Python全栈之路系列之数字数据类型
上篇文章中我们简单的体验了Python语言基本概念与语法,那么在继续深入下去的过程中,不妨先学习几个常见的Python内置数据类型?这也是大部分Python教科书的学习目录,由浅至深,慢慢深入。
Python常用的几种数据类型就是以下几种,其实Python内部的数据类型还是很多的,多归多但是很少有我们用到了,太多了也记不了,把常用的几个玩熟练了就OK了。
那么接下来我们会学到那些内置的数据类型呢?
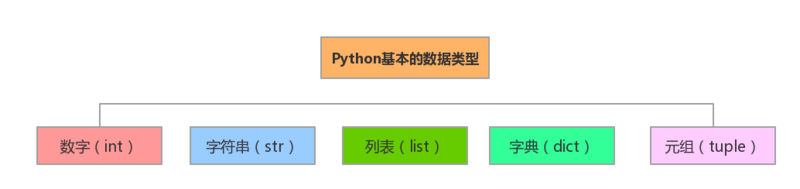
虽然说我们是在学习数据类型,但其实只是在学习每一个类型所提供的API而已,你所需要的大部分功能,Python都已经帮我们封装好了,不需要担心任何效率的问题,当你熟悉了这些API之后,灵活的组合应用,因为这在开发的过程中是必不可少的,那么接下来就让我们开始漫长的数据类型API学习之旅吧。
所有的数据类型所具备的方法都存在相对应的类里面,当创建一个类型的对象时,该对象所具备的功能都保存在相应的类中。
数字
在Python3中,整型、长整型、浮点数、负数、布尔值等都可以称之为数字类型。
创建数字类型类型的对象
int 类型通常都是数字,创建数字类型的方式有两种,且在创建的时候值两边不需要加双引号或单引号。
第一种创建整型的方式
>>> number = 9 >>> type(number) <class 'int'>
第二种创建整型的方式
>>> number = int(9) >>> type(number) <class 'int'>
以上两种创建整型对象的方式都可以创建的,但是他们也是有本质上的区别,第一种方式实际上会转换成第二种方式,然后第二种方式会把括号内的数据交给 __init__ 这个构造方法,构造方法是 int 类的,然后构造方法会在内存中开辟一块空间用来存放数据,但实际上我们在用时候是没有任何区别的。
构造方法每个数据类型中都会有,这是Python内部所定义的,如下图所示:
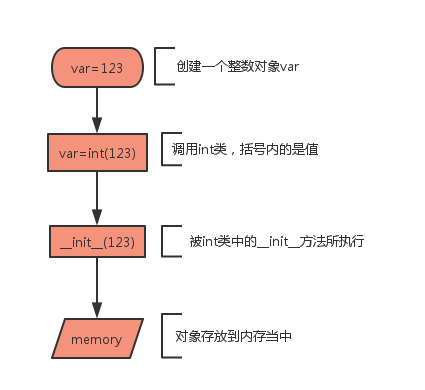
__init__
def __init__(self, x, base=10): # known special case of int.__init__
可以从源码中看到, __init__ 的方法有两个参数,其中 base=10 是可选的参数, x 是我们对象的值, base=10 其实就是说把我们的值(默认二进制)以十进制的方式输出出来,通过下面的实例可以看到:
>>> var=int('0b100',base=2)
>>> var
4
通过int()可以将一个数字的字符串变成一个整数,并且如果你指定了第二个参数,还可以将值进制数转换为整数:
