谈谈字符编码那些事
最近在网上看到一个段子,在window下,新建一个记事本文件,写入联通两个字后保存,再次打开会出现两个黑色方块。有个人吐嘈说,中国联通得罪微软。当然这只是开玩笑而已。具体原因,涉及到字符编码的问题了,下面由我慢慢道来。
ASCII
在计算机中,任何信息都是由二进制存储的。存储最基础的单元是位,而8位一组就形成一个字节。一个字节有8位,一位又有0与1两种状态表示。所以总共有2的8次幂256种变化,每一种变化可以代表一种字符。那么问题来了,如何对应这些字符与二进制位呢?
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定,也就是现在的ASCII码。ASCII码规定有128个字符,占0-127位,包括最基本的英文字母、标点符号。ASCII又被称为7位码,因为它实际运用到的只有7位来编码,而第一位总是为0。例如,空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。 ASCII码表
ANSI
后来由于越来越多国家使用计算机,ASCII码不能满足其它国家语言需要。比如说,中文就有几千个汉字,ASCII码最多也就只有256种字符。所以很多国家就开发一套自己的文字编码,例如,简体中文GB2312,繁体中文的BIG5,日文的JIS,这些编码统称为ANSI。
其中我们重点谈谈简体中文GB2312。GB2312用一个字节表示最基本的英文字母、标点符号,编码规则与ASCII一样,因此它向下兼容ASCII。而对于汉字字符,它则用两个字节表示。GB2312编码的汉字只有几千个,不包含一些生僻的字,导致有一些人名无法显示。后来升级到GBK,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。现在最新的是GB18030,加入了一些国内少数民族的文字,一些生僻字被编到4个字节,每扩展一次都完全保留之前版本的编码,所以每个新版本都向下兼容。
各个国家都有像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码。这些编码互相不兼容,导致同一个编码在不同标准下显示是不一样的。比如说,编码1645在简体中文GB2312下是汉字丑,而编码1645在日文JIS下并没有对应的字符,这时就会出现乱码。在日常生活中,很多时候我们发给外国友人的电子邮件会出现乱码,也是这个原因。那为什么我们去浏览某些不可描述的日本网站时,却不会出现乱码呢?那得多亏了Unicode。
Unicode
Unicode由ISO国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是”Universal Multiple-Octet Coded Character Set”,简称为UCS。在UCS中,每个字符都有唯一与之对应的编码,比如说简体汉字丑的Unicode是4E01(二个字节),繁体汉字的醜的Unicode是919C(二个字节)。而对于一些比较靠后的字符,其编码可达到四个字节。Unicode解决了传统的字符编码方案的局限,但是它本身也存在一些问题:
-
在ASCII中,英文字母只用一个字节表示就够了。如果Unicode统一规定,每个字符用二个字节表示,那么每个英文字母都必然有一个字节空间是浪费的,这对于存储空间来说是极大的浪费。
-
如何才能区别Unicode和ASCII?计算机怎么知道二个字节表示一个字符,而不是分别表
示二个字符呢?
Unicode在很长一段时间内无法推广,直到互联网的出现。为解决Unicode如何在网络上传输的问题,面向传输的众多 UTF(UCS Transfer Format)标准出现了。其主要的有UTF-8与UTF-16,此外还有比较少见的UTF-32与UTF-7。这里的概念要搞清,Uniocde只是一套字符集,收录字符与编码的对应规则,但是它没有规定这些编码如何传输,存储。而UTF是Uniocde的具体实现方式。
UTF-16
UTF-16以每2个字节为一个单元,每个字符由1-2个单元组成,所以每个字符可能是2个字节或者4个字节,包括最常见的英文字母都会编成两个字节。大部分汉字也是2个字节,少部分生僻字为4个字节。在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是”Byte Order Mark”,简称BOM。在Unicode编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在Unicode中是不存在的字符,所以不应该出现在实际传输中。Unicode规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的,即为UTF-16BE;如果收到FFFE,就表明这个字节流是Little-Endian的,即即为UTF-16LE。
