开源|LightGBM:三天内收获GitHub 1000 星

【导读】不久前 微软DMTK(分布式机器学习工具包)团队 在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000 次,fork了200 次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式”,“代码清晰易懂”,“占用内存小”等。本文邀请了微软亚洲研究院DMTK团队的研究员们为我们撰文解读,教你玩转LightGBM。
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务。GBDT也是各种数据挖掘竞赛的致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。
LightGBM (Light Gradient Boosting Machine)(请点击 https://github.com/Microsoft/LightGBM )是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有以下优点:
● 更快的训练速度
●更低的内存消耗
●更好的准确率
●分布式支持,可以快速处理海量数据
从LightGBM的GitHub主页上可以直接看到实验结果:
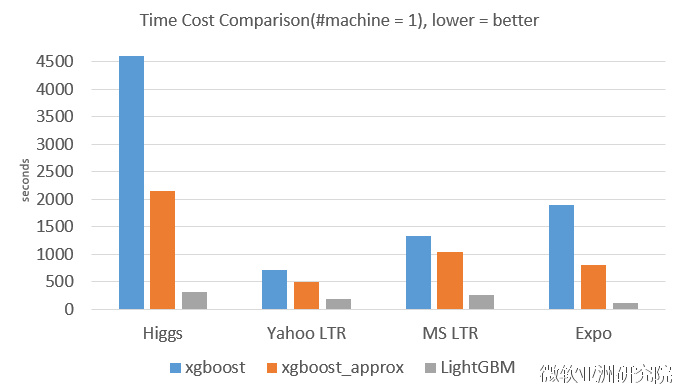
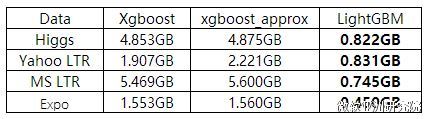
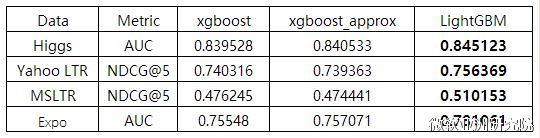
从下图实验数据可以看出,在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,并且准确率也有提升。在其他数据集上也可以观察到相似的结论。
训练速度方面
内存消耗方面
准确率方面
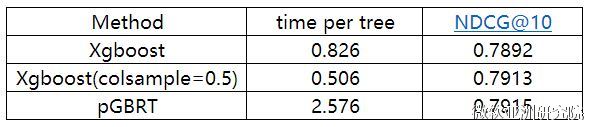
(我们只和xgboost进行对比,因为xgboost号称比其他的boosting 工具都要好,从他们的实验结果来看也是如此。) XGBoost 与其他方法在Higgs-1M数据的比较:
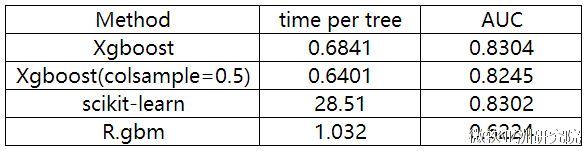
XGBoost 与其他方法在Yahoo LTR数据的比较:
看完这些惊人的实验结果以后,对下面两个问题产生了疑惑:
Xgboost已经十分完美了,为什么还要追求速度更快、内存使用更小的模型?
对GBDT算法进行改进和提升的技术细节是什么?
提出LightGBM的动机
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。
而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
改进的细节
1.Xgboost是如何工作的?
目前已有的GBDT工具基本都是基于预排序的方法(pre-sorted)的决策树算法(如 xgboost)。这种构建决策树的算法基本思想是:
首先,对所有特征都按照特征的数值进行预排序。
其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。
最后,找到一个特征的分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是能精确地找到分割点。
缺点 也很明显:
首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
2.LightGBM在哪些地方进行了优化?
