机器学习平台 JDLP 长成记
1
背景
京东容器平台经过几年的发展,高效支撑京东全部业务系统。积累了丰富的数据中心基础设施建设,应用调度,业务系统高可用,弹性伸缩等方面的宝贵经验。更重要的是京东容器平台可以集中提供65万核CPU-Cores的计算能力。自然会全力support目前最具影响力的机器学习领域需求。以此京东商城基础平台部 集群技术团队与机器学习团队联合推出基于kubernetes研发的机器学习平台JDLP。皆在为研发团队提供具有充足CPU+GPU计算能力的统一云端机器学习平台,服务众多业务方。让机器学习计算平台资源按需随手可得。并统一提供训练任务强隔离,高可用,弹性伸缩等能力和服务,让业务更关注在算法和业务需求上。
2
声明
•训练脚本:用于进行训练的脚本,一般使用python写成。
•训练数据集:用于进行训练的数据集合。
•训练模型:训练的最终结果数据。可以根据训练模型提供如谷歌翻译等类似的服务。
•用户:使用机器学习平台进行训练的用户。
• 外部用户:使用训练模型得到如谷歌翻译之类的服务的用户。
•rs:kubernetes中的replica set。rs可以指定副本数量。kubernetes会自动监控符合条件的Pod数量,当Pod由于退出或者其他原因导致数量不足时,会自动进行重启或者重建,补齐Pod数量以提供服务。
•svc:kubernetes中的service。
pod:kubernetes中调度的基本单位。由一个或多个容器组成。在本平台的实践中,每个pod只有一个容器。因此下文中所指容器与pod为同一概念。
3
基础架构
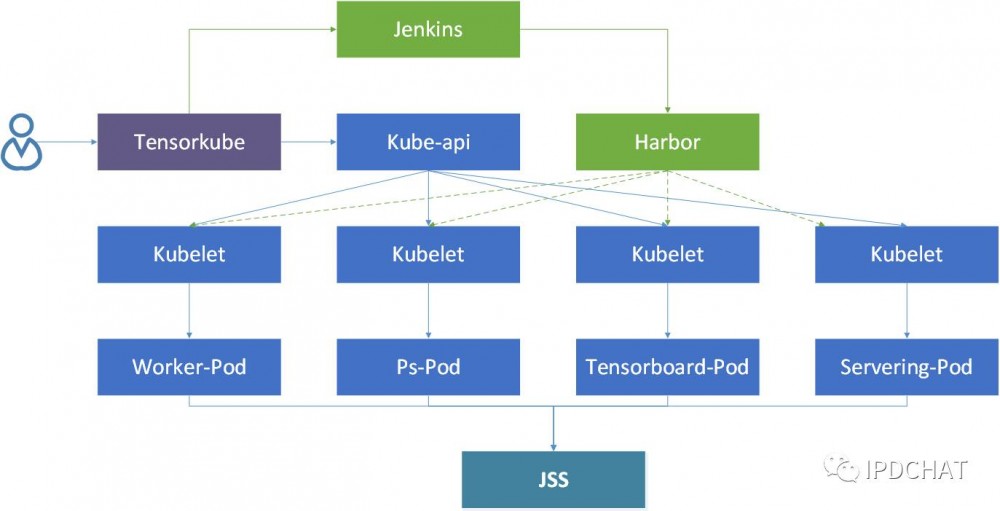
Tensorkube是京东基于tensorflow+kubernetes研发的云端机器学习平台。负责整个平台训练任务的编排、serving服务的管理等。用户通过tensorkube实现训练任务的提交、查询、删除以及serving服务的管理。
机器学习平台tensorkube立足于容器,基于kubernetes,充分利用了kubernetes的replica set的故障恢复和service的域名服务功能,结合tensorkube对于任务的编排,提供了任务从训练到提供servering服务的整套功能。
机器学习平台tensorkube主要提供了任务训练和servering两大服务。任务训练的主要目标是根据用户的训练脚本,利用GPU或CPU资源进行训练,最终生成训练模型。servering的主要服务是根据已有的训练模型,对外部用户提供实际的服务。
训练任务
训练脚本
典型的分布式训练包括ps和worker两种类型的进程。ps主要保存训练中的相关参数,而worker则是实际执行训练任务。为适应分布式的训练,对于使用的训练脚本需要进行一定的规范,一个典型的训练脚本如mnist.py所示。其中比较重要的几个启动参数包括job_name,task_index,ps_hosts,worker_hosts。
• job_name: 任务的类型,主要用以区别该进程是作为ps还是worker提供服务的。
• task_index: 任务编号。
• ps_hosts: 用于声明ps服务的多个地址。
• worker_hosts: 用于声明worker服务的多个地址。
用户提供的训练脚本需要使用该规范。tensorkube平台将利用以上参数对训练任务进行编排,以提供伸缩和故障恢复的服务保障。
训练镜像
使用Dockerfile制作训练镜像,充分利用docker容器的分层的特点,将训练脚本制作形成镜像,以便分发。一个典型的Dockerfile如下。
FROM tensorflow/tensorflow:nightly
COPY train.py /
tensorkube将用户的训练脚本和生成的Dockerfile传输给jenkins,并触发jenkins的自动构建。jenkins最终将容器镜像(假设镜像名为train01:v1)推送给镜像中心Harbor。
训练任务的编排