# 将数字字符串转换为整数,数字字符串通过进制转换为整数
>>> int('99'),int('100',8),int('40',16),int('10000000',2)
(99, 64, 64, 128)
# 讲进制数转换为整数
>>> int('0x40',16),int('0b1000000',2)
(64, 64)
把二进制的数字4通过十进制输出出来,4的二进制就是 0b100 ,又有一个知识点就是在类的方法中,所有以 __ 开头,并且以 __ 结尾的方法都是Python内部自己去调用的,我们在写代码的过程中是不需要去调用的,最简单的例子就是 __init__ ,通过上面的流程图我们就可以很清楚的看到。
int内部优化机制
下图中我们可以很清楚的看到int类型在创建对象时内存所分配空间的情况
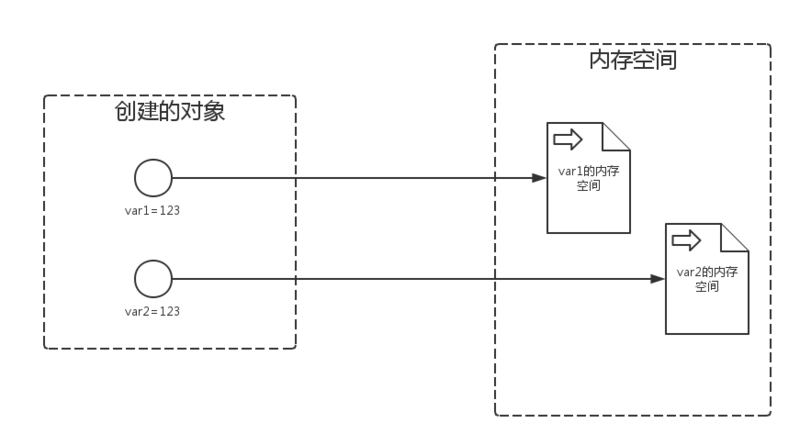
首先我们知道当我们创建第一个对象var1的时候会在内存中开辟一块空间作为存放var1对象的值用的,当我们创建第二个对象var2的时候也会在内存中开辟一块空间来作为var2对象的值,那如果这样说,那是不是说对象var1和var2的值内存是否会同时开辟两块呢?我们通过下面的实例可以得到答案:
C:/Users/anshe>c:/Python35/python.exe # 注意我是用的是Python3.5.1 Python 3.5.1 (v3.5.1:37a07cee5969, Dec 6 2016, 01:54:25) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. # 分别创建对象var1和var2 >>> var1=123 >>> var2=123 # 我们可以看到他们的内存地址都是指向的`1502084720` >>> id(var1) 1502084720 >>> id(var2) 1502084720
通过上面的结果我们可以看到var1和var2的内存地址是相同的,就代表他们的值是使用的同一块空间,那么如果我把var2的值改为456呢?
>>> var2=456 >>> id(var1) 1502084720 >>> id(var2) 2452305956816
可以看到var2的内存地址已经改变了(废话),因为对象的值不一样了,所以他才不会改变,OK,我们可以得到一个结论就是:当两个或者多个对象的值都是同一个的时候,那么这些对象都会使用同一个内存地址,这里的值是是有范围的,默认范围是 -5~257 ,得到这个结论之后我们继续往下看。
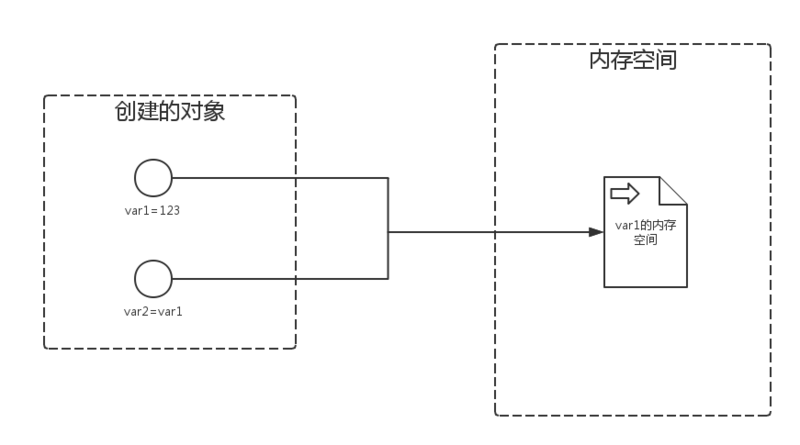
这张图我们同样创建了两个对象,但是唯一不同的是我把第一个创建的对象的值作为第二个对象的值,这里他们肯定使用的是同一个内存地址,但是如果我把第一个对象的值改动了呢?
