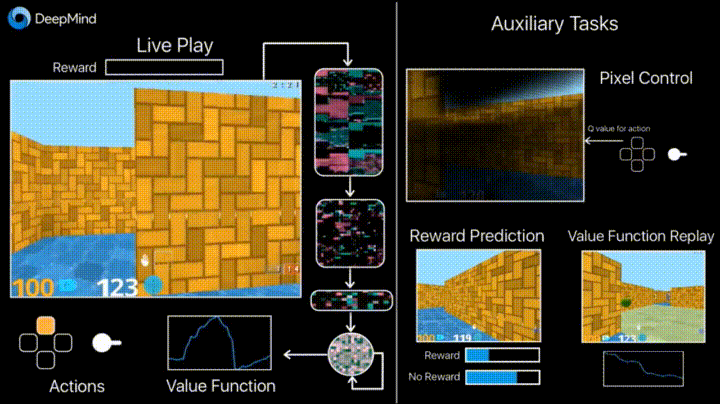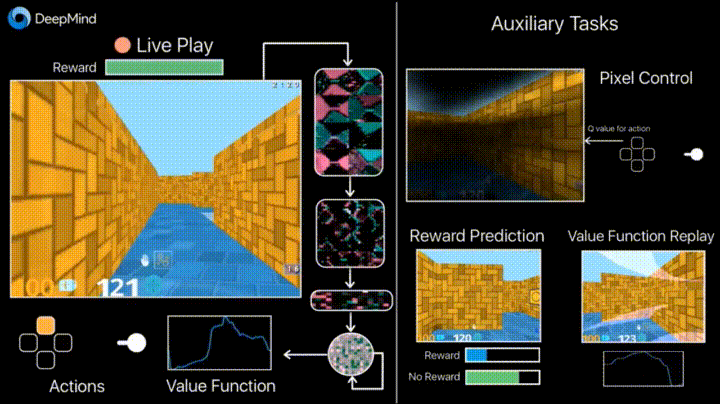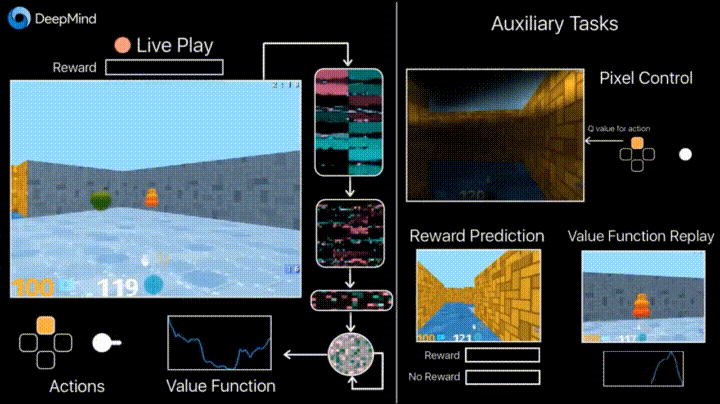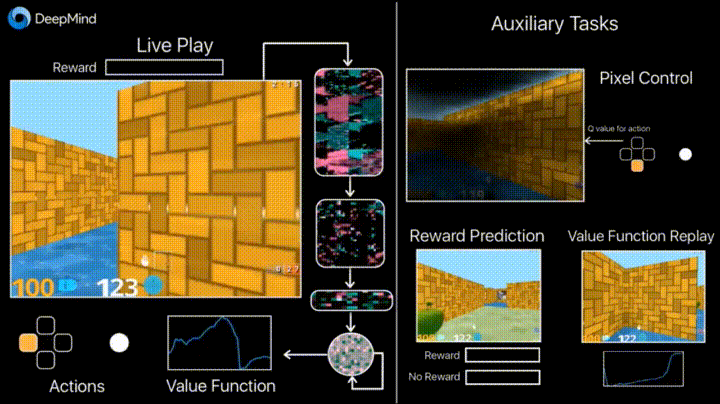
它是针对基于代理的 AI 研究而开发的 3D 训练平台。DeepMind 表示, 它为学习代理提供了一系列颇具挑战的三维探索和解谜任务。该项目旨在为 AI 研究、尤其是深度强化学习提供试验田。
所有场景使用科幻剧风格进行渲染。它采用了第一人称视察方式:通过代理的视角。代理的躯体是一个漂浮的圆球,通过启动背后的推进器前进。“游戏”中,代理可以在 3D 空间中移动,转动“头部”观察周围环境。
DeepMind Lab 具有高度可定制、可扩展性。新的等级可以通过现成的编辑工具制作。另外,DeepMind Lab 包括了纲领性等级创建的交互界面。不同等级可以从多方面来定制:游戏逻辑、捡落物品、旁观、等级重启,奖励机制,游戏内信息等等。
DeepMind 联合创始人 Shane Legg 表示, DeepMind Lab 比其他的 AI 训练环境要出色,因为其游戏环境非常复杂。 此前,通过改良传统深度增强学习方法,Deepmind 使代理以高于 A3C(DeepMind 另一个现役代理) 十倍的速度学习,并平均在每个迷宫层达到人类专家水平的 87% 。
DeepMind Lab 的源代码公布于 GitHub,它目前需要依赖于外部软件库。由于发布时间尚短,开发者社区对于 DeepMind Lab 的反馈很少。
关于 DeepMind Lab 的详细信息,请参考 继 OpenAI 之后,DeepMind 开源深度学习训练平台 DeepMind Lab 和 DeepMind 黑科技!颠覆传统强化学习方法,代理学习速度提高十倍(附视频) 。
OpenAI:Universe
本月,正是这家马斯克投资的初创公司一周岁生日。在月初的 NIPS 大会上,它宣布对旗下 AI 训练平台 “Universe”(宇宙)开源。这是一个与 DeepMind Lab 十分类似的平台,两者宣布开源的时间点也十分接近,这引发了公众对两者间竞争关系的猜想。
与 DeepMind Lab 相似,Universe 的目标也是给开发者们训练、测试 AI 代理提供平台。但对于它们之间的不同点,官方给出了解释:
-
Universe 是一个在全世界的游戏、网页和其他应用中,评估、训练智能代理的软件平台。
-
代理使用了和人类一样地感官输入和控制方式:看到的是像素,控制的是鼠标键盘。这使得任何需要电脑来完成的任务,都可以训练 AI 去做,并且与人类玩家较量。
这十分有野心。对于第一点,OpenAI 给出了进一步说明:Universe 包含上千种不同训练环境,包括 Flash 游戏,网页任务,蛇蛇大作战和侠盗猎车手5 这样的游戏。开发团队在博客中说:“我们的目标是开发出一个单个 AI 代理,能灵活地把它过去的经验应用于 Universe 场景中,来迅速掌握陌生、困难的环境。 这会是走向通用智能的关键一步。 ”
