TensorFlow练习24: GANs-生成对抗网络 (生成明星脸)
GANs是Generative Adversarial Networks的简写,中文翻译为生成对抗网络,它最早出现在2014年Goodfellow发表的论文中: Generative Adversarial Networks 。GANs是目前深度学习领域最火的网络模型,苹果最近发布的第一篇论文就是关于GANs的:SimGAN。
简单来说,GANs会学着生成和训练数据相似的数据,一个最典型的应用是生成图像。假设你有一堆猫的图片,你使用这些图片训练GANs,之后它会生成和训练数据相类似的猫的图片(它习的了猫的特征)。
GANs用到机器学习的两种模型: G enerative生成模型和 D iscriminative判别模型。
GANs类比:假设 G 是大伪艺术家,以制作古董赝品为生,G的终极目标是以假乱真。但是呢,又有一些人以鉴宝为生( D )。开始你给D展示了一些古董真品,告诉D这是正品。然后G开始制作赝品,想骗过D,让他分辨不出真假。随着D看到越来越多的真品,G要骗过D就越来越难,当然,G也不是吃闲饭的,它会加倍努力的试图骗过D。随着这种对抗的持续,不仅D鉴宝的本领提高了,G也会越来越擅长制作赝品。这就是名字中生成-对抗的意思。
判别模型可以判断数据属于哪一类,例如< TensorFlow练习23: 恶作剧 >训练的CNN模型可以判断一张脸是不是我的脸。相反,生成模型不用预先知道分类,它可生成最符合训练样本分布的新样本。例如 高斯混合模型 ,经过训练,它生成的随机数据符合训练样本的分布。
GANs简单图示:
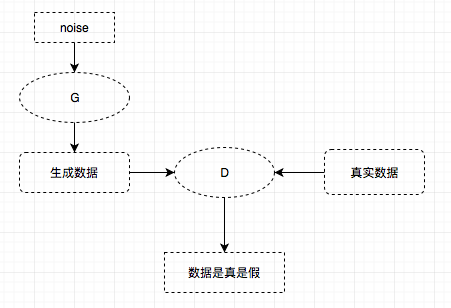
GAN相关代码实现:
- DCGN TensorFlow实现
- 根据文本描述生成图像 (反过来的: 看图说话 Show and Tell )
- 图像补全,叫你在打码
- TF-VAE-GAN-DRAW
- Auxiliary Classifier GAN
- InfoGAN时间序列数据分类
- 生成视频
- Generative Models (OpenAI)
一个TensorFlow代码示例(生成明星脸-EBGAN)
使用的数据集: Large-scale CelebFaces Attributes (CelebA) Dataset ,这个数据集包含20万明星脸,可用来做人脸检测、人脸特征识别等等任务。
下载地址: Google Drive 或 Baidu云 。
- Energy Based Generative Adversarial Networks (EBGAN)
代码:
# -*- coding: utf-8 -*-
"""
Energy Based Generative Adversarial Networks (EBGAN): https://arxiv.org/pdf/1609.03126v2.pdf
<blog.topspeedsnail.com>
由于我把Python升级到了3.6破坏了开发环境, 暂时先使用Python 2.7
"""
import os
import random
import numpyas np
import tensorflowas tf
import cv2
import scipy.miscas misc
CELEBA_DATE_DIR= 'img_align_celeba'
train_images = []
for image_filenamein os.listdir(CELEBA_DATE_DIR):
if image_filename.endswith('.jpg'):
train_images.append(os.path.join(CELEBA_DATE_DIR, image_filename))
random.shuffle(train_images)
batch_size = 64
num_batch = len(train_images) // batch_size
# 图像大小和channel
IMAGE_SIZE = 64
IMAGE_CHANNEL = 3
def get_next_batch(pointer):
image_batch = []
images = train_images[pointer*batch_size:(pointer+1)*batch_size]
for imgin images:
image = cv2.imread(img)
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE))
image = image.astype('float32') / 127.5 - 1
image_batch.append(image)
return image_batch
# noise
z_dim = 100
noise = tf.placeholder(tf.float32, [None, z_dim], name='noise')
X = tf.placeholder(tf.float32, [batch_size, IMAGE_SIZE, IMAGE_SIZE, IMAGE_CHANNEL], name='X')
# 是否在训练阶段
train_phase = tf.placeholder(tf.bool)
# http://stackoverflow.com/a/34634291/2267819
def batch_norm(x, beta, gamma, phase_train, scope='bn', decay=0.9, eps=1e-5):
with tf.variable_scope(scope):
#beta = tf.get_variable(name='beta', shape=[n_out], initializer=tf.constant_initializer(0.0), trainable=True)
#gamma = tf.get_variable(name='gamma', shape=[n_out], initializer=tf.random_normal_initializer(1.0, stddev), trainable=True)
batch_mean, batch_var = tf.nn.moments(x, [0, 1, 2], name='moments')