>>> var1=123 >>> var2=var1 >>> id(var1) 1502084720 >>> id(var2) 1502084720 >>> var1=456 >>> id(var1) 2452305956816 >>> id(var2) 1502084720
请自行思考,这里不多做解释,然后下面我们再来说说刚才的话题,说在 -5~257 这个范围内对象的值都会引用同一块内存地址,我们可以通过下面的实验来测试:
>>> var1=12345 >>> var2=12345 >>> id(var1) 2452305956816 >>> id(var2) 2452308384720
事实证明我们的结论是完全没有问题的,注意我上面的实例都是在 Python3.5 上面执行的哦, var1 和 var2 两个对象的值同样是12345,但是他们的内存地址就是不一样,这就是Python在内部做的优化,他把 -5~257 这个范围内我们常用道德数字多对象可引用的,OK,到此结束这个话题。
数字类型的长度限制
数字类型在 python2.7 里面是分整型和长整型这个区别的,也就是说如果你的数字大到一定的范围,那么python会把它转换为长整形,一个数字类型包含32位,可以存储从 -2147483648 到 214483647 的整数。
一个 长整(long) 型会占用更多的空间,64位的可以存储 -922372036854775808 到 922372036854775808 的整数。
python3里long型已经不存在了,而int型可以存储到任意大小的整型,甚至超过64为。
Python内部对整数的处理分为普通整数和长整数,普通整数长度为机器位长,通常都是32位,超过这个范围的整数就自动当长整数处理,而长整数的范围几乎完全没限制,如下:
-
Python2.7.x
>>> var=123456 >>> var 123456 >>> var=10**20 >>> var 100000000000000000000L >>> type(var) # long就是长整型 <type 'long'>
-
Python3.5.x
>>> var=123456789 >>> var 123456789 >>> var=10**20 >>> var 100000000000000000000 >>> type(var) <class 'int'>
请自行补脑 - - 、
数字类型所具备的方法
bit_length
返回表示该数字时占用的最少位数
>>> num=20 >>> num.bit_length() 5
conjugate
返回该复数的共轭复数,复数,比如0+2j,其中num.real,num.imag分别返回其实部和虚部,num.conjugate(),返回其共扼复数对象
>>> num =-20 >>> num.conjugate() -20 >>> num=0+2j >>> num.real 0.0 >>> num.imag 2.0 >>> num.conjugate() -2j
imag
返回复数的虚数
>>> number = 10 >>> number.imag 0 >>> number = 3.1415926 >>> number.imag 0.0
内置的方法还有 denominator 、 from_bytes 、 numerator 、 real 、 to_bytes ,实在搞不懂这有什么用,也不太理解,就不做介绍了,你可以通过 help(int.numerator) 查看该方法的帮助信息等。
混合类型
所谓混合类型就是浮点数和整数进行运算,如下所示:
>>> 3.14159 + 10 13.14159
结果和我们想象中的一样,但是一个浮点数一个正整数它是怎么进行相加的呢?其实很简单,Python会把两个值转换为其中最复杂的那个对象的类型,然后再对相同类型运算。
比如上面的例子中,会先把 10 转换为 10.0 然后再与 3.14159 相加。
数字类型的复杂度
整数比浮点数简单、浮点数比复数简单。
布尔类型(bool)
布尔类型其实就是数字0和1的变种而来,即 真(True/0) 或 假(False/1) ,实际上就是内置的数字类型的子类而已。
# 如果0不是真,那么就输出'0 is False.'
>>> if not 0: print('0 is False.')
...
0 is False.
# 如果1是真,那么就输出'1 is True.'
>>> if 1: print('1 is True.')
...
1 is True.