基于Histogram的决策树算法带深度限制的Leaf-wise的叶子生长策略直方图做差加速直接支持类别特征(Categorical Feature)Cache命中率优化基于直方图的稀疏特征优化多线程优化下面主要介绍Histogram算法、带深度限制的Leaf-wise的叶子生长策略和直方图做差加速。
Histogram算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
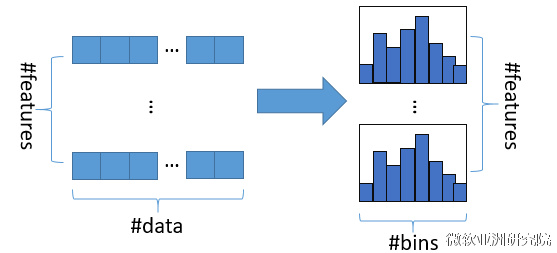
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
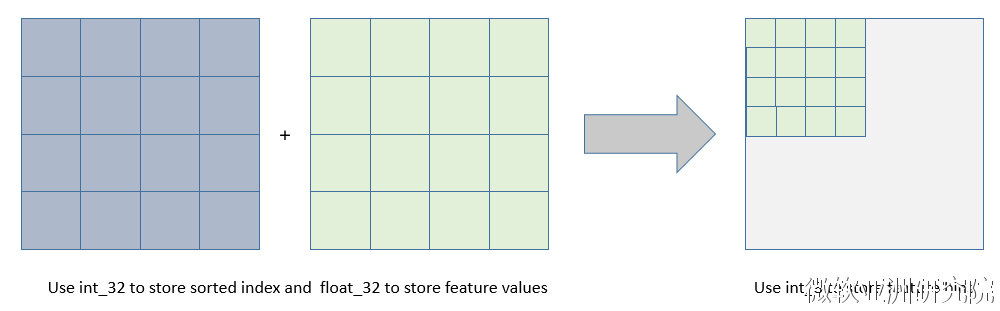
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data*#feature)优化到O(k*#features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
带深度限制的Leaf-wise的叶子生长策略
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
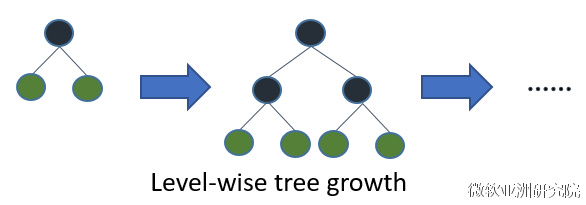
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
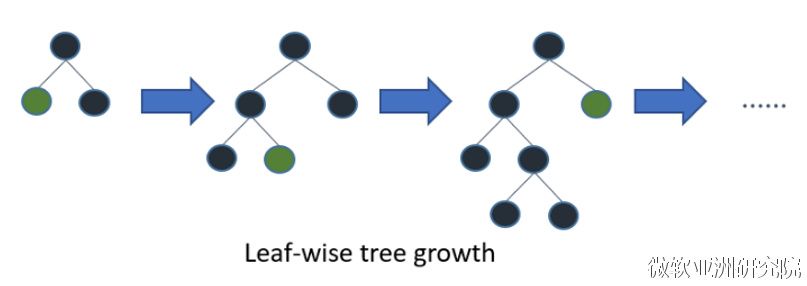
直方图差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。据我们所知,LightGBM是第一个直接支持类别特征的GBDT工具。
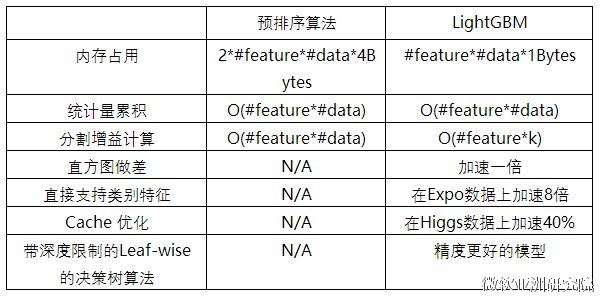
