浅析ReDoS的原理与实践
*本文原创作者:MyKings,本文属FreeBuf原创奖励计划,未经许可禁止转载
ReDoS(Regular expression Denial of Service) 正则表达式拒绝服务攻击。开发人员使用了正则表达式来对用户输入的数据进行有效性校验, 当编写校验的正则表达式存在缺陷或者不严谨时, 攻击者可以构造特殊的字符串来大量消耗服务器的系统资源,造成服务器的服务中断或停止。
1 常见术语
先让我们来了解几个概念:
1.1 Regex
正则表达式( Regular Expression, Regex )是由字符( 可为英文字母、数字、符号等 )与元字符( 特殊符号 )组成的一种有特定规则的特殊字符串。在模式匹配中,正则表达式通常被用于验证邮箱、URL、手机号码等。
常用元字符:
| 元字符 | 说明 |
|---|---|
| / | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“ n ” 匹配字符 “ n ”。“ /n ” 匹配一个换行符。序列 “ // ” 匹配 “ / ” 而 “ /( ” 则匹配 “ ( ”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性, ^ 也匹配 “ /n ” 或 “ /r ” 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性, $ 也匹配 “ /n ” 或 “ /r ” 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如, zo* 能匹配 “ z ”、“ zo ” 以及 “ zoo ”。 * 等价于 {0,} 。 |
| + | 匹配前面的子表达式一次或多次。例如,“ zo+ ” 能匹配 “ zo ” 以及 “ zoo ”,但不能匹配 “ z ”。 + 等价于 {1,} 。 |
| ? | 匹配前面的子表达式零次或一次。例如,“ do(es)? ” 可以匹配 “ do ” 或 “ does ” 中的 “ do ”。 ? 等价于 {0,1} 。 |
| . | 匹配除 “ /n ” 之外的任何单个字符。要匹配包括 “ /n ” 在内的任何字符,请使用像 “ (./$/lambda_1$/n) ” 的模式。 |
| (pattern) | 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用 “ /( ” 或 “ /) ”。 |
| /w | 匹配包括下划线的任何单词字符。等价于 “ [A-Za-z0-9_] ”。 |
| /W | 匹配任何非单词字符。等价于 “ [^A-Za-z0-9_] ”。 |
更多元字符请参考: 维基百科
1.2 DoS & DDoS
拒绝服务攻击( Denial-of-Service Attack )亦称洪水攻击,是一种网络攻击手法,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。
分布式拒绝服务攻击( Distributed Denial-of-Service Attack ),是使用网络上两个或两个以上被攻陷的电脑作为 “ 僵尸 ” 向特定的目标发动 “ 拒绝服务 ” 式攻击。
DDoS攻击可以具体分成两种形式:
- 带宽消耗型攻击
- 洪水攻击
UDP、ICMP、ping of death
- 放大攻击
NTP、DNS
- 洪水攻击
- 资源消耗型攻击
SYN洪水、LAND attack、CC
1.3 FSM、DFA、 NFA
有限状态自动机:(FSM “finite state machine” 或者FSA “finite state automaton” )是为研究有限内存的计算过程和某些语言类而抽象出的一种计算模型。有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。
有限状态自动机还可以分成确定与非确定两种, 非确定有限状态自动机可以转化为确定有限状态自动机。
正则表达式引擎分成两类:一类称为 DFA(确定性有限状态自动机) ,另一类称为 NFA(非确定性有限状态自动机) 。两类引擎要顺利工作,都必须有一个正则式和一个文本串,一个捏在手里,一个吃下去。 DFA 捏着文本串去比较正则式,看到一个子正则式,就把可能的匹配串全标注出来,然后再看正则式的下一个部分,根据新的匹配结果更新标注。而 NFA 是捏着正则式去比文本,吃掉一个字符,就把它跟正则式比较,匹配就记下来:“某年某月某日在某处匹配上了!”,然后接着往下干。一旦不匹配,就把刚吃的这个字符吐出来,一个个的吐,直到回到上一次匹配的地方。
部分程序及其所使用的正则引擎:
| 引擎类型 | 程序 |
|---|---|
| DFA | awk(大多数版本)、egrep(大多数版本)、flex、lex、MySQL、Procmail |
| 传统型 NFA | GNU Emacs、Java、grep(大多数版本)、less、more、.NET语言、PCRE library、Perl、PHP(所有三套正则库)、Python、Ruby、set(大多数版本)、vi |