OpenAI 认为深度学习系统过于专业化:“AlphaGo 能在围棋上轻松赢你,但是你无法教会它其他棋牌游戏,然后让它跟你玩。”于是,Universe 使得 AI 能够处理多种类型的任务,让它发展出“关于世界的知识和解决问题的战术,并能有效应用于新任务。”
雷锋网消息,OpenAI 已经拿到了 EA,微软工作室,Valve 和其他公司的许可,以使用银河飞将3,传送门和环世界 (Rimworld) 等游戏。OpenAI 还在积极联系其他公司、开发者和用户,寻找更多游戏的许可,用不同 Universe 任务训练代理,并把新游戏整合入系统。
对于为什么 OpenAI 和 DeepMind 会一前一后选择开源,外媒 Engadget 认为,目前 AI 已经发展到新阶段——需要更多的学习数据,所以通常情况下“较封闭”的科技公司会选择对外合作。当然,2015-2016 的这波开源大潮中,AI 行业各成员展示出的与公众分享研究成果的精神,也值得肯定。
Facebook:FastText

与上面两者不同,今年八月 Facebook 推出的 FastText 是一个文本分析工具,旨在为“文本表示和分类”创建可扩展的解决方案。 它专为超大型数据库的文本处理而设计,而该领域的另一个主要解决方案——深度神经网络,处理海量数据时容易出现许多问题。 Facebook AI 研究部门 “FAIR” 指出,深度神经网络通常训练、测试起来速度很慢。
FastText 能够在几秒钟、或是几分钟之内完成大型数据库的训练。而基于深度学习的方法可能会花费几小时甚至几天。 FastText 已经能够用于垃圾邮件过滤器等重要应用,但是,在将来它还可能为 Siri 和 Google Now 这样的 AI 提供帮助,使它们更快地处理自然语言。
Facebook 宣称,这项新技术“对于超过 10 亿个词汇的训练不超过十分钟”,而这只需要“普通”的多核 CPU。另外,它还能在五分钟内对 30 万个目录下的 50 万个句子进行分类。
详情请参考 比深度学习快几个数量级,详解Facebook最新开源工具——fastText 。
Microsoft:CNTK

CNTK 的全称是 Computational Network Toolkit,意为“计算网络工具箱”,它是一个让开发者们把分布式深度学习应用于他们各自项目的工具。微软在今年一月将它对外发布,在十月份又进行了重大升级,使其有更快的速度和更好的扩展性。
微软表示, CNTK 是一个“统一的深度学习工具箱,它把神经网络描述为通过有向图进行的(directed graph)一系列计算步骤”。 对于部分业内人士,它是其他深度学习框架、资料库和工具箱(例如TensorFlow, Theano 和 Torch)的替代物。但其实, CNTK 最开始的用途是语音识别 。虽然现在它已成为通用的、独立于平台的深度学习系统,但相比通用深度学习社区,它在语音识别社区的知名度更高。
CNTK 支持对常用深度神经网络架构的结构性执行,比如卷积神经网络 (CNNs),循环神经网络 (RNNs )和长短期记忆网络 (LSTMs)。因此,它应用了随机梯度下降 (SGD) 、反向传播(SGD)和自动区分(auto differentiation)。 CNTK 的一大优点是:它支持多个计算设备以及多个 GPU 的计算。 相比之下, TensorFlow 最近才开始加入对横跨不同计算设备的运算支持。
