2016CCF大数据与计算智能大赛总结
情感分析是网络舆情分析中必不可少的技术,基于视角的领域情感分析更是情感分析应用于特定领域的关键技术。在对句子进行情感分析时,站在不同的视角,同一个句子的情感倾向判断结果将有所差别。本赛题意在情感分析任务中,站在数据使用者的角度进行特定的情感分析,使数据分析的结果更具可用性。本赛题可以细分为“视角抽取”与“基于视角的情感分析”两部分。下文首先介绍“视角”的定义,而后对“视角抽取”与“基于视角的情感分析”任务进行详细介绍:
视角定义:在情感分析这一任务中,对于同一个文档或句子,不同的数据使用者去分析,将会有不同的情感倾向。同时,从文中不同内容去分析,也有可能会得到不一样的情感。
例如:
在“A车在第三季度一举超过B车成为销量冠军”这样一句话中,如果分析者站在A车的角度去考虑,这句话就是正面的,但是如果分析者在B车的角度,则丢失了销量冠军这样一则消息是负面的。而在本句话中,“A车”和“B车”则是两个不同的情感视角。
视角泛指某一类的思考角度,可以理解为数据使用者角度,亦可以理解为文本中某些方面,在本赛题中,为了简化《基于视角的领域情感分析》这一任务,我们将视角进行具体化——特指文本中出现的汽车品牌词语(如:“上汽大众”、“美国通用”、“速派”、“POLO”等)。
视角抽取:又称为“视角识别”。顾名思义,这一任务意在从文本中抽取(识别)出可以描述视角的词语。由于在本次任务中,视角特指汽车品牌词,故这一步的任务需要参赛队伍抽取(识别)出文本中的汽车品牌词(或别名)。
例如:
-
“考虑到终端市场的情况,我们本次选取了全新迈腾全系的次顶配车型和帕萨特2.0T排量的顶配车型来进行对比”一句话中,参赛队伍应抽取出“迈腾”和“帕萨特”两个视角。
-
“最终我们放弃了迈腾,把小帕开回了家!”一句中,参赛队伍应抽取出“迈腾”和“小帕”两个视角。在这里“小帕”是“帕萨特”的别名。
在本次评测中,我们将给出一个汽车品牌词语集合来供参赛队伍参考。这个品牌词集合包含了测试语料中出现的大部分汽车品牌词及少部分未出现的汽车品牌词。为了验证参赛队伍“视角抽取”方法的鲁棒性,会有评测语料中的部分汽车品牌词并未出现在这一集合中的现象。
基于视角的情感分析:给定一个句子,如果该句子中包含“视角”词语,则应针对这一视角进行情感分析;如果句子中包含多个“视角”词语,则应对不同的视角进行单独的情感分析;如果句子中不包含视角,则不做情感判别处理。
摘要
从开始选题,到10月10号我们的第一次提交,再到12月25号决赛收官,将近90天的努力,换来了许许多多的收获,收获了一座优秀奖奖杯,收获了知识和技能的增长,更收获了对这种数据与智能的大赛的一个全新认知,最后,也收获了许多真挚的友谊。通过不断地摸索,在视角识别中,我们尝试了命名实体识别,CRF,精确匹配等诸多方法,最终采用了基于AC自动机的多模匹配方法,做到快速而精确的匹配,在情感分类中,我们尝试过各种传统机器学习方法,做过许多特征工程,也尝试过深度学习中的卷积神经网络(CNN),最终选择了循环神经网络(RNN)中的GRU(Gated Recurrent Unit)来做表示学习和情感分类,取得了良好的效果。
团队
我们队的队名是Archers,“弓箭手”的意思,下面是我们队的队徽,我们团队由4名成员组成,都来自南京大学计算机系PASA大数据实验室,队长为研三学姐ArcherW,其他三名队员都是研一的小伙伴,chenminzoe,shizihao123,和笔者。

算法模型
本部分介绍一下我们最终模型的演变产生过程,以及我们所做的一些探索及效果。
10月10号,我们撸了一个简单的基于规则的情感分析算法,想探一下究竟,视角没有进行细致的抽取,只是利用给的View中的视角,采用简单的字符串匹配来进行简单提取,这一交,在初赛A榜中,只拿到了0.35768的分数,虽然没用,但是我们得到了一个可以用来比较的baseline,接下来就是不断探索,尝试其他的方法了。