ema = tf.train.ExponentialMovingAverage(decay=decay)
def mean_var_with_update():
ema_apply_op = ema.apply([batch_mean, batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
mean, var = tf.cond(phase_train, mean_var_with_update, lambda: (ema.average(batch_mean), ema.average(batch_var)))
normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, eps)
return normed
# 重用变量出了点问题, 先用dict
generator_variables_dict = {
"W_1": tf.Variable(tf.truncated_normal([z_dim, 2 * IMAGE_SIZE * IMAGE_SIZE], stddev=0.02), name='Generator/W_1'),
"b_1": tf.Variable(tf.constant(0.0, shape=[2 * IMAGE_SIZE * IMAGE_SIZE]), name='Generator/b_1'),
'beta_1': tf.Variable(tf.constant(0.0, shape=[512]), name='Generator/beta_1'),
'gamma_1': tf.Variable(tf.random_normal(shape=[512], mean=1.0, stddev=0.02), name='Generator/gamma_1'),
"W_2": tf.Variable(tf.truncated_normal([5, 5, 256, 512], stddev=0.02), name='Generator/W_2'),
"b_2": tf.Variable(tf.constant(0.0, shape=[256]), name='Generator/b_2'),
'beta_2': tf.Variable(tf.constant(0.0, shape=[256]), name='Generator/beta_2'),
'gamma_2': tf.Variable(tf.random_normal(shape=[256], mean=1.0, stddev=0.02), name='Generator/gamma_2'),
"W_3": tf.Variable(tf.truncated_normal([5, 5, 128, 256], stddev=0.02), name='Generator/W_3'),
"b_3": tf.Variable(tf.constant(0.0, shape=[128]), name='Generator/b_3'),
'beta_3': tf.Variable(tf.constant(0.0, shape=[128]), name='Generator/beta_3'),
'gamma_3': tf.Variable(tf.random_normal(shape=[128], mean=1.0, stddev=0.02), name='Generator/gamma_3'),
"W_4": tf.Variable(tf.truncated_normal([5, 5, 64, 128], stddev=0.02), name='Generator/W_4'),
"b_4": tf.Variable(tf.constant(0.0, shape=[64]), name='Generator/b_4'),
'beta_4': tf.Variable(tf.constant(0.0, shape=[64]), name='Generator/beta_4'),
'gamma_4': tf.Variable(tf.random_normal(shape=[64], mean=1.0, stddev=0.02), name='Generator/gamma_4'),
"W_5": tf.Variable(tf.truncated_normal([5, 5, IMAGE_CHANNEL, 64], stddev=0.02), name='Generator/W_5'),
"b_5": tf.Variable(tf.constant(0.0, shape=[IMAGE_CHANNEL]), name='Generator/b_5')
}
# Generator
def generator(noise):
with tf.variable_scope("Generator"):
out_1 = tf.matmul(noise, generator_variables_dict["W_1"]) + generator_variables_dict['b_1']
out_1 = tf.reshape(out_1, [-1, IMAGE_SIZE//16, IMAGE_SIZE//16, 512])
out_1 = batch_norm(out_1, generator_variables_dict["beta_1"], generator_variables_dict["gamma_1"], train_phase, scope='bn_1')
out_1 = tf.nn.relu(out_1, name='relu_1')
out_2 = tf.nn.conv2d_transpose(out_1, generator_variables_dict['W_2'], output_shape=tf.pack([tf.shape(out_1)[0], IMAGE_SIZE//8, IMAGE_SIZE//8, 256]), strides=[1, 2, 2, 1], padding='SAME')
out_2 = tf.nn.bias_add(out_2, generator_variables_dict['b_2'])
