一个爬虫:GOPA/狗爬
我以前搭建过一个 elasticsearch 资源的聚合网站,s.medcl.com,聚合了 elasticsearch 的相关资源,有文档,有 Google Group 的讨论(现在换 discuss 了),还有 PPT 等等,方便搜寻资料,因为时间太久,后面不知道死哪里去了,现在发现没有还真是很麻烦,有时候找一些资料很麻烦,要跑好几个网站去找,所以我把这个资源的搜索站重新弄起来。
然后就有了爬虫这个事情,通过爬虫来把这些资源自动收集起来,并且自动更新,然后存放到 elasticsearch 里面来,弄个界面,应该就完事了。
做过搜索的人都应该写过爬虫,我也写过,用过 Python,用过 Java,用过 .NET,各种脚本,甚至还用过 php 写过,不过 php 的只能算是的定向采集啦,目前的爬虫基本上是分为难用和很难用两种,哈哈,要么搭建很复杂,浪费80%的时间在准备的路上,另外目前大部分的爬虫,其实都是一个编程框架,有各种语言下的,提供一系列预置功能,根据需要组装,需要熟悉每个框架各种的小九九,各种领域知识,小技巧才能够愉快的跑起来,完了之后要部署了,要准备环境,浪费时间,有些要先安装几十百兆的依赖包,Python 依赖坑带来的痛苦我现在还记忆犹新,最后重用性很低,每次都是改吧改吧再改吧,总之,不是很方便吧。
