SeaweedFS概述
文件系统在后端开发中,是非常重要的组件,当有存储图片或者视频的时候,文件系统就派上用场了;例如阿里为淘宝上的大量图片存储开发了分布式文件系统TFS和FastDFS,有些直播软件上视频也是存储在文件系统上等等;因此如果是从事后端开发或者分布式存储开发,也必须好好学习研究下文件系统;seaweedfs文件系统实现了Facebook's Haystack文件系统设计论文,它并不支持Linux操作系统中POSIX文件系统语义,而是选择实现了key->file存储形式,类似于NoSQL,我们也可以称呼为NoFS;

这篇博客,不会深入分析seaweedfs文件系统原理,这里只是简单的介绍,作为之前一段时间的总结;所以这篇文章包括下面3小点:
- seaweedfs文件系统架构;
- seaweedfs操作例子;
- 总结;
SeaweedFS文件系统架构
分布式文件系统的拓扑结构大体都类似,分为NameNode和DataNode,NameNode负责管理数据节点拓扑结构以及元数据,DataNode负责真实数据存储;在seaweedfs文件系统中,NameNode称为Master,DataNode称为VolumeServer;我们先来看下seaweedfs文件系统整体的拓扑结构:
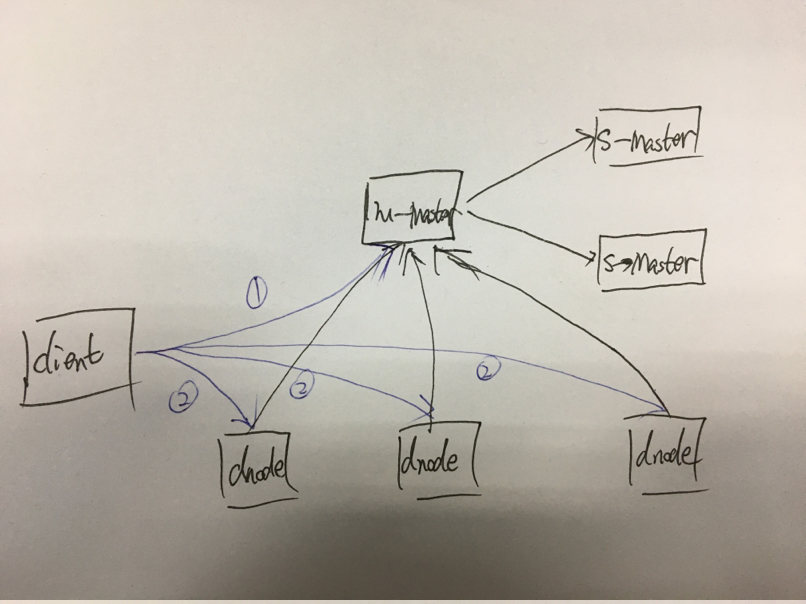
由架构图可以看出,
- Master负责管理集群的拓扑结构,分为主从结构,并采用raft实现主从复制和高可用,以此消除单点问题;TFS中的NameNode为了消除单点问题,采取的是虚拟IP配上lvs;
- DataNode负责存储具体数据,并与M-Master保持心跳,上报自己的存储信息;
当客户端需要存储数据时,
- 需要先给M-Master发送请求,获取该文件存储的DataNode地址,文件存储的VolumeID以及文件fid;
- 然后客户端接着将文件发送至从Master获取到的DataNode,DataNode会根据VolumeID找到相应的Volume,并将文件存储到该Volume;
分布式文件系统数据节点存储数据时,会创建出若干个大文件(可以想象为磁盘),用于存储小文件,例如文件,短视频等等;在seaweedfs中,大文件就称为Volume;
ok,上述是正常情况下seaweedfs运行时的整体架构图,但是机器的东西,说不准哪天就挂了,特别是Master,因为Master挂了,整个文件系统就不可用了;在seaweedfs是通过raft实现高可用,即使M-Master挂了,会通过选举算法,在S-Master选举出新的M-Master,然后所有DataNode则将自己的信息上报给新的M-Master;结构图如下:
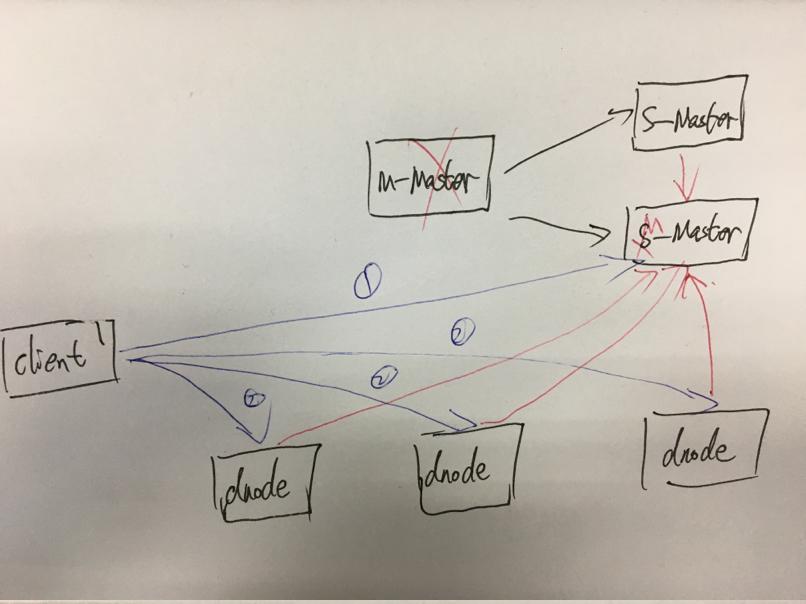
图中可以看出,当M-Master挂了之后,剩余两个S-Master会进行选举,产生新的M-Master,此时所有的DataNode将会连接到新的M-Master,并上报自己的存储信息;而客户端下次需要存储文件时,会先到选举产生的新M-Master获取DataNode信息,然后再将文件存储到具体DataNode;
这里,client是如何连接到新的M-Master的,我不是很清楚,因此没有在实际生产环境中部署使用过,但是我觉得可以通过客户端轮询来实现;
接下来,我们来看下Master拓扑结构,如下图:
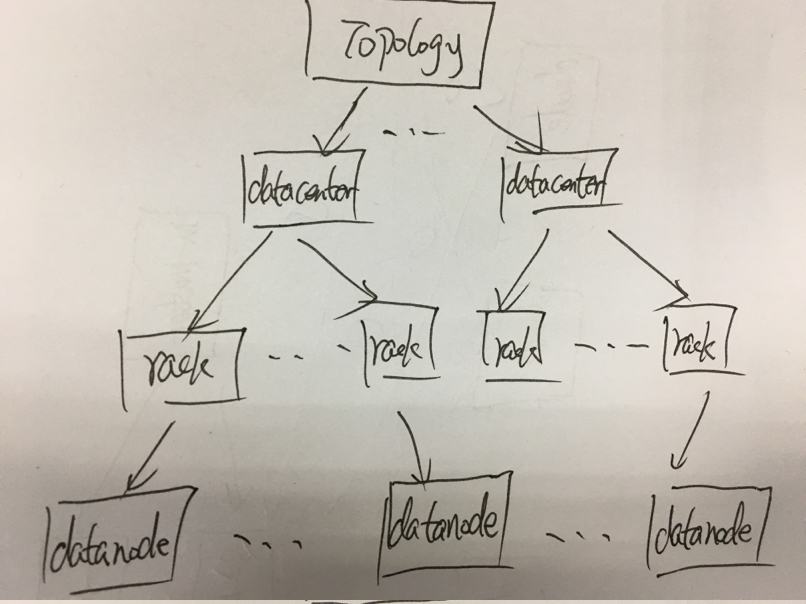