对于一个job,我们将Pod分为了三种类型,tensorboard、ps和worker。tensorboard主要用于在训练过程中实时查看训练的进度。一个job中只有一个tensorboard容器。ps和worker的数量可以由用户指定(最小为1)。
为提升训练效率,worker容器使用GPU资源进行训练。tensorboard、ps使用CPU资源。
worker容器默认使用GPU资源,在集群GPU资源不足时,也可由用户指定使用CPU资源进行训练。
tensorboard、ps和worker的容器均使用上一节中为该任务生成的训练容器镜像(train01:v1)。三者容器的不同之处在于启动命令不同。根据ps和worker的数量,分别为其生成启动的参数。
例如,我们设定ps 2个,worker 3个,则ps-0的启动命令设定为
/usr/bin/python /train.py --task_index=0 --job_name=ps --worker_hosts=train01-worker-0:5000,train01-worker-1:5000,train01-worker-2:5000 --ps_hosts=train01-ps-0:5000,train01-ps-1:5000
我们为tensorboard、ps和worker的每个容器分别建立了rs和service。rs将维持容器的可用性。当容器失效时,将会自动重启或重建。
以下是我们在实际集群的一个样例:
[root@A01 tensorflow]# kubectl get rs
NAME DESIRED CURRENT READY AGE
train01-ps-0 1 1 1 20d
train01-ps-1 1 1 1 20d
train01-tensorboard-0 1 1 1 20d
train01-worker-0 1 1 1 20d
train01-worker-1 1 1 1 20d
train01-worker-2 1 1 1 20d
[root@A01 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
train01-ps-0-jl1on 1/1 Running 2 20d
train01-ps-1-ef8wt 1/1 Running 2 20d
train01-tensorboard-0-kn6tu 1/1 Running 2 20d
train01-worker-0-hb2k2 1/1 Running 6 20d
train01-worker-1-lxo3u 1/1 Running 6 20d
train01-worker-2-mjm2h 1/1 Running 7 20d
[root@A01 tensorflow]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
train01-ps-0 10.254.24.48 <none> 5000/TCP 20d
train01-ps-1 10.254.212.84 <none> 5000/TCP 20d
train01-tensorboard-0 10.254.125.210 <nodes> 6006/TCP 20d
train01-worker-0 10.254.180.224 <none> 5000/TCP 20d
train01-worker-1 10.254.170.166 <none> 5000/TCP 20d
train01-worker-2 10.254.64.51 <none> 5000/TCP 20d
每个rs只控制一种类型的一个容器,且副本数为1。例如train01-ps-0的rs副本数为1,其控制的pod为train01-ps-0-jl1on。当train01-ps-0-jl1on的pod失效时,train01-ps-0的rs将会对pod重启或重建。
同时,由于每个ps和worker均建立了service,因此可以直接利用域名解析服务。因此在集群内部发向train01-worker-0:5000的请求将被最终直接定向到worker-0的容器中。