在内部测试中微软首席语音科学家黄学东表示,在开发者们为语音、图像识别任务创建深度学习模型方面, CNTK 被证明比其他四种主流工具箱都要快。他说:
“与任何已知的方法相比,CNTK 难以置信得快。”
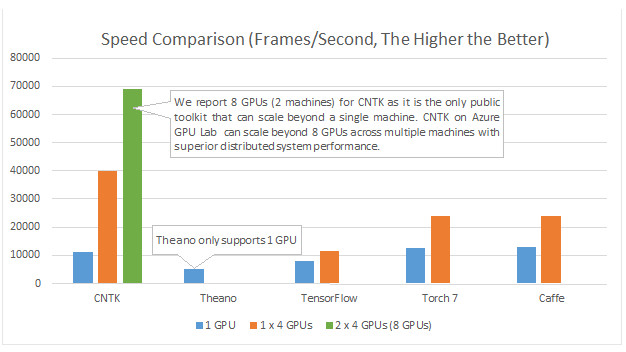
CNTK、Theano、TensorFlow、Torch 7、Caffe 之间的 GPU 运算速度对比。竖轴是帧/每秒,蓝色柱代表单个 GPU,橙柱代表一组四个 GPU,绿柱代表两组四个 GPU。测试时,其他工具箱尚不支持多计算设备,Theano 不支持多 GPU。
以下是微软官方宣传中 CNTK 的三大优点:
-
速度和扩展性
CNTK 训练和评估深度学习算法比其他工具箱都要快, 在一系列情况下的可扩展性都非常好——不管是一个 CPU、多个 GPU、还是多个计算机,与此同时保持效率 。
-
商用级别的质量
CNTK 的复杂算法使它能在海量数据库中稳定运行。Skype、微软小冰、必应搜索、Xbox 和业内顶级的数据科学家已经在使用 CNTK 来开发商用 AI。
-
兼容性
CNTK 提供了最有表达力、最容易使用的架构。它允许你使用所有内置训练算法,或者使用你自己的。
关于 CNTK 的技术细节,请参考雷锋网此前的深度分析: 微软为什么要用英伟达的GPU来支持CNTK? | GTC China 2016 。
Amazon:MXNet

MXNet 诞生于学界,并不是亚马逊开发的开源平台,但已成为它的御用系统。
它是一个多语言的机器学习资料库,旨在降低开发机器学习算法的门槛,尤其是对于深度神经网络而言。它支持卷积神经网络(CNN)以及 LSTMs( long short-term memory networks)。它通过把符号式编程(symbolic programming)和命令式编程(imperative programming)组合起来,以最大化效率和生产力。它的核心是一个 dependency scheduler,能同时进行符号式和命令式任务。这之上的图优化层(graph optimization layer)使得符号式程序执行快速、高效。MXNet 具有轻便和可移动的特点,在设计之初就考虑到了对多 GPU 、多个计算机以及不同计算平台的支持。从移动设备到分布式 GPU 集群,都可用于 MXNet。
国内的图森互联和地平台机器人是 MXNet 的使用者之一。 但真正使它声名大噪的,是 11 月亚马逊宣布把 MXNet 选其为官方深度学习平台,用于亚马逊网路服务系统 AWS,并将在未来成为 MXNet 的主要贡献者。 亚马逊表示,选择 MXNet 有以下三点原因:
-
扩展到多 GPU 系统的潜力。这使得亚马逊能充分利用计算性能。
-
开发速度和可编程性。亚马逊希望选择一个开发者能快速上手的平台。
-
移动能力。限制在大型服务器运行的机器学习应用,价值有限。亚马逊希望能在多种计算设备运行机器学习工具。
MXNet 创始者之一的解浚源表示:“MXNet的速度,节省内存,接口灵活性,和分布式效率都是可圈可点。”