恩,有这么个故事,有个程序员要修改一行代码,然后发现这个代码上下文有点问题,恩,要思考一下,可以改进一下,然后跑到另一个文件改到一半又发现这个调用的类库不是很好呀啊,然后跑过去修改那个类库,修改了一半,又发现这个是实现的语言的缺陷,不行,这个太坑了,需要优化一下,于是动手改起语言,还没改一半,又发现操作系统的 bug,要 fix 一下,恩,操作系统不熟,先翻书学习一个月,开始改,还没改完,发现底层调用,硬件的驱动写的太渣,不能忍,于是动手改,还没开始,发现硬件设计的不合理啊,没法玩,只能开始想如何优化硬件,最后得出结论,目前的计算机理论太落后,得找人说说,到处碰壁之后,觉得目前的人类不太完善,缺陷太严重,抬头看天,发现雾霾这么重,地球也不行了,哎,还是回家把那行代码的分号加上吧。
好吧,瞎扯淡完毕,想做这个爬虫很久了,上个月休了十几天年假,哪都没去,天天宅在家折腾这个,基本上有了雏形了,先说一下我的愿景吧,Gopa 目的是想以后能够很方便的进行爬取,节省时间,选用 golang 也是因为出于部署的考虑,文件小,无依赖,运行即可,这是首先的一点,其次,爬取要快速起步,使用简单,不需要编码,通过配置的方式来解决,提供 UI 来操作,然后就是支持扩展,需求不可能所有人都满足,所以提供插件机制来做,通过动态脚本来注入到gopa 中,每个流程都可以控制和扩展,最后就是支持分布式了,多个爬虫协助,最好还支持 p2p 广域网资源共享,节点之间互相帮忙,共享 ip 和带宽资源,已经爬取的资源也可以贡献,积分互换等等。