此后,我们4人通过定期的讨论,每个人都对一部分进行深入研究,然后定期地交流,进行思维的碰撞,以期抛弃一些错误的想法,确定正确的想法,探讨当前阶段的优势与不足,确定下一个着力点等等,ArcherW的主要工作集中在特征工程和传统方法比如逻辑回归,贝叶斯等等,提取了TF,IDF,LDA,POS等等特征,并进行了筛选,组合,后来我们使用基于TF(词频)和POS(词性标注)特征的LR(逻辑回归)算法在11月14号初赛结束前的提交中得到了0.57677的分数。而有趣的是,采用基于TF-IDF和POS的LR仅得到了0.56209的分数,即TF-IDF比纯TF还低一个多百分点,这可能也侧面说明了,在情感分析任务中,代表着词的“重要性”的逆文档频率IDF特征并没有那么重要,因为句子的情感是由整个句子的所有词综合决定,可能一个词并不重要,但是它对决定整个句子的情感却至关重要或者至少有着不可忽视的作用。chenminzoe的工作也集中于特征提取和偏竞赛类的方法比如SVM,XGBoost,GBDT等等上面,她尝试了一些自己探索的创新型的特征,也取得了不错的分数,在复赛中采用SVM模型取得过0.56708的高分,比初赛最好的模型CNN的0.5371高出了3个百分点,但是后来很难取得突破,我们猜想问题,第一个可能出在特征的组合方面,第二个可能出在我们对诸如SVM这些分类器的参数调优缺乏经验,第三个就是我们没有制定与线上一致的有效的线下评测,来对我们的参数进行多次的调优,这个问题同样也出现在传统分类器,以及笔者所做的CNN,RNN等分类器上,这也是我们队值得反思的一点。shizihao123的工作主要集中在视角抽取方面,首先探索的是模式匹配的方法,为了应对官方给的View不太全面和存在噪声的现象,他编写了诸多爬虫爬取各大汽车网站比如汽车之家,车主之家等的汽车品牌词库,以应对这个问题,并对这些词库使用了许多算法进行处理,以得到最大可能的汽车品牌词典,又尽可能少地引入噪声。开始我们就利用给的训练数据和爬取的汽车品牌词典等数据去匹配句子中的视角,速度极慢,整个测试集不到10000条数据,却需要跑一个晚上才能够全部提取出来,在复赛中我们经过商讨,采用了AC自动机来做精确匹配,原来一个晚上的时间缩短到了不到半个小时,同时shizihao123在视角品牌词筛选方面做了大量工作,去除了大量匹配到的却在当前语境中并非汽车品牌的词,这都为后面的情感分类提供了强大的助力。整个过程简图如下,
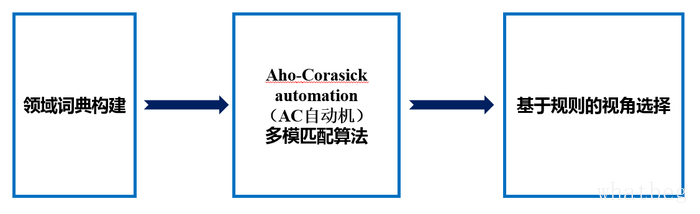
可以说,我们的视角工作做得非常丰富,可是不足在于我们的视角提取方法较为单一,对词典依赖比较强,有效性依赖于我们对词典的收集工作,取决于词典是否全面。笔者的主要工作在于CNN,RNN方面,在实现了基于词典和规则的方法后,我们经过调研,发现CNN在处理情感分析问题上面取得了一些成功,然后笔者阅读了大量论文,大致摸清了CNN处理情感分析的方法,然后基于TensorFlow对CNN情感分类算法进行了代码实现,第一次提交取得了0.51543的分数,此后我们进行了诸多优化,包括词向量的优化,参数的优化,数据输入的优化,值得一提的是,我们此时实现了一种相关句划分的数据预处理方式,因为此时的CNN模型是对整句进行一个情感分析,所以需要把句子分给句子所描述的视角,如果把句子分给了并非它所描述的视角,那么我们就会得出错乱的情感,也就降低了正确率。这部分工作由ArcherW来实现,主要是根据几个关键的标点符号来对句子进行划分,如逗号,感叹号等等,如果一个句子部分包含了某个视角,我们认为这部分描述了这个视角,理所当然在判断该视角的情感的时候,我们可以把这部分句子的情感判断一下,如果一个句子部分不包含任何视角,那么根据语言上的惯例,我们将这个句子部分和前一个句子部分归到一起,前一部分是描述哪个视角,这一部分也相应描述哪个视角。这样就得到了每个视角所对应的相关句,我们利用CNN对这些相关句进行情感分类,分类结果就是相关句所对应的视角的情感。在词向量优化方面,我们采用了搜狗实验室的全网新闻语料,还采用了搜狐新闻,网易新闻,以及各处下载的汽车新闻语料40M左右,后来继续增加词向量,从中国汽车新闻网,汽车之家等网站爬取了近300M的汽车语料进行训练,随着汽车语料的增加,词向量训练的越准确,从而每次增加语料后结果都得到一些提升。
