“蜜汁”算法:AlphaGo升级成Master后的算法框架分析
2016年12月29日至2017年1月4日,谷歌AlphaGo的升级版本以Master为名,在弈城围棋网和野狐围棋网的快棋比赛中对人类最高水平的选手取得了60:0的压倒战绩,再次让人们对围棋AI的实力感到震惊。
之前《自然》论文对AlphaGo的算法进行了非常细致的介绍,世界各地不少研发团队根据这个论文进行了围棋AI的开发。其中进展最大的应该是腾讯开发的“刑天”(以及之前的版本“绝艺”),职业棋手和棋迷们感觉它的实力达到了2016年3月与李世石对战的AlphaGo版本。但是经过近一年的升级,Master的实力显然比之前版本要强得多,它背后的算法演变成什么样了,却几乎没有资料。本文对AlphaGo的升级后的算法框架进行深入的分析与猜测,试图从计算机算法角度揭开它的神秘面纱一角。

在1月4日AlphaGo团队的正式声明中,Deepmind提到了“our new prototype version(我们新的原型版本)”。prototype这个词在软件工程领域一般对应一个新的算法框架,并不是简单的性能升级,可能是算法原理级的改变。由于资料极少,我只能根据很少的一些信息,以及Master的实战表现对此进行分析与猜测。
下文中,我们将2015年10月战胜樊麾二段的AlphaGo版本称为V13,将2016年3月战胜李世石的版本称为V18,将升级后在网络上60:0战胜人类高手群体的版本称为V25(这个版本Deepmind内部应该有不同的称呼)。
V13与V25:从廖化到关羽
版本V13的战绩是,正式的慢棋5:0胜樊麾,棋谱公布了,非正式的快棋3:2胜樊麾,棋谱未公布。樊麾非正式快棋胜了两局,这说明版本V13的快棋实力并不是太强。
版本V18的战绩是,每方2小时3次1分钟读秒的慢棋,以4:1胜李世石。比赛中AlphaGo以非常稳定的1分钟1步的节奏下棋。比赛用的分布式机器有1202个CPU和176个GPU,据说每下一局光电费就要3000美元。
版本V25的战绩是,Master以60:0战胜30多位人类棋手,包括排名前20位的所有棋手。比赛大部分是3次30秒读秒的快棋,开始10多局人们关注不多时是20秒读秒用时更短,仅有一次60秒读秒是照顾年过六旬的聂卫平。比赛中Master每步几乎都在8秒以内落子,从未用掉过读秒(除了一次意外掉线),所以20秒或者30秒对机器是一回事。在KGS上天元开局三局虐杀ZEN的GodMoves很可能也是版本V25,这三局也是快棋,GodMoves每步都是几秒,用时只有ZEN的一半。
可以看出,版本V13的快棋实力不强。而版本V18的快棋实力应该也不如慢棋,谷歌为了确保胜利,用了分布式的版本而非48个CPU与8个GPU的单机版,还用了每步1分钟这种在AI中算多的每步用时。在比赛中,有时AlphaGo的剩余用时甚至比李世石少了。应该说这时的AlphaGo版本有堆机器提升棋力的感觉,和IBM在1997年与卡斯帕罗夫的国际象棋人机大战时的做法类似。
但是版本V25在比赛用时上进步很大,每步8秒比版本V18快了六七倍,而棋力却提升很大。柯洁与朴廷桓在30秒用时的比赛中能多次战胜与版本V18实力相当的刑天,同样的用时对Master几盘中却毫无机会。应该说版本V25在用时大大减少的同时还取得了棋力巨大的进步,这是双重的进步,一定是因为算法原理有了突破,绝对不是靠提升机器性能。而这与国际像棋AI的进步过程有些类似。