LightGBM的单机版本还有很多其他细节上的优化,比如cache访问优化,多线程优化,稀疏特征优化等等,更多的细节可以查阅Github Wiki(https://github.com/Microsoft/LightGBM/wiki)上的文档说明。优化汇总对比表:
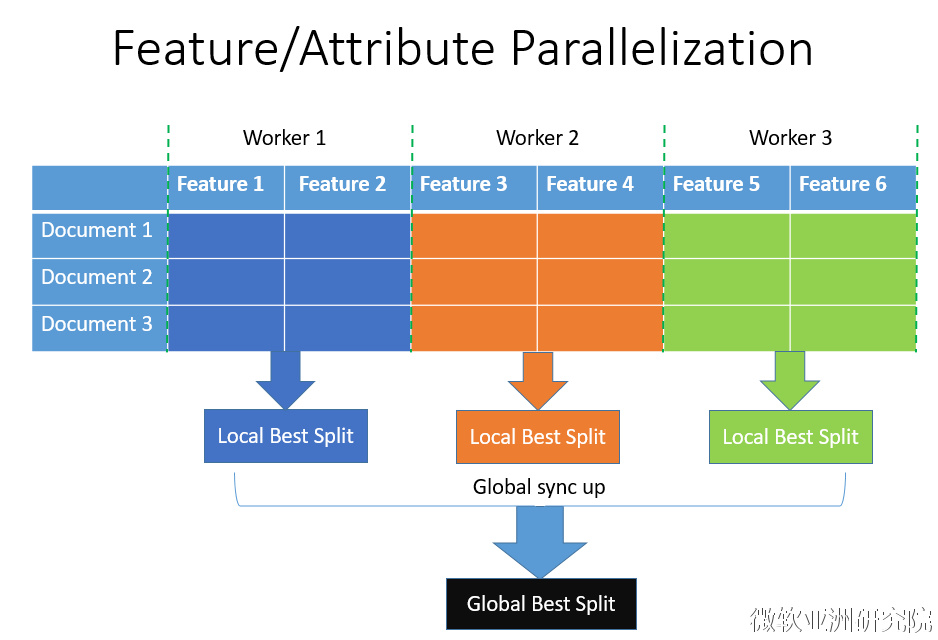
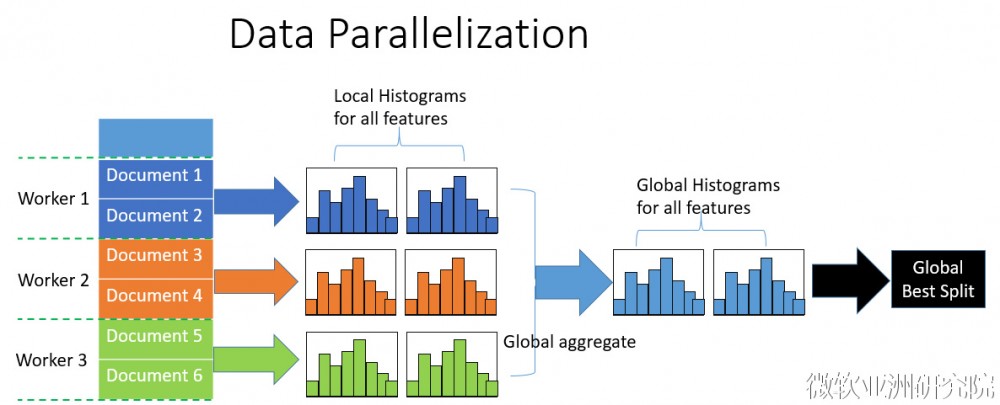
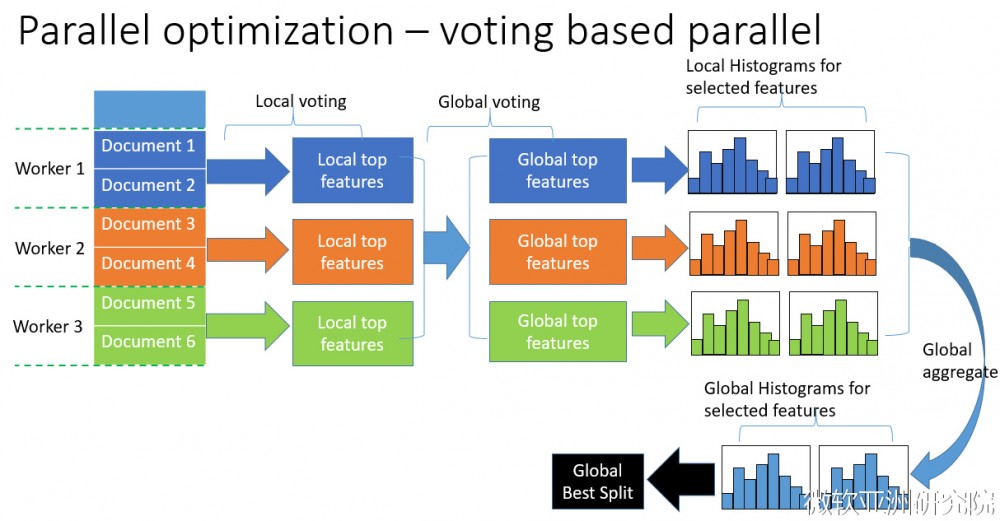
在探寻了LightGBM的优化之后,发现LightGBM还具有支持 高效并行 的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。基于投票的数据并行则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。更具体的内容可以看我们在NIPS2016的文章[1]。
LightGBM的工作还在持续进行,近期将会增加更多的新功能,如:
- R, Julia 等语言支持(目前已原生支持python,R语言正在开发中)
- 更多平台(如Hadoop和Spark)的支持
- GPU加速
此外,LightGBM开发人员呼吁大家在Github上对LightGBM贡献自己的代码和建议,一起让LightGBM变得更好。DMTK也会继续开源更多优秀的机器学习工具,敬请期待。
[1] Meng, Qi, Guolin Ke, Taifeng Wang, Wei Chen, Qiwei Ye, Zhi-Ming Ma, and Tieyan Liu. "A Communication-Efficient Parallel Algorithm for Decision Tree." In Advances In Neural Information Processing Systems, pp. 1271-1279. 2016.
看完这篇文章有没有收获很大?还想知道更多相关问题,快来下方评论区提问吧!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