seaweedfs拓扑结构主要有三个概念,数据中心(DataCenter),机架(Rack),数据节点(DataNode);这样可以很灵活配置不同数据中心,同一个数据中心下不同机架,同一机架下不同的数据节点;数据都是存储在DataNode中;
最后再来看下DataNode存储节点Volumn布局;如下:
+-------------+ | SuperBlock | +-------------+ | Needle1 | +-------------+ | Needle2 | +-------------+ | Needle3 | +-------------+ | Needle... | +-------------+
一般情况下,一个DataNode会配置多个Volume,这样可以避免多个客户端对同一个Volume读写争抢;每个Volume由一个SuperBlock和若干个Needle组成;每个Needle则代表一个小文件,例如图片和短视频;
SeaweedFS操作例子
客户端访问seaweedfs,主要是通过http协议,我们通过以下例子来说明;首先开启一个Master以及两个DataNode
./weed master ./weed volume -dir="/tmp/1" -max=5 -mserver="localhost:9333" -port=8080 ./weed volume -dir="/tmp/2" -max=5 -mserver="localhost:9333" -port=8081
-dir表示该DataNode数据存储的目录,-max表示volume个数最大值,-mserver表示Master地址,-port该DataNode监听的端口;
首先从Master获取一个fid:
> curl -X POST http://localhost:9333/dir/assign
{"fid":"3,017ebf0b02","url":"127.0.0.1:8081","publicUrl":"127.0.0.1:8081","count":1}
这里fid中,3表示volumeid,01表示文件的序号,7ebf0b02表示cookie
然后,我们访问127.0.0.1:8081,并传入fid以及文件存储,如下:
> curl -X PUT -F file=@/home/charles/myphoto.jpg http://127.0.0.1:8081/3,017ebf0b02
{"name":"myphoto.jpg","size":61188}
这样,图片就已经存储到127.0.0.1:8081DataNode上第3个volume上了;我们可以在浏览器通过链接http://127.0.0.1:8081/3,017ebf0b02访问到刚才存储的图片;
总结
这篇文章只是简单的介绍seaweedfs的架构以及原理,同时通过简单的上传图片展示如何使用seaweedfs,算是学习记录,也希望给看者入门材料;之前在实习时,看了TFS,了解文件系统大体架构,因此看快就熟悉了seaweedfs的架构;但是seaweedfs使用的是http协议,而TFS使用的是自己设置的协议并且是C++编写,seaweedfs会比TFS简单易懂,而且自带系统后台,方便查看集群信息;
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