更多请见 预告:MXNet火了,AI从业者该如何选择深度学习开源框架丨硬创公开课 ,以及 如何评价 MXNet 被亚马逊AWS 选为官方深度学习平台 。
IBM:SystemML

SystemML 始于 2010 年, 它的技术来自于 IBM 开发 Watson 的过程,最初是 IBM 为 BigInsights 数据分析平台而开发。 2015 年,IBM 把它捐赠给 Apache Spark 开源社区,从此 SystemML 又被称为 Apache SystemML。 它与 Apache 的另一个项目“Spark” 有着高度的整合 。
SystemML 为使用大数据的机器学习提供了一个理想的环境。它可运行于 Apache Spark 之上,自动给一行行的数据标量(scale data),来决定你的代码是否运行在驱动或是 Apache Spark 集群之上。
SystemML 是一个机器学习算法的解码器,帮助开发者创建用于不同工业领域预测分析的机器学习模型。开源版本的 SystemML,即 Apache SystemML,旨在帮助数据科学家把算法转化到生产环境,而不需要重新编写底层代码。因次,IBM 号称能把数据分析从笔记本电脑扩展到大数据中心。
IBM Analytics 副主席 Rob Thomas 表示:“这使专业领域或专门行业的机器学习成为可能,给开发者带来一系列的帮助,从底层代码到定制应用。”
它有两个优点:
-
表达定制逻辑分析有完全的灵活性。
-
数据独立于输入格式和物理数据表达。
更多请见雷锋网此前报道: 这下齐了,IBM也要开源机器学习平台了 。
【兼职召集令!】
如果你对未来充满憧憬,喜欢探索改变世界的科技进展,look no further!
我们需要这样的你:
精通英语,对技术与产品感兴趣,关注人工智能学术动态的萝莉&萌妹子&技术宅;
文字不求妙笔生花,但希望通俗易懂;
在这里,你会收获:
一群来自天南地北、志同道合的小伙伴;
前沿学术科技动态,每天为自己充充电;
更高的生活品质,翻翻文章就能挣到零花钱;
有意向的小伙伴们把个人介绍/简历发至 guoyixin@leiphone.com,如有作品,欢迎一并附上。
相关文章:
AI 从业者该如何选择深度学习开源框架丨硬创公开课
机器学习年度 20 大开源项目花落谁家?(Python 版)
Comma.ai 开源惹烦恼,代码开发者该为自动驾驶事故负责吗?
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
- 本文标签: 开发 src 2015 编译 git 安装 大数据 创始人 快的 dist 文章 分布式 服务器 ip 集群 Facebook 时间 软件 投资 笔记本电脑 希望 apache mail 产品 开源项目 代码 谷歌 Amazon python IO 目录 质量 互联网 微软 GitHub HTML 开源 ACE 野心 windows 数据库 数据 Google Now 智能 语音识别 博客 深度学习 IBM 事故 开源软件 亚马逊 CEO 百度 http 数据科学 测试 科技 开发者 Google 总结 颠覆 神经网络 定制 UI 移动设备 空间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