out_2 = batch_norm(out_2, generator_variables_dict["beta_2"], generator_variables_dict["gamma_2"], train_phase, scope='bn_2')
out_2 = tf.nn.relu(out_2, name='relu_2')
out_3 = tf.nn.conv2d_transpose(out_2, generator_variables_dict['W_3'], output_shape=tf.pack([tf.shape(out_2)[0], IMAGE_SIZE//4, IMAGE_SIZE//4, 128]), strides=[1, 2, 2, 1], padding='SAME')
out_3 = tf.nn.bias_add(out_3, generator_variables_dict['b_3'])
out_3 = batch_norm(out_3, generator_variables_dict["beta_3"], generator_variables_dict["gamma_3"], train_phase, scope='bn_3')
out_3 = tf.nn.relu(out_3, name='relu_3')
out_4 = tf.nn.conv2d_transpose(out_3, generator_variables_dict['W_4'], output_shape=tf.pack([tf.shape(out_3)[0], IMAGE_SIZE//2, IMAGE_SIZE//2, 64]), strides=[1, 2, 2, 1], padding='SAME')
out_4 = tf.nn.bias_add(out_4, generator_variables_dict['b_4'])
out_4 = batch_norm(out_4, generator_variables_dict["beta_4"], generator_variables_dict["gamma_4"], train_phase, scope='bn_4')
out_4 = tf.nn.relu(out_4, name='relu_4')
out_5 = tf.nn.conv2d_transpose(out_4, generator_variables_dict['W_5'], output_shape=tf.pack([tf.shape(out_4)[0], IMAGE_SIZE, IMAGE_SIZE, IMAGE_CHANNEL]), strides=[1, 2, 2, 1], padding='SAME')
out_5 = tf.nn.bias_add(out_5, generator_variables_dict['b_5'])
out_5 = tf.nn.tanh(out_5, name='tanh_5')
return out_5
discriminator_variables_dict = {
"W_1": tf.Variable(tf.truncated_normal([4, 4, IMAGE_CHANNEL, 32], stddev=0.002), name='Discriminator/W_1'),
"b_1": tf.Variable(tf.constant(0.0, shape=[32]), name='Discriminator/b_1'),
'beta_1': tf.Variable(tf.constant(0.0, shape=[32]), name='Discriminator/beta_1'),
'gamma_1': tf.Variable(tf.random_normal(shape=[32], mean=1.0, stddev=0.02), name='Discriminator/gamma_1'),
"W_2": tf.Variable(tf.truncated_normal([4, 4, 32, 64], stddev=0.002), name='Discriminator/W_2'),
"b_2": tf.Variable(tf.constant(0.0, shape=[64]), name='Discriminator/b_2'),
'beta_2': tf.Variable(tf.constant(0.0, shape=[64]), name='Discriminator/beta_2'),
'gamma_2': tf.Variable(tf.random_normal(shape=[64], mean=1.0, stddev=0.02), name='Discriminator/gamma_2'),
"W_3": tf.Variable(tf.truncated_normal([4, 4, 64, 128], stddev=0.002), name='Discriminator/W_3'),
"b_3": tf.Variable(tf.constant(0.0, shape=[128]), name='Discriminator/b_3'),
'beta_3': tf.Variable(tf.constant(0.0, shape=[128]), name='Discriminator/beta_3'),
'gamma_3': tf.Variable(tf.random_normal(shape=[128], mean=1.0, stddev=0.02), name='Discriminator/gamma_3'),
"W_4": tf.Variable(tf.truncated_normal([4, 4, 64, 128], stddev=0.002), name='Discriminator/W_4'),
"b_4": tf.Variable(tf.constant(0.0, shape=[64]), name='Discriminator/b_4'),
'beta_4': tf.Variable(tf.constant(0.0, shape=[64]), name='Discriminator/beta_4'),