| POSIX NFA | mawk、Mortice Lern System’s utilities、GUN Emacs(明确指定时使用) |
| DFA/NFA混合 | GNU awk、 GNU grep/egrep、 Tcl |
2 ReDoS 原理
2.1 概述
DFA 对于文本串里的每一个字符只需扫描一次,比较快,但特性较少; NFA 要翻来覆去吃字符、吐字符,速度慢,但是特性(如:分组、替换、分割)丰富。 NFA 支持 惰性(lazy) 、 回溯(backtracking) 、 反向引用(backreference) , NFA 缺省应用 greedy 模式, NFA 可能会陷入递归险境导致性能极差。
2.2 说明
我们定义一个正则表达式 ^(a+)+$ 来对字符串 aaaaX 匹配。使用 NFA 的正则引擎,必须经历 2^4=16 次尝试失败后才能否定这个匹配。同理字符串为 aaaaaaaaaaX 就要经历 2^10=1024 次尝试。如果我们继续增加 a 的个数为20个、30个或者更多,那么这里的匹配会变成指数增长。
下面我们以 python 语言为例子来进行代码的演示:
#!/usr/bin/env python
# coding: utf-8
import re
import time
def exp(target_str):
"""
"""
s1 = time.time()
flaw_regex = re.compile('^(a+)+$')
flaw_regex.match(target_str)
s2 = time.time()
print("Consuming time: %.4f" % (s2-s1))
if __name__ == '__main__':
str_list = (
'aaaaaaaaaaaaaaaaX', # 2^16
'aaaaaaaaaaaaaaaaaaX', # 2^18
'aaaaaaaaaaaaaaaaaaaaX', # 2^20
'aaaaaaaaaaaaaaaaaaaaaaX', # 2^22
'aaaaaaaaaaaaaaaaaaaaaaaaX', # 2^24
'aaaaaaaaaaaaaaaaaaaaaaaaaaX', # 2^26
'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaX', # 2^36
)
for evil_str in str_list:
print('Current: %s' % evil_str)
exp(evil_str)
print('--'*40)
把上面的代码保存成 redos.py 文件并执行这个 py 脚本文件:
$ python redos.py Current: aaaaaaaaaaaaaaaaX Consuming time: 0.0043 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaX Consuming time: 0.0175 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaaaX Consuming time: 0.0678 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaaaaaX Consuming time: 0.2370 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaaaaaaaX Consuming time: 0.9842 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaaaaaaaaaX Consuming time: 4.1069 -------------------------------------------------------------------------------- Current: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaX
输出到最后一行貌似程序卡住了,我们来看下电脑的 CPU:
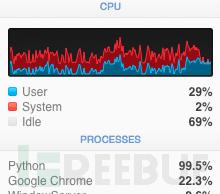
CPU利用率已经快接近100%了,我们在分别执行两次( 电脑配置低的慎重操作 ):
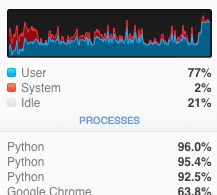
2.3 总结
每个恶意的正则表达式模式应该包含:
- 使用重复分组构造
- 在重复组内会出现
- 重复
- 交替重叠
有缺陷的正则表达式会包含如下部分:
-
(a+)+ -
([a-zA-Z]+)* -
(a|aa)+ -
(a|a?)+ -
(.*a){x} | for x > 10
注意: 这里的 a 是个泛指
2.4 实例
下面我们来展示一些实际业务场景中会用到的缺陷正则。
-
英文的个人名字:
- Regex:
^[a-zA-Z]+(([/'/,/./-][a-zA-Z ])?[a-zA-Z]*)*$ - Payload:
aaaaaaaaaaaaaaaaaaaaaaaaaaaa!