另外,worker训练过程中的训练数据结果(中间训练模型)将保存在JSS中。
当ps和worker的容器就绪后,即自动开始训练任务。
servering服务
训练任务的最终输出结果是训练模型。tensorkube将训练模型数据制作成servering镜像,用以提供servering服务。
servering服务一般是无状态服务,因此同一个任务的servering服务使用同一个servering镜像,且使用相同的命令启动。tensorkube使用rs保证servering服务容器的可用性,这一过程类似于无状态的tomcat服务,这里不再详述。
4
任务调度
Kubernetes的调器度(scheduler)作为一种插件(plugins)形式存在,是kubernetes的重要组成部分。所有的Pod创建都要经过scheduler,tensorflow中的ps和worker也不例外。
首先,GPU资源如何衡量和计算是一个颇具争议的话题。现在已经有相关技术支持多任务共享一个GPU设备的工作模式,但是仍然不够理想,对应用程序的开发有比较多的要求和限制。当前较为稳妥的做法是不允许多任务共享同一GPU设备,一个GPU一次只能分配给一个Pod而不能“切分”成若干部分进行分配,无法做到像CPU资源那样精确到小数。
从大量实际应用来看,一个Pod最多获得一个GPU设备,一个GPU设备最多只能同时分配给一个Pod,这种方案能够满足大部分应用情形,同时大大降低复杂性、应用稳定性和安全性。纵观目前的硬件发展水平,高性能的GPU的并行计算能力超过CPU一个数量级,大多数情况下给一个Pod分配一个GPU设备已经绰绰有余。而如果分配多个GPU给一个Pod,为了充分利用这些GPU资源会导致应用程序的复杂性提升。如果一个GPU设备同时分配给多个Pod,可以认为多个应用程序同时使用同一块GPU,而由于GPU本身硬件限制,一旦应用使用的总显存达到设备最大显存,就会出现OOM(Out Of Memory)错误导致程序崩溃。为了简化管理和优化资源利用,我们最终选择了一对一的折衷方案。
GPU资源的调度算法在社区中并不算成熟,我们根据实际使用过程中的经验积累,设计并开发了一系列定制调度算法。
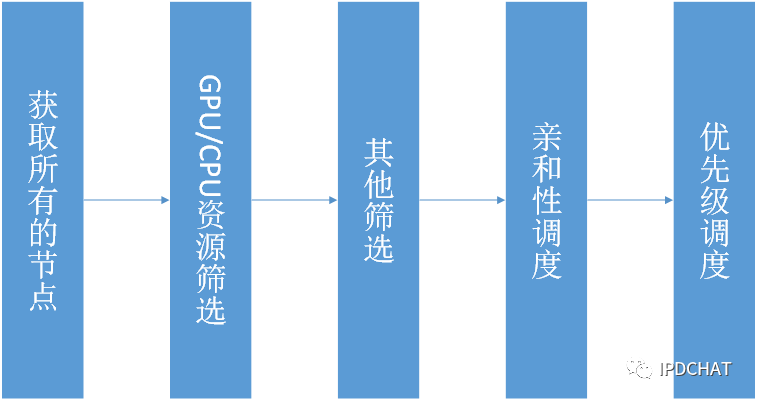
GPU/CPU资源筛选
GPU资源筛选主要根据node上GPU资源是否满足进行初步筛选过滤。每个node上的GPU设备数量是一定的,亦即可用于分配调度的数量是一定的。kubelet收集节点上的GPU总量及使用信息,并更新到kube-apiserver中,进而在etcd中持久化存储。Scheduler根据kube-apiserver中各个节点的GPU信息判断该node上可用的GPU资源是否满足Pod要求,如果满足则把node信息保存。经过筛选后,从而得到符合GPU资源的节点(node)列表。
CPU的资源筛选与此类似。当worker指定使用CPU资源进行训练,或者对tensorboard和ps进行调度时,同样先根据kube-apiserver中各个节点的CPU信息以判断该节点上可用的CPU资源满足要求。经过筛选后,从而得到符合CPU资源的节点列表。
根据node上其他条件是否满足做进一步筛选
除了满足基本的资源要求,还有一些筛选算法可以用于进一步筛选,如是否有端口冲突、指定宿主机范围、node负载大小等。
亲和性调度
利用kubernetes亲和性/反亲和性机制,可以实现灵活的ps和worker Pod调度。首先,利用node affinity可以选择具有特定标签的node,并且语法更加灵活。如规则设置为“soft”或者“preference”时,即使所有node都不满足亲和性条件也能成功调度。其次,利用inter-pod affinity可以根据node上正在运行的Pod的标签(而不是node的标签),选择是否将Pod调度到该node上。亲和性/反亲和性在Pod的annotation字段进行设置。