'gamma_4': tf.Variable(tf.random_normal(shape=[64], mean=1.0, stddev=0.02), name='Discriminator/gamma_4'),
"W_5": tf.Variable(tf.truncated_normal([4, 4, 32, 64], stddev=0.002), name='Discriminator/W_5'),
"b_5": tf.Variable(tf.constant(0.0, shape=[32]), name='Discriminator/b_5'),
'beta_5': tf.Variable(tf.constant(0.0, shape=[32]), name='Discriminator/beta_5'),
'gamma_5': tf.Variable(tf.random_normal(shape=[32], mean=1.0, stddev=0.02), name='Discriminator/gamma_5'),
"W_6": tf.Variable(tf.truncated_normal([4, 4, 3, 32], stddev=0.002), name='Discriminator/W_6'),
"b_6": tf.Variable(tf.constant(0.0, shape=[3]), name='Discriminator/b_6')
}
# Discriminator
def discriminator(input_images):
with tf.variable_scope("Discriminator"):
# Encoder
out_1 = tf.nn.conv2d(input_images, discriminator_variables_dict['W_1'], strides=[1, 2, 2, 1], padding='SAME')
out_1 = tf.nn.bias_add(out_1, discriminator_variables_dict['b_1'])
out_1 = batch_norm(out_1, discriminator_variables_dict['beta_1'], discriminator_variables_dict['gamma_1'], train_phase, scope='bn_1')
out_1 = tf.maximum(0.2 * out_1, out_1, 'leaky_relu_1')
out_2 = tf.nn.conv2d(out_1, discriminator_variables_dict['W_2'], strides=[1, 2, 2, 1], padding='SAME')
out_2 = tf.nn.bias_add(out_2, discriminator_variables_dict['b_2'])
out_2 = batch_norm(out_2, discriminator_variables_dict['beta_2'], discriminator_variables_dict['gamma_2'], train_phase, scope='bn_2')
out_2 = tf.maximum(0.2 * out_2, out_2, 'leaky_relu_2')
out_3 = tf.nn.conv2d(out_2, discriminator_variables_dict['W_3'], strides=[1, 2, 2, 1], padding='SAME')
out_3 = tf.nn.bias_add(out_3, discriminator_variables_dict['b_3'])
out_3 = batch_norm(out_3, discriminator_variables_dict['beta_3'], discriminator_variables_dict['gamma_3'], train_phase, scope='bn_3')
out_3 = tf.maximum(0.2 * out_3, out_3, 'leaky_relu_3')
encode = tf.reshape(out_3, [-1, 2*IMAGE_SIZE*IMAGE_SIZE])
# Decoder
out_3 = tf.reshape(encode, [-1, IMAGE_SIZE//8, IMAGE_SIZE//8, 128])
out_4 = tf.nn.conv2d_transpose(out_3, discriminator_variables_dict['W_4'], output_shape=tf.pack([tf.shape(out_3)[0], IMAGE_SIZE//4, IMAGE_SIZE//4, 64]), strides=[1, 2, 2, 1], padding='SAME')
out_4 = tf.nn.bias_add(out_4, discriminator_variables_dict['b_4'])
out_4 = batch_norm(out_4, discriminator_variables_dict['beta_4'], discriminator_variables_dict['gamma_4'], train_phase, scope='bn_4')
out_4 = tf.maximum(0.2 * out_4, out_4, 'leaky_relu_4')
out_5 = tf.nn.conv2d_transpose(out_4, discriminator_variables_dict['W_5'], output_shape=tf.pack([tf.shape(out_4)[0], IMAGE_SIZE//2, IMAGE_SIZE//2, 32]), strides=[1, 2, 2, 1], padding='SAME')
out_5 = tf.nn.bias_add(out_5, discriminator_variables_dict['b_5'])
out_5 = batch_norm(out_5, discriminator_variables_dict['beta_5'], discriminator_variables_dict['gamma_5'], train_phase, scope='bn_5')