- Regex:
-
Java Classname
- Regex:
^(([a-z])+.)+[A-Z]([a-z])+$ - Payload:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
- Regex:
-
Email格式验证
- Regex:
^([0-9a-zA-Z]([-./w]*[0-9a-zA-Z])*@(([0-9a-zA-Z])+([-/w]*[0-9a-zA-Z])*/.)+[a-zA-Z]{2,9})$ - Payload:
a@aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
- Regex:
-
多个邮箱地址验证
- Regex:
^[a-zA-Z]+(([/'/,/./-][a-zA-Z ])?[a-zA-Z]*)*/s+<(/w[-._/w]*/w@/w[-._/w]*/w/./w{2,3})>$|^(/w[-._/w]*/w@/w[-._/w]*/w/./w{2,3})$ - Payload:
aaaaaaaaaaaaaaaaaaaaaaaa!
- Regex:
-
复数验证
- Regex:
^/d*[0-9](|./d*[0-9]|)*$ - Payload:
1111111111111111111111111!
- Regex:
-
模式匹配
- Regex:
^([a-z0-9]+([/-a-z0-9]*[a-z0-9]+)?/.){0,}([a-z0-9]+([/-a-z0-9]*[a-z0-9]+)?){1,63}(/.[a-z0-9]{2,7})+$ - Payload:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
- Regex:
使用 python 来进行测试有缺陷的正则示例:
$ python -c "import re;re.match('^[a-zA-Z]+(([/'/,/./-][a-zA-Z ])?[a-zA-Z]*)*$', 'aaaaaaaaaaaaaaaaaaaaaaaaaaaa!')"
3 ReDoS 防范
哪里会用到 Regex , 几乎在我们的网络程序与设备资源的任何位置都会用到。如: WAF 、 Web前端 、 Web后端 、 DB数据库 等。
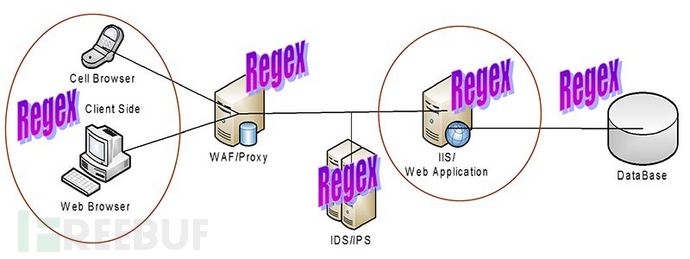
3.1 常见位置
客户端
- 浏览器
- 移动设备
服务器端
3.2 防范手段
防范手段只是为了降低风险而不能百分百消除 ReDoS 这种威胁。当然为了避免这种威胁的最好手段是尽量减少正则在业务中的使用场景或者多做测试, 增加服务器的性能监控等。
- 降低正则表达式的复杂度, 尽量少用分组
- 严格限制用户输入的字符串长度(特定情况下)
- 使用单元测试、fuzzing 测试保证安全
- 使用静态代码分析工具, 如: sonar
- 添加服务器性能监控系统, 如: zabbix
2.5 参考链接
- 《精通正则表达式》
- http://blog.csdn.net/c601097836/article/details/47040703
- http://hooopo.iteye.com/blog/548087
- http://www.guoziweb.com/archive/1160.html
- https://swtch.com/~rsc/regexp/regexp1.html
- https://www.owasp.org/index.php/Regular_expression_Denial_of_Service_-_ReDoS
- https://en.wikipedia.org/wiki/ReDoS
- https://www.checkmarx.com/wp-content/uploads/2015/03/ReDoS-Attacks.pdf
- https://www.exploit-db.com/docs/38149.pdf
- https://www.owasp.org/index.php/Regular_expression_Denial_of_Service_-_ReDoS
- https://www.owasp.org/images/3/38/20091210_VAC-REGEX_DOS-Adar_Weidman.pdf
- https://www.owasp.org/index.php/OWASP_Validation_Regex_Repository
*本文原创作者:MyKings,本文属FreeBuf原创奖励计划,未经许可禁止转载
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