实际应用中,可以根据需要对ps/worker Pod的node affinity进行设置。如根据服务器综合性能高低(CPU型号/内存速度/机器新旧程度/是否SSD盘等指标),预先为所有node添加标签,将计算密集的worker Pod调度到机器性能较高的node上,因为ps Pod仅存储训练任务相关参数,不承担实际运算工作。同时,为提升ps和worker之间的数据共享效率,优先将ps Pod和worker Pod调度到相同的node上。平台通过设置inter-pod affinity来达到预期效果。
对满足要求的node计算优先级,择优选取
平台在经过以上多个筛选后,通过多种优先级算法(prioritizers),将满足要求的node进行排序。优先级算法根据不同规则和标准计算node得分,包括该Pod使用的镜像是否已经在node上、亲和性/反亲和性、均衡资源使用等。平台最终选择一个最优的节点,将调度信息发送至apiserver。
5
弹性伸缩
tensorflow训练任务的弹性伸缩一般都是对worker Pod数量进行弹性伸缩。如何实现训练任务的弹性伸缩是一个具有挑战性的问题。这里指的弹性伸缩和kubernetes自身提供的弹性伸缩(Horizontal Pod Autoscaling,HPA)有所不同。kubernetes的HPA是针对无状态服务的,而此处讨论的弹性伸缩针对的worker Pod启动时需要传入一些必要参数,如ps_hosts,worker_hosts,job_name,task_index等。我们可以认为worker是有状态服务,不能单纯使用HPA进行管理。
worker扩展
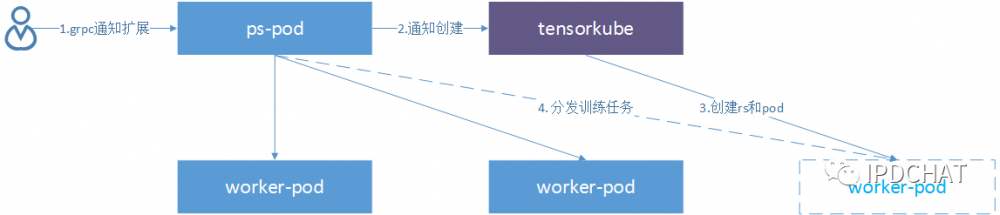
我们通过对tensorflow深入定制开发,加上和kubernetes底层机制的开发配合,较好实现了训练任务的弹性伸缩。需要扩容时,首先通过一条grpc调用通知ps服务器,增加一台或多台worker,同时将新增worker的域名和端口等参数传递给ps。ps服务器获知即将有worker加入训练集群,更新相关参数等待worker启动和加入,同时确保原训练任务不被中断。然后向tensorkube发送请求增加相应的worker。tensorkube获取worker的启动参数后调用kubernetes接口创建worker,同时更新该任务所有相关rs中的容器启动参数,以便当某个容器故障重启时使用更新后的参数进行重启或重建。worker启动后会自动接收ps分发的训练任务。值得注意的是,新加入的worker会根据当前的训练进度自动执行接下来的训练,而不是从头开始。
worker缩容
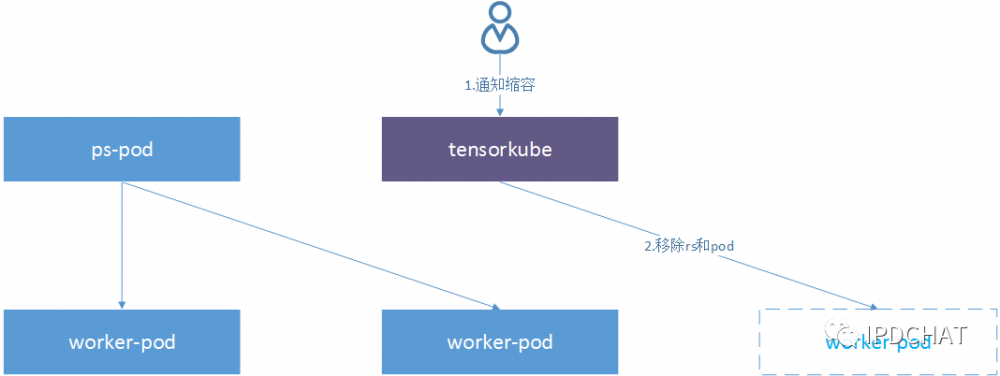
当需要缩容时,tensorkube将直接销毁对应worker的rs,ps检测到worker数量减少便会自动将任务分配到正在运行的worker上,不再向失效的worker下发任务,从而完成缩容。
6
故障与恢复
tensorkube支持任一训练任务或servering服务中任意容器的故障自动恢复。
训练任务故障
PS故障
当ps容器故障后,worker容器也会相继退出,训练将会暂时中止。而后kubernetes将监视到ps和worker容器退出,并尝试重启或者重建(如果ps/worker所在的节点不可用,将会触发重建,并调度到可用节点进行创建)ps和worker容器。ps和worker容器在启动时,从JSS上拉取之前保存的中间训练结果,并恢复训练。
worker或tensorboard故障
当worker或tensorboard故障后,不会影响当前正在进行的训练。而后kubernetes将会监视到tensorboard或worker容器退出,会尝试重启或者重建。当worker容器恢复后,将会自动加入到任务中,由ps分配训练任务以继续训练。
servering服务故障
servering是无状态服务,因此当任意一个servering的容器失效时,kubernetes将会自动维护servering服务的容器数量,进行重启或者重建。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

