RocketMQ大数据畅想
刚刚过去的双十一,阿里自主研发的消息中间件RocketMQ,充分展现了它的低延迟特性,大部分消息请求落在2ms内,慢请求也都落在20ms内,这无疑给追求快速响应的在线交易系统(OLTP)带去了福音。
也是在今年11月份,RocketMQ进入Apache孵化。这款最初设计来为淘宝交易系统异步解耦、削峰填谷的消息中间件,开始走出国门,为世界上的用户提供服务。自然地,RocketMQ将来不仅仅只服务于在线系统,对于离线或半离线系统,尤其是大数据领域,RocketMQ也将为其绽放自己的光彩。
Kafka大数据的杀手锏
谈到大数据领域内的消息传输,则绕不开Kafka。这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用,被LinkedIn,Uber, Twitter, Netflix等大公司所采纳,而storm,spark,flink等大数据流处理或批处理平台都有Kafka的相关插件支持。
那么,Kafka的百万级TPS是如何做到的呢?
有很多相关的分析,比如异步IO,PageCache,异步刷盘,消费过程零拷贝,Batch等,这些都对,但是没有一个直观的说明,这众多因素中,哪一个才是杀手锏呢?
笔者对这个问题进行了一些探究,在揭晓之前,请看下图:
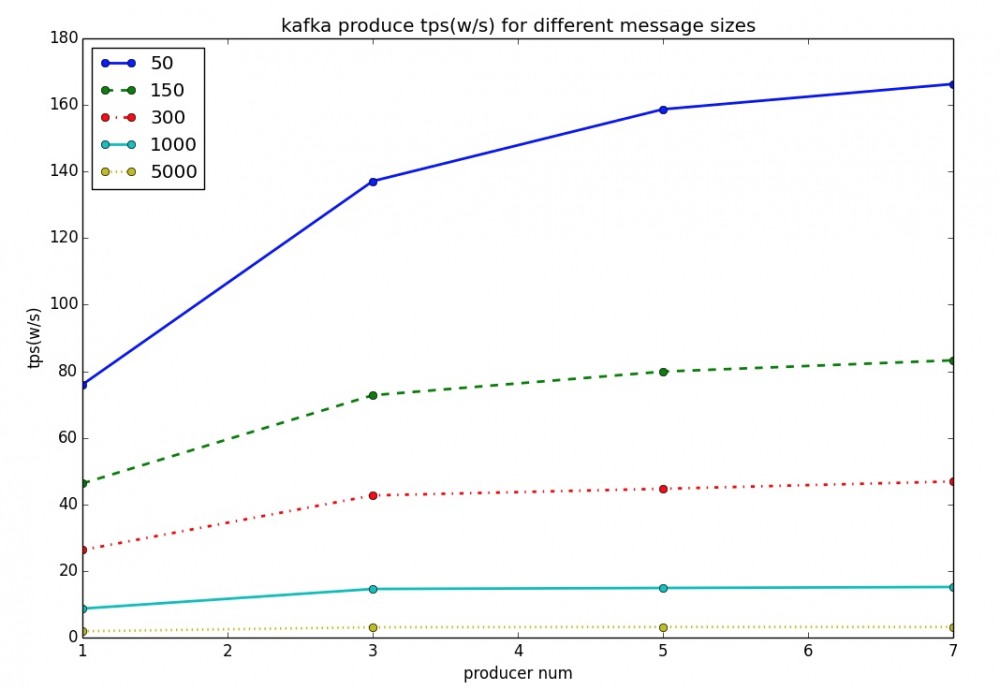
注:一台物理机部署Kafka,另一台物理机施加压力,每个producer异步发送,异步统计结果;本文所涉及的机器配置都是24核48G内存SSD盘
从上图可以看出,当单个消息体为50字节时,kafka单机的吞吐量确实表现出色,能达到百万级。可是当单个消息体为5k字节时,TPS极速下降,只有大约3万多,少了两个数量级。
对此,可能有人会说那是因为网卡打满了,还有就是因为消息体变大,每次能batch的数量变少了,导致整体TPS下降。
都有可能,笔者测试时网卡虽然没有打满,却确实是负载比较高了。因此,为了排除因素,笔者还做了另外一个测试如下:
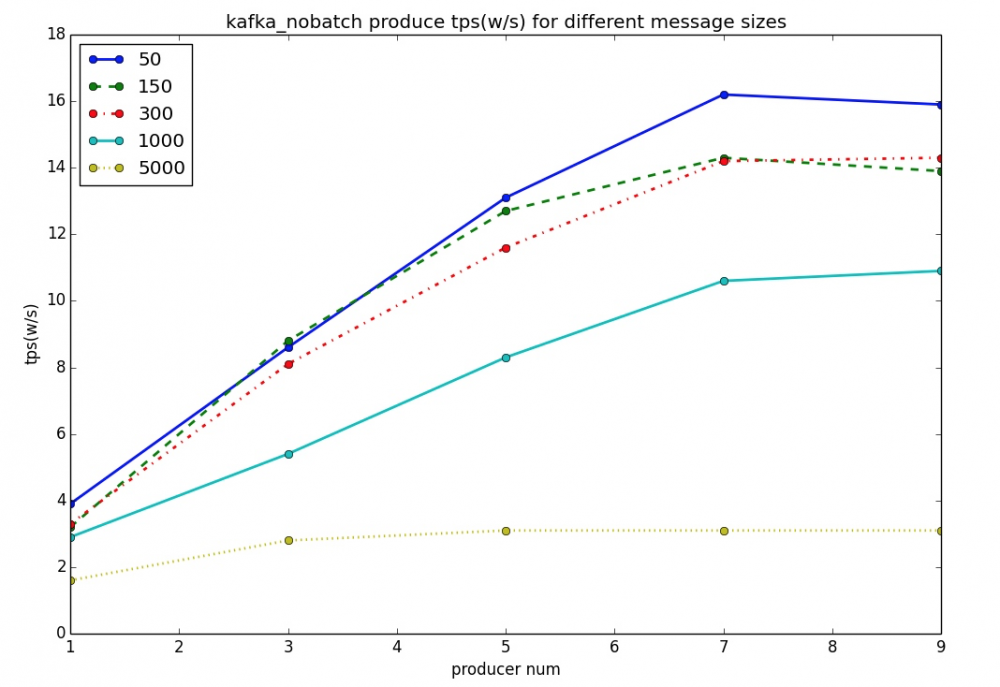
上图可以清晰地看出,50字节时,Kafka no batch(batch size设为1)时的吞吐量只有15万多,只有启用batch时的十分之一,而RocketMQ也可以很轻松地达到这个水平。
至此,可以直观地充分说明,Kafka达到百万级TPS的杀手锏就是 batch !
