Raft算法浅析
前言
在上一篇文章 ZAB协议和Paxos算法 中提到Zookeeper中的一致性协议ZAB本质上是对Paxos的简化和优化,可见Paxos的复杂性(主要是多个并发进程之间没有主次关系)以及甚至可能出现活锁问题,让具体实现起来比较复杂,下面要介绍的Raft一致性算法正是在这种环境下出现的。
Raft是斯坦福的Diego Ongaro、John Ousterhout两个人以易懂为目标设计的一致性算法,在2013年发布了论文: 《In Search of an Understandable Consensus Algorithm》 ,到现在已经有了十多种语言的Raft算法实现框架,较为出名的有etcd,Google的Kubernetes也是用了etcd作为他的服务发现框架。
Raft简介
Raft在设计的时候主要以两个目标为前提:第一点就是易懂性,在达到相同功能的前提下,首先以易懂性为标准;第二点实现实际系统的确定性,Raft追求每个技术细节的清晰界定,以此达到实现具体系统时的明确性。
为了达成以上两个目标,Raft把一致性问题分解成为三个小问题:
1.leader election:选举Leader,由Leader来负责响应客户端的请求
2.log replication:日志复制,同步
3.safety:安全性
基本概念
1.角色
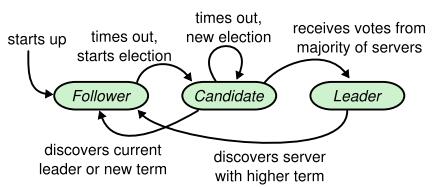
每个Server有三个状态: Leader, Follower, Candidate
Leader:集群中只有一个处于Leader状态的服务器,负责响应所有客户端的请求
Follower:刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应Candidate的请求
Candidate:Follower状态服务器准备发起新的Leader选举前需要转换到的状态,是Follower和Leader的中间状态
三者之间的转换关系,可以参考如下图所示(来源网上):
2.Term(周期)
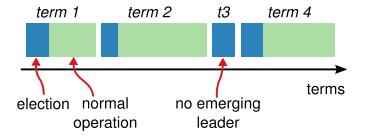
在Raft中使用了一个可以理解为周期的概念,用Term作为一个周期;Raft将整个系统执行时间划分为若干个不同时间间隔长度的Term(周期)构成的序列,以递增的数字来作为Term的编号;每个Term由Election开始,在这个时间内若干处于Candidate状态的服务器竞争产生新的Leader,这是会出现2种情况:
1.如果某个服务器成为了Leader,那在接下来的时间内将成为新的Leader
2.如果没有选举出Leader,则Term递增,开始新一任期选举
更直观的可以参考如下图所示(来源网上):
可以说每次Term的递增都将发生新一轮的选举,Raft保证一个Term内最多只有一个Leader;下面具体看看三个独立的子问题。
Raft协议步骤
1.Leader选举
当整个系统启动时,所有服务器都处于Follower状态;如果系统中存在Leader,Leader会周期性的发送心跳来告诉其他服务器它是Leader,如果Follower经过一段时间没有收到任何心跳信息,则可以认为Leader不存在,需要进行Leader选举。
在选举之前,Follower增加其Term编号并改变状态为Candidate状态,然后向集群内的其他服务器发出RequestVote RPC,这个状态持续到发生下面三个中的任意事件:
1.它赢得选举:Candidate接受了大多数服务器的投票,成为Leader,然后向其他服务器发送心跳告诉其他服务器。
2.另外有服务器获得选举:Candidate在等待的过程中接收到自称为Leader的服务器发送来的RPC消息,如果这个RPC的Term编号大于等于Candidate自身的Term编号,则Candidate承认Leader,自身状态变成Follower;否则拒绝承认Leader,状态依然为Candidate。
3.一段时间过去了,没有新的Leader产生:出现这种情况则Term递增,重新发起选举;之所以会出现这种情况,是因为有可能同时又多个Follower转为Candidate状态,导致分流,都没有获得多数票。
2.Log复制
Log复制主要作用是用于保证节点的一致性,这阶段所做的操作也是为了保证一致性与高可用性;当Leader选举出来后便开始负责客户端的请求,所有请求都必须先经过Leader处理,这些请求或说成命令也就是这里说的日志。Leader接受到客户端命令之后,将其追加到Log的尾部,然后向集群内其他服务器发出AppendEntries RPC,这引发其他服务器复制新的命令操作,当大多数服务器复制完之后,Leader将这个操作命令应用到内部状态机,并将执行结果返回给客户端。
如下图所示的Log结构图(来源网上):
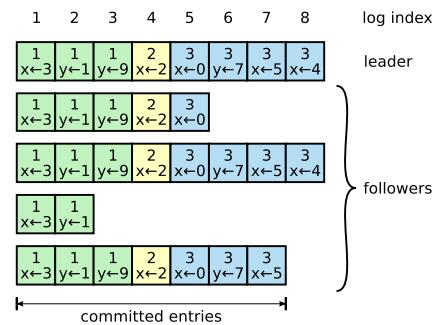
每个Log中的项目包含2个内容:操作命令本身和Term编号;还有一个全局的Log Index来指示Log项目在Log中的顺序编号。当大多数服务器在Log中存储了该项目,则可认为改项目是可以提交的,比如上图中的Log Index为7之前的项目都可以提交。
3.安全性
安全性是用来保证每个节点都执行相同序列的安全机制,如当某个Follower在当前Leader提交命令时不可用了,稍后可能该Follower又会被选举为Leader,这时新Leader可能会用新的Log覆盖先前已提交的Log,这就是导致节点执行不同序列;安全性就是用于保证选举出来的Leader一定包含先前已经提交Log的机制。
为了达到安全性,Raft增加了两个约束条件:
1.要求只有其Log包含了所有已经提交的操作命令的那些服务器才有权被选为Leader。
2.对于新Leader来说,只有它自己已经提交过当前Term的操作命令才被认为是真正的提交。
总结
Raft比起Paxos,其在可理解性以及实现系统时的明确性上一定优势,这也是Raft算法在短短几年内被广泛使用的原因;而ZAB本质上是对Paxos的简化和优化,所以Raft和ZAB还是有很多相似的地方,可以单独对两者进行对比,这个打算在以后的文章中进行比较。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