out_5 = tf.maximum(0.2 * out_5, out_5, 'leaky_relu_5')
out_6 = tf.nn.conv2d_transpose(out_5, discriminator_variables_dict['W_6'], output_shape=tf.pack([tf.shape(out_5)[0], IMAGE_SIZE, IMAGE_SIZE, 3]), strides=[1, 2, 2, 1], padding='SAME')
out_6 = tf.nn.bias_add(out_6, discriminator_variables_dict['b_6'])
decoded = tf.nn.tanh(out_6, name="tanh_6")
return encode, decoded
# mean squared errors
_, real_decoded = discriminator(X)
real_loss = tf.sqrt(2 * tf.nn.l2_loss(real_decoded - X)) / batch_size
fake_image = generator(noise)
_, fake_decoded = discriminator(fake_image)
fake_loss = tf.sqrt(2 * tf.nn.l2_loss(fake_decoded - fake_image)) / batch_size
# loss
# D_loss = real_loss + tf.maximum(1 - fake_loss, 0)
margin = 20
D_loss = margin - fake_loss + real_loss
G_loss = fake_loss # no pt
def optimizer(loss, d_or_g):
optim = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.5)
#print([v.name for v in tf.trainable_variables() if v.name.startswith(d_or_g)])
var_list = [v for v in tf.trainable_variables() if v.name.startswith(d_or_g)]
gradient = optim.compute_gradients(loss, var_list=var_list)
return optim.apply_gradients(gradient)
train_op_G = optimizer(G_loss, 'Generator')
train_op_D = optimizer(D_loss, 'Discriminator')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer(), feed_dict={train_phase: True})
saver = tf.train.Saver()
# 恢复前一次训练
ckpt = tf.train.get_checkpoint_state('.')
if ckpt != None:
print(ckpt.model_checkpoint_path)
saver.restore(sess, ckpt.model_checkpoint_path)
else:
print("没找到模型")
step = 0
for i in range(40):
for j in range(num_batch):
batch_noise = np.random.uniform(-1.0, 1.0, size=[batch_size, z_dim]).astype(np.float32)
d_loss, _ = sess.run([D_loss, train_op_D], feed_dict={noise: batch_noise, X: get_next_batch(j), train_phase: True})
g_loss, _ = sess.run([G_loss, train_op_G], feed_dict={noise: batch_noise, X: get_next_batch(j), train_phase: True})
g_loss, _ = sess.run([G_loss, train_op_G], feed_dict={noise: batch_noise, X: get_next_batch(j), train_phase: True})
print(step, d_loss, g_loss)
# 保存模型并生成图像
if step % 100 == 0:
saver.save(sess, "celeba.model", global_step=step)
test_noise = np.random.uniform(-1.0, 1.0, size=(5, z_dim)).astype(np.float32)
images = sess.run(fake_image, feed_dict={noise: test_noise, train_phase: False})
for k in range(5):
image = images[k, :, :, :]
image += 1
image *= 127.5
image = np.clip(image, 0, 255).astype(np.uint8)
image = np.reshape(image, (IMAGE_SIZE, IMAGE_SIZE, -1))
misc.imsave('fake_image' + str(step) + str(k) + '.jpg', image)
step += 1


2000step就出现了人脸的雏型,接着练吧,再改改参数。
ps.昨天做梦,梦见自己变成矩阵了,太诡异了。
Share the post "TensorFlow练习24: GANs-生成对抗网络 (生成明星脸)"
- Google+
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