batch, 简单说就是把多个消息打包一次性发过去,对于在线交易系统来说,这通常不是一个好的选择,会导致消息大量丢失或者大量重复,延迟也会加大。但对于大数据领域来说,由于大部分都是离线半离线的计算,对数据可靠性要求没有那么高,但追求高吞吐量。Kafka为适应大数据,选择了batch,因此,赢得了大数据的欢迎。
RocketMQ大数据的无限潜力
到这里,自然会有一个疑问,如果把batch特性用到RocketMQ中,效果会如何呢?
按照上面的结论进行推测,batch特性势必也能大大提高RocketMQ的吞吐量。但如果要实践证明,需要做一些工作。
为了直观地证明batch对于RocketMQ的功效,笔者在Kafka Broker做了一层代理,大致结构图如下:
Kafka Broker收到Kafka Client的Batch Data后,不存储在本地,而是把消息转发到RocketMQ,等待RocketMQ返回结果后,再返回给Kafka Client。
笔者用一台物理机部署Kafka Broker作为Proxy,同时用另一台同样配置的物理机部署RocketMQ作为存储,然后用另一台物理机来对Proxy进行施加压力,结果如下图:
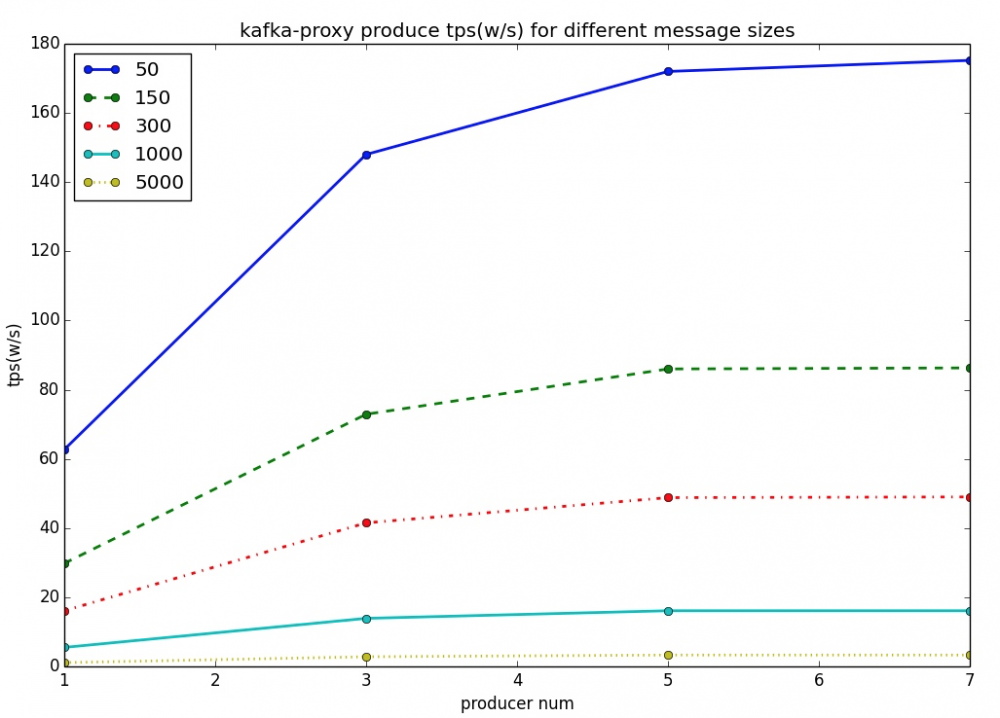
这个结果与上面关于Kafka的结果相互印证,既证明了Kakfa大数据的杀手锏在于batch,同时也展现了RocketMQ在大数据领域的无限潜力,并不逊色于Kafka。
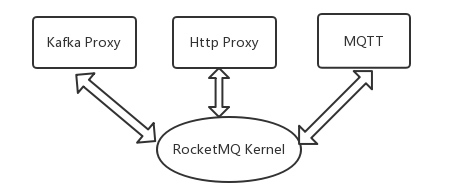
Proxy与RocketMQ Kernel
RocketMQ最初是为交易系统而生,现在也不会忘记这一初心,但其也绝不会固步自封。面对越来越多的来自各个领域的用户,他们有着各自不一样的复杂应用场景,这给RocketMQ带来了挑战,也带来了机遇。未来的RocketMQ会继续保持初心,维护自己Kernel的本色,但也会增加一些外围功能,以适应各种不同的场景,如面向大数据的Kakfa Proxy,面向物联网的MQTT,面向REST的Http Proxy。
最后,这一切只是开始,更多的想象空间,需要大家一起来创造。
正文到此结束
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