你还可以使用布尔值进行加减法,虽然从来没在任何代码中见过这种形式:
>>> True + 1 # 1 + 1 = 2 2 >>> False + 1 # 0 + 1 = 1 1
集合(set)
集合的元素是不允许重复、不可变且无序的集合,集合就像是字典舍弃了值一样,集合中的元素只能够出现一切且不能重复。
创建set集合
>>> s = set([11,22,33])
>>> s
{33, 11, 22}
>>> type(s)
<class 'set'>
第二种不常用创建set集合的方式
# 这种的创建方式,集合中的元素相当于字典中的key
>>> s = {11,22,33}
>>> type(s)
<class 'set'>
>>> s
{33, 11, 22}
把其它可迭代的数据类型转换为set集合
>>> li = ["a","b","c"]
>>> seting = set(li)
>>> seting
{'b', 'a', 'c'}
>>> type(seting)
<class 'set'>
集合同样支持表达式操作符
# 首先创建两个集合
>>> x = set('abcde')
>>> y = set('bdxyz')
>>> x
{'a', 'd', 'b', 'c', 'e'}
>>> y
{'y', 'd', 'b', 'x', 'z'}
# 使用in进行成员检测
>>> 'a' in x
True
# 差集
>>> x - y
{'a', 'e', 'c'}
# 并集
>>> x | y
{'b', 'y', 'z', 'a', 'd', 'e', 'c', 'x'}
# 交集
>>> x & y
{'d', 'b'}
# 对称差
>>> x ^ y
{'y', 'z', 'a', 'e', 'c', 'x'}
# 比较
>>> x > y, x < y
(False, False)
集合解析
>>> {x for x in 'abc'}
{'a', 'b', 'c'}
>>> {x+'b' for x in 'abc'}
{'bb', 'cb', 'ab'}
集合所提供的方法
add
往集合内添加元素
>>> se = { 11, 22, 33 }
>>> se
{33, 11, 22}
# 元素写在小括号内
>>> se.add(44)
>>> se
{33, 11, 44, 22}
clear
清除集合内容
>>> se = { 11, 22, 33 }
>>> se
{33, 11, 22}
>>> se.clear()
>>> se
set()
copy浅拷贝
下文介绍
difference
寻找集合的元素var1中存在,var2中不存在的
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22 ,55 }
>>> var1.difference(var2)
{33, 11}
>>> var2.difference(var1)
{55}
difference_update
寻找集合的元素var1中存在,var2中不存在的元素,并把查找出来的元素重新复制给var1
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22 ,55 }
>>> var1.difference_update(var2)
>>> var1
{33, 11}
discard
移除指定元素,不存在不保错
>>> var1 = { 11, 22, 33 }
>>> var1.discard(11)
>>> var1
{33, 22}
>>> var1.discard(1123123)
>>> var1
{33, 22}
remove
移除指定元素,不存在保错
>>> var1 = { 11, 22, 33 }
>>> var1
{33, 11, 22}
>>> var1.remove(11)
>>> var1
{33, 22}
>>> var1.remove(asda)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'asda' is not defined
intersection
交集,查找元素中都存在的值
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22, 55, "一二" }
>>> var1.intersection(var2)
{22}
intersection_update
取交集并更更新到A中
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22, 55, "一二" }
>>> var1.intersection_update(var2)
>>> var1
{22}
isdisjoint
判断有没有交集,如果有返回False,否则返回True
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22, 44, 55 }
>>> var1.isdisjoint(var2)
False
>>> var2 = { 66, 44, 55 }
>>> var1.isdisjoint(var2)
True
issubset
是否是子序列,也就是说如果var2的所有元素都被var1所包含了,那么var2就是var1的子序列
>>> var1 = {11,22,33,44}
>>> var2 = {11,22}
>>> var2.issubset(var1)
True
issuperset
是否是父序列
>>> var1 = { 11, 22, 33 }
>>> var2 = { 22, 44, 55 }
>>> var1.issuperset(var2)
True
pop
移除一个元素,并显示移除的元素,移除时是无序的
>>> var1 = {11,22,33,44}
>>> var1.pop()
33
>>> var1
{11, 44, 22}
symmetric_difference
对称交集,把var1存在且b不存在和var2存在且var1不存在的元素合在一起
>>> var1 = { 11, 22, 33, 44 }
>>> var2 = { 11, 22, 77, 55 }
>>> var1.symmetric_difference(var2)
{33, 44, 77, 55}
symmetric_difference_update
对称交集,并更新到var1中
>>> var1 = { 11, 22, 33, 44 }
>>> var2 = { 11, 22, 77, 55 }
>>> var1
{33, 11, 44, 22}
>>> var1.symmetric_difference_update(var2)
>>> var1
{33, 44, 77, 55}
union
并集,把两个集合中的所有元素放在一起,如果有重复的则只存放一个
>>> var1 = { 11, 22, 33, 44 }
>>> var2 = { 11, 22, 77, 55 }
>>> var1.union(var2)
{33, 11, 44, 77, 22, 55}
update
更新,把一个集合中的元素更新到另一个集合中
>>> var1 = { 11, 22, 33, 44 }
>>> var2 = { 11, 22, 77, 55 }
>>> var1.update(var2)
>>> var1
{33, 11, 44, 77, 22, 55}
原文链接
Python全栈之路系列文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