在不断的优化后,从最初的0.51543的成绩,逐步提升,到0.52,0.58,到最后初赛A榜定榜,我们用CNN做出的成绩是0.5901,排在A榜24名。B榜出来后,我们最高成绩是0.56941,还是排在第24名。然后就进入复赛了。
复赛阶段,沿用CNN的方法只取得了0.5371的分数,让我们大失所望,传统的LR+TF+POS却在这时取得了0.56834的成绩,SVM方法也取得了0.56708的成绩,这不禁让我们怀疑到底是我们使用CNN的问题,还是CNN本身的局限性,此时我们也对深度学习有了更加深入的了解,我们发现RNN以其独特的对序列建模的能力,在自然语言处理领域发挥了巨大的作用,于是笔者开始钻研采用RNN体系的算法来解决情感分类的问题,这时候,一篇论文给了笔者巨大的启发,这也催生了我队解决情感分类任务的核心算法-BFGRU算法,算法框架如下图,
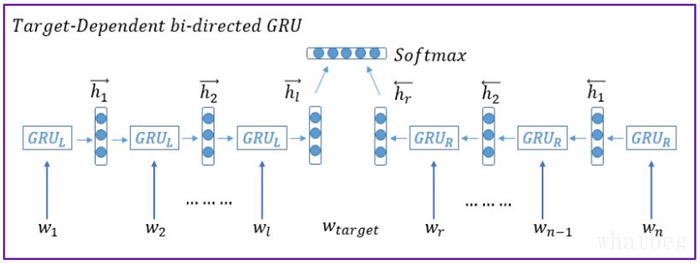
算法大致过程为,首先对视角进行提取,找出句子中的所有视角,每个视角会有一个句中的位置,对每个位置进行一次处理,将该位置左边的句子进行序列建模,采用GRU单元来进行状态存储,转换与记忆,最后得到一个输出,我们把它看做该位置的视角左边的语义对该视角的描述,输出为一个实值向量,然后我们再从句子最后跑一遍GRU直到该视角的右边,这又生成了该位置后面句子的语义对它的描述,综合前后的描述,再用softmax进行三分类,如此进行训练,就得到了对句子某个位置的视角进行情感判断的算法,这个算法我们称之为BFGRU(Bidirectional Focus Gated Recurrent Unit),是从TDLSTM延伸过来的。这个算法初次提交得到0.56813的分数,稍低于LR方法,后来经过各种各样的优化,不断得到提升,从0.59972,到0.63763,再进行视角情感投票法的采用,提升到0.64,再到0.643,最后A榜封榜时我们取得了0.6481的成绩,排在全榜第6!

最终进入决赛,虽然最后没有取得1,2名的荣誉,但是我们收获了很多,虽然艰辛,我们无悔。真的很谢谢大赛主办方。
最后,给出我们整个解决方案的框架图,
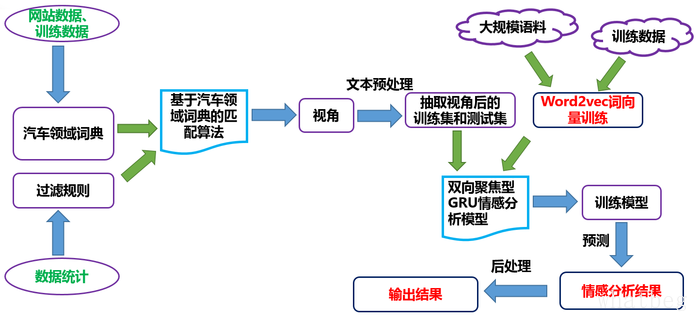
上面就是我们整个比赛的方案提出过程,以及其中的团队合作,成功与失败,点点滴滴,都构成了我们能够站上决赛舞台的基础。
应用场景
算法解决了汽车领域评论的基于视角的情感分析,提出了一套基于视角的情感分析的解决方案,包括视角提取的方案以及对于评论句进行准确的情感分类的方案。可以应用在汽车领域评论挖掘,情感分析,汽车销售指导,由于视角提取的方案是与情感分类的方案分离的,所以我们可以将视角抽取推广到方面(aspect)抽取,得到对产品某个方面的评价,比如汽车中的油耗,空间等等。进一步的,我们可以推广到各种各样的领域,而不只是局限于汽车领域,在购物网站中完全可以用到我们的这套方案。我们的方案还可以用于舆情分析领域,对社会媒体或者自媒体的评论或者状态或者消息进行情感分析,了解社会中人们对于某个热点事件的看法,这有着巨大的意义。

商业潜力
由于时间关系,我们只采用了单个情感分类算法,所以进一步我们还可以对算法进行进一步的优化,探索,在集成学习方面做一些工作,扩展价值巨大。
寻求合作/资源
我们希望与对汽车领域评论挖掘有所需求的商户或者汽车厂商,我们可以帮他们挖掘出客户的评论中的价值,对它们的生产,销售起到一定的知道作用,我们相信,这里面的商业潜力是巨大的。当然,不止汽车领域,各个领域,只要是对用户/客户评论信息有挖掘需求的企业,都可以找我们合作。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