设计思路基本上参照 elasticsearch,分布式去中心,Restful API,提供 UI,动态参数等等,目的就是简单易用。
项目地址: https://github.com/medcl/gopa
下载地址: https://github.com/medcl/gopa/releases 目前提供 windows、linux 和 windows 平台下载。
GOPA 其实躺在 github 上有段时间了,是我初学 golang 的练手项目,现在其实也还是二年级学生,欢迎帮忙改进提意见,优化无止境,一直在路上,目前已经完成了基本的程序框架,基本的界面框架,提供了实时的日志查看和简单的任务管理,下面是几张截图,这下可谓是有图有真相了。
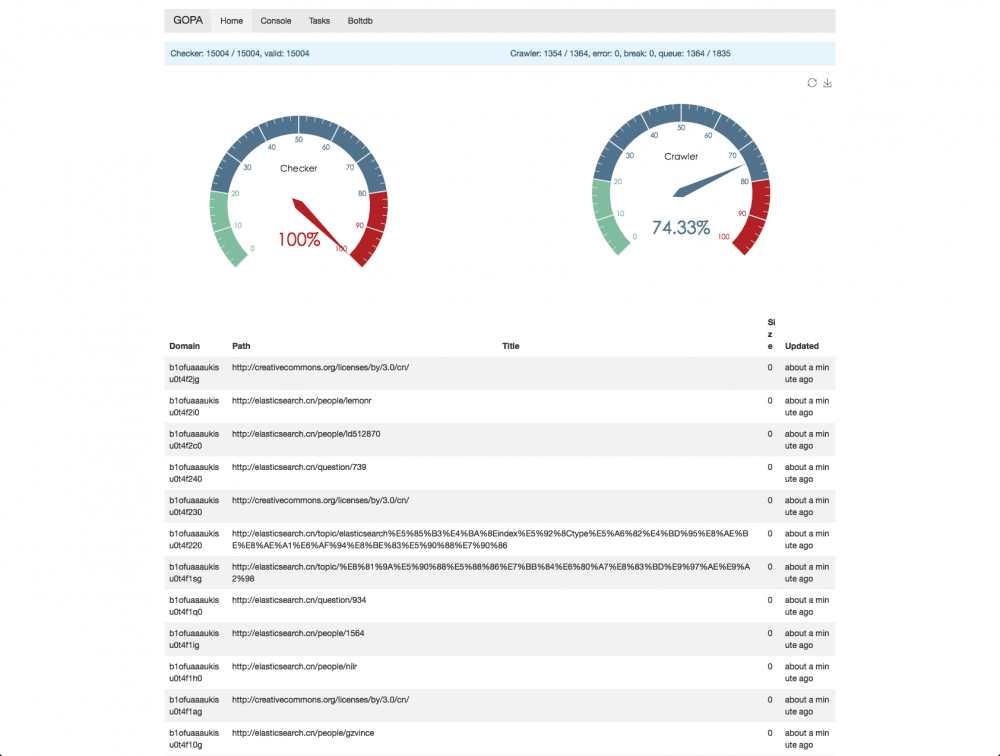
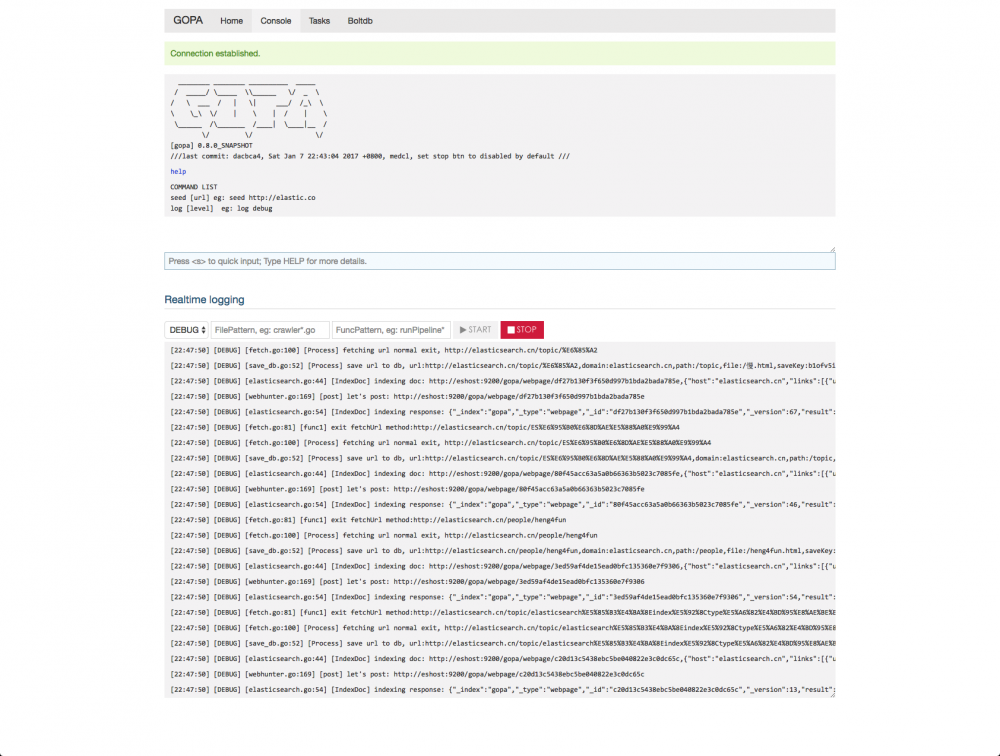
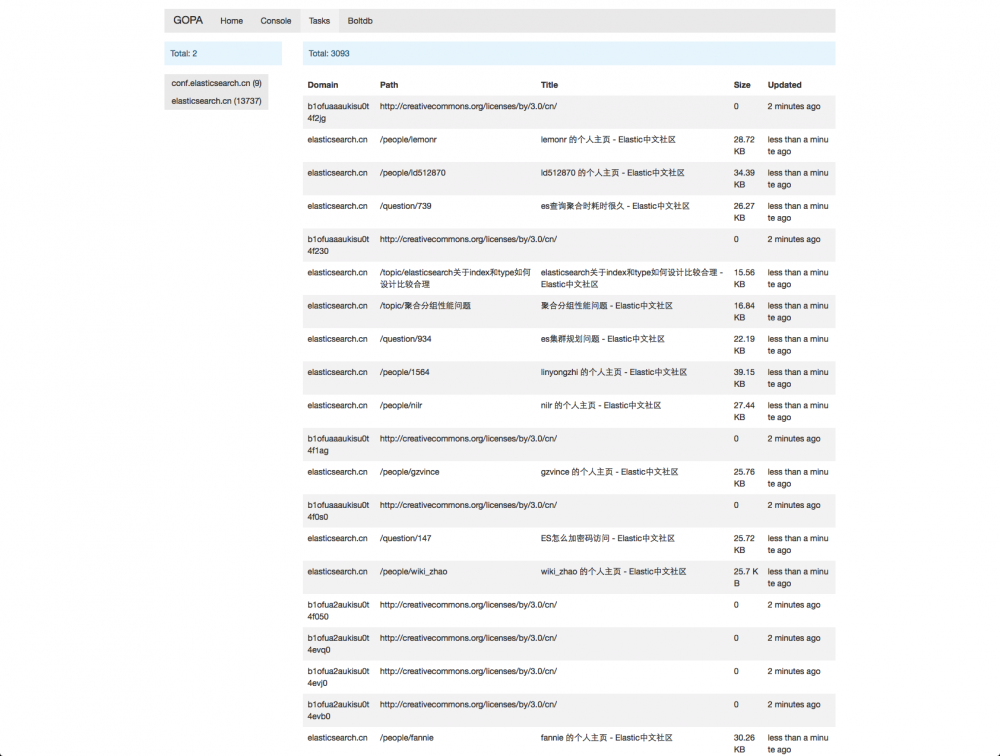
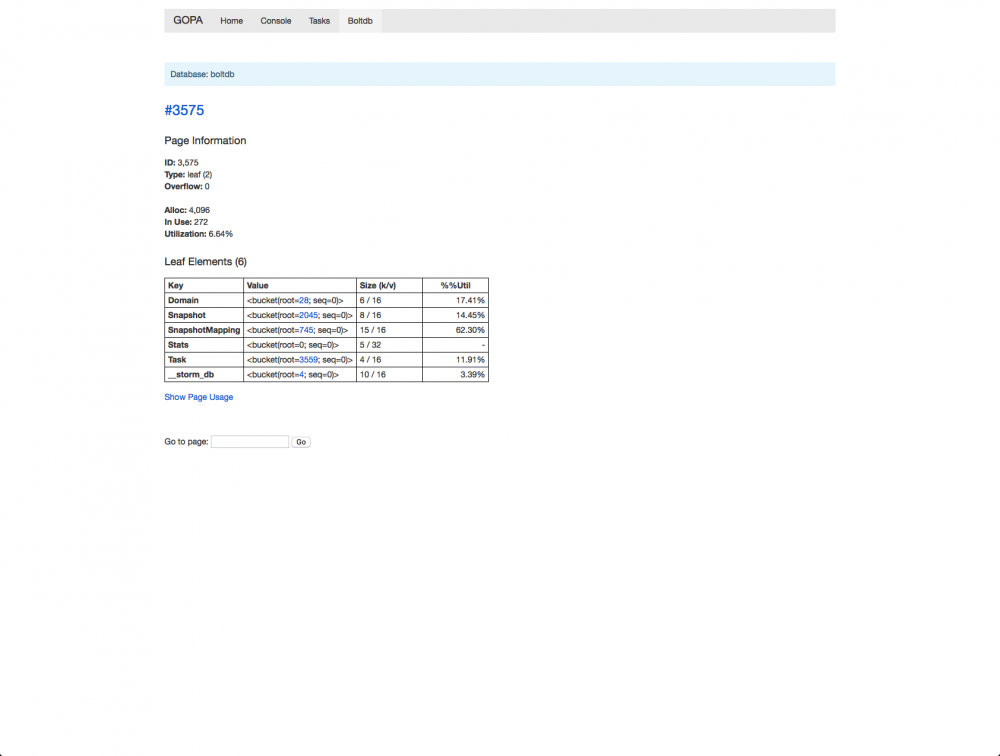
这么多字,你都看完了啊,佩服佩服。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