有时,我们会见到USC-2与USC-4,这两货又是什么呢?早期Unicode收编的字还不多时,两个字节足够表示所有字符,所以有一种固定为两个字节的UTF,叫UCS-2。UTF-16的两个字节部分和UCS-2完全一样,所以UTF-16向下兼容UCS-2。UCS-2同样分LE和BE。同样的少见的UFT-32,其实也就是USC-4。
UTF-16也有一个很大的问题,由于UTF-16只能由2个字节或者4个字节组成,它不兼容ASCII码。而UTF-8的出现,就能很好的解决这两个问题。
UTF-8
UTF-8最大的一个特点,就是它是一种变长的编码方式,并且完全兼容ASCII码。它可以使用1~4个字节表示一个字符,根据不同的字符而变化字节长度。 UTF-16的编码与Unicode一样,但是从Unicode到UTF-8却不是直接的对应,而是要通过一些算法和规则来转换。UTF-8的编码规则很简单,只有二条:
-
对于单字节的字符,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
-
对于n字节的字符(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
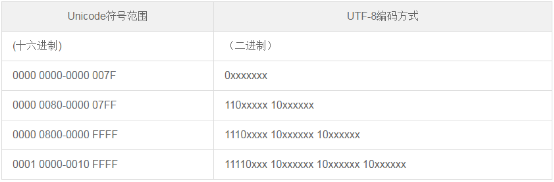
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001,用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
相应的,UTF-8也有BOM,”ZERO WIDTH NO-BREAK SPACE”字符在UTF-8中的编码为EF BB BF 。所以一般检测到BOM为EF BB BF,就知道此文件编码格式是UTF-8了。
代码页
目前Windows的内核已经支持Unicode字符集,这样在内核上可以支持全世界所有的语言文字。但是由于现有的大量程序和文档都采用了某种特定语言的编码,例如GBK,Windows不可能不支持现有的编码,而全部改用Unicode。Windows使用代码页(code page)来适应各个国家和地区。所谓代码页(code page)就是针对一种语言文字的字符编码。GBK的code page是CP936,BIG5的code page是CP950,GB2312的code page是CP20936。想要知道自己系统默认是哪个代码页,可以在CMD上输入chcp指令查看。
Windows可以同时支持多个代码页。只要文件能说明自己使用什么编码,用户又安装了对应的代码页,Windows就能正确显示,例如在HTML文件中就可以指定 meta标签中的 charset来读取不同的代码页,比如中文的就可以设置为GBK。但是如果外国人浏览这个HTML文件时,由于系统没有相应的GBK代码页,这个HTML文件就会出现乱码。
如何识别字符编码
这么多字符编码,软件打开时如何知道是哪个编码?如何开头有BOM的话,可以靠BOM来识别:
- EF BB BF —— UTF-8
- FF FE —— UTF-16(Little-Endian)
- FE FF —— UTF-16(Big-Endian)
BOM只针对Unicode系列编码,ANSI通通不会有BOM。例如GBK就没有BOM。那如果没有BOM呢?该怎么办?猜?没错,只能靠猜了。软件读入文件时将所有编码都试一下,看哪个像。很显然,没有BOM难免偶然猜错。所以我们开始说的那个联通乱码的原因,就是猜错了。
联通乱码原因
在记事本保存操作中,windows默认保存的编码是ANSI(在中国是GBK)。
“联”ANSI编码是 0xC1AA , 二进制排列是 11000001 10101010 ;
“通”ANSI编码是 0xCDA8 , 二进制排列是 11001101 10101000 ;
这两个字的二进制是不是看起来好眼熟,没错就是和上面的UTF-8编码规则相似。
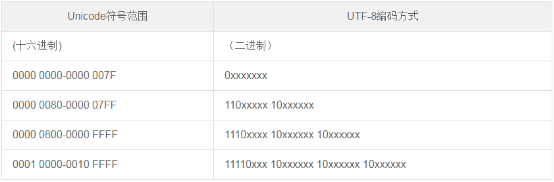
“联通”这两个字的ANSI编码符合UTF8编码的第二个模板。“联”的两个字节、“通”的两个个字节的起始部分的都是”110”和”10”,正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本就误认为这是一个UTF8编码的文件,猜错了导致乱码。当然不止联通,所有的编码在【 11000000<=第一个字节<=11011111】 【 10000000 <=第二个字节<= 10111111】 的字符都出现乱码,例如“力挺联通”也会出现乱码。
扯了这么多,那么这个问题怎么解决呢。其实很简单,记事本保存时,有一个另存为的菜单,选择编码为UTF-8就可以了。
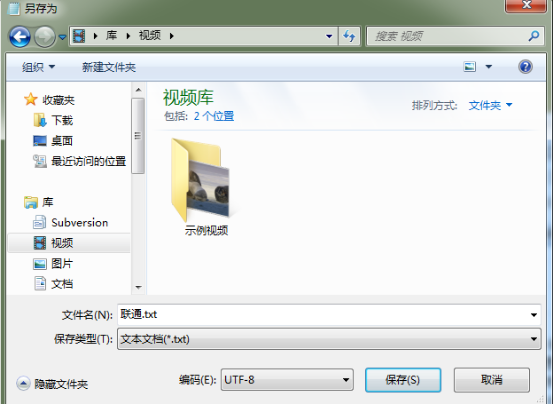
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

