自动打Tag杂记
给一段文字标记 Tag 是一个很常见的需求,比如我每篇博客下面都有对应的 Tag,不过一般说来,Tag 是数据录入者人为手动添加的,但是对大量用户产生的数据而言,我们不能指望他们能够主动添加合适的 Tag,于是乎就产生了这样的需求:自动打 Tag。
实际上这已经属于 NLP 高大上的范畴了,不是我这种非科班出身的人所能掌控的。好消息是 百度 和 腾讯 都有 NLP 平台可供选择,坏消息是免费版的 API 配额极其有限。如果不差钱的话,直接选择 NLP 平台无疑是最方便的,不过对我来说还是基于开源软件自己搭建一套吧,常见选择有 THUTag 和 Jieba ,因为 THUTag 是 Java 写的,Jieba 是 Python 写的,而我搞不定 Java,所以就选择了 Jieba。
如果要实现自动打 Tag,那么首先要实现分词,然后选择权重最大的词即可。
Jieba 是如何实现分词的呢?简单点说就是通过 trie 树扫描词典( dict.txt ),然后基于词频找到最大切分组合,作者在 issues 里举例说明了实现过程,有兴趣可以看看。更神奇的是,在这个过程中,如果存在词典中没有的词,那么 Jieba 还可以根据 HMM 模型推断出可能的新词,不过这不是我们的重点,就不多说了。
在这里,一个重要的概念是词频(P),其在 Jieba 里的计算方法如下:
python> jieba.get_FREQ(...) / jieba.dt.total
下面通过「 吴国忠臣伍子胥 」这个例子来理解一下分词过程:
python> print("/".join(jieba.cut("吴国忠臣伍子胥")))
吴国忠/臣/伍子胥
显而易见,本次 Jieba 的分词是有问题的,为什么没有分词为「吴国/忠臣」呢?理解清楚这个问题,基本就能搞清楚 Jieba 是怎么分词的了:
python> jieba.dt.total 60101967 python> jieba.get_FREQ(u"吴国忠") 14 python> jieba.get_FREQ(u"臣") 5666 python> jieba.get_FREQ(u"吴国") 174 python> jieba.get_FREQ(u"忠臣") 316
因为「P(吴国忠) * P(臣) > P(吴国) * P(忠臣)」,所以出现了错误的结果。此时我们可以通过调整相关词语的词频来解决问题,比如提升忠臣(忠臣啊!)的词频:
python> jieba.add_word("忠臣", 456)
python> print("/".join(jieba.cut("吴国忠臣伍子胥")))
吴国/忠臣/伍子胥
说明:456 是怎么来的?「14*5666/174 = 455.9」(本例可以省略 total)。
不过要实现自动打 Tag,光有分词还不够,我们还需要选择权重最大的词。Jieba 中有两种算法可供选择,它们分别是:TF-IDF 和 TextRank:
TF-IDF 指的是如果某个词在一篇文章中出现的频率高,并且在其他文章中出现频率不高,那么认为此词具有很好的类别区分能力,适合用来做关键词(当然,这个过程中要去掉通常无意义的停止词)。举例说明:现在各大门户网站的头版头条永远都是某大大的丰功伟绩,所以可以推定某大大从 TF-IDF 的角度看没有太大的价值。TextRank 则和 PageRank 基本是一个路子:临近的词语互相打分。
- TF-IDF自动提取文本关键词
- TextRank自动提取文本关键词
两种算法相比较,TF-IDF 要训练出一个 idf.txt 数据,而 TextRank 则不需要,看上去似乎 TextRank 更方便,但是从我的实际测试结果来看,对于短文本来说,如果有一个高质量的 idf 数据(比如 Jieba 缺省的),那么 TF-IDF 的效果要比 TextRank 好得多。
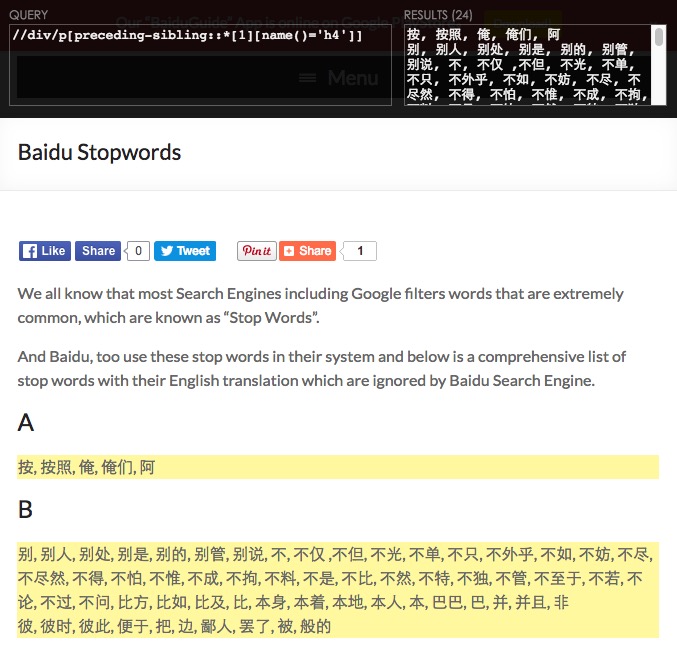
插播点题外话,在分词前的准备工作中,我们可能需要抓取很多语料数据,一个好工具能省很多事儿,推荐 requests + lxml ,以抓取 百度的停止词 为例:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from __future__ import print_function
import requests
from lxml import html
page = requests.get("http://www.baiduguide.com/baidu-stopwords/")
tree = html.fromstring(page.text)
elements = tree.xpath("//div/p[preceding-sibling::*[1][name()='h4']]/text()")
for element in elements:
words = [e.strip() for e in element.split(",") if e.strip()]
print(*words, sep="/n")
按照 xpath 来抓取数据,关键是抓取规则,推荐 chrome xpath helper :
XPath Helper
看看我的成果吧,收集了几百万条汽车维修方面的数据,然后通过 Jieba 自动给每条数据打 Tag,最后把得到的 Tag 以 Tag Cloud 的形式展示出来:

Tag Cloud
怎么样,通过 Jieba 自动的打 Tag,我们很清晰的可以看出在汽车维修领域,用户最容易遇到的问题是什么。嗯,估计有人会问这个 Tag Cloud 怎么画的, 点这里 。不谢!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