IBM在人机大战中战胜卡斯帕罗夫后解散了团队不玩了,但其它研究者继续开发国际象棋AI取得了巨大的进步。后来算法越做越厉害,最厉害的程序能让人类最高水平的棋手一个兵或者两先。水平极高的国际象棋AI不少,其中一个是鳕鱼(stockfish),由许多开发者集体开发,攻杀凌厉,受到爱好者追捧。
另一个是变色龙(Komodo),由一个国际象棋大师和一个程序员开发,理论体系严谨,攻防稳健。AI互相对局比人类多得多,二者对下100盘,变色龙以9胜89平2负领先人气高的鳕鱼。因为AI在平常的手机上都可以战胜人类最高水平的棋手,国际象棋(以及类似的中国象棋)都禁止棋手使用手机,曾经有棋手频繁上厕所看手机被抓禁赛。国际象棋AI在棋力以及计算性能上都取得了巨大的进步,运算平台从特别造的大型服务器移到了人人都有的手机上。
局面评估函数的作用
从算法上来说,高水平国际象棋AI的关键是人工植入的一些国际象棋相关的领域知识,加上传统的计算机搜索高效剪枝算法。值得注意的是,AlphaGo以及之前所有高水平AI如ZEN和CrazyStone都采用MCTS(蒙特卡洛树形搜索),而最高水平的国际象棋AI是不用的。MCTS是CrazyStone的作者法国人Remi Coulom 在2006年最先提出的,是上一次围棋人工智能算法取得巨大进步能够战胜一般业余棋手的关键技术突破。
但MCTS其实是传统搜索技术没有办法解决围棋问题时,想出来的变通办法,并不是说它比传统搜索技术更先进。实际MCTS随机模拟,并不是太严谨,它是成千上万次模拟,每次模拟都下至终局数子确定胜负统计各种选择的胜率。这是一个对人类棋手来说相当不自然的方法,可以预期人类绝对不会用这种办法去下棋。
国际象棋也可以用MCTS去做,但没有必要。谷歌团队有人用深度学习和MCTS做了国际象棋程序,但是棋力仅仅是国际大师,并没有特别厉害。高水平国际象棋算法的核心技术,是极为精细的“局面评估函数”。而这早在几十年前,就是人工智能博弈算法的核心问题。国际象棋的局面评估函数很好理解,基本想法是对皇后、车、马、象、兵根据战斗力大小给出不同的分值,对王给出一个超级大的分值死了就是最差的局面。一个局面就是棋子的分值和。
但这只是最原始的想法,子力的搭配、兵阵的形状、棋子的位置更为关键,象棋中的弃子攻杀极为常见。这需要国际象棋专业人士进行极为专业细致的估值调整。国际象棋AI的水平高低基本由它的局面评估函数决定。有了好用的局面评估函数以后,再以此为基础,展开一个你一步我一步的指数扩展的博弈搜索树。在这个搜索树上,利用每个局面计算出来的分值,进行一些专业的高效率“剪枝”(如Alpha-Beta剪枝算法)操作,缩小树的规模,用有限的计算资源尽可能地搜索更多的棋步,又不发生漏算。
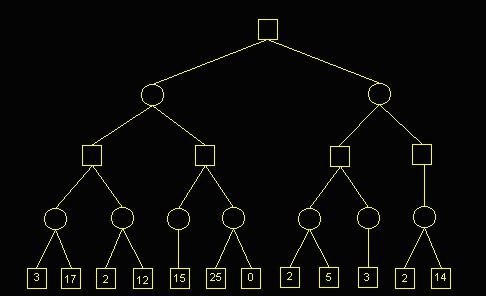
图为搜索树示例,方块和圆圈是两个对手,每一条线代表下出一招。局面评估后,棋手要遵守MIN-MAX的原则,要“诚实”地认为对手能下出最强应对再去想自己的招。有局面评估分数的叶子节点其实不用都搜索到,因为理论上有剪枝算法证明不用搜索了。如一下被人吃掉一个大子,又得不到补偿的分枝就不用继续往下推了。这些搜索技术发展到很复杂了,但都属于传统的搜索技术,是人可以信服的逻辑。
国际象棋与中国象棋AI发展到水平很高后,棋手们真的感觉到了电脑的深不可测,就是有时电脑会下出人类难于理解的“AI棋”。人类对手互相下,出了招以后,人就会想对手这是想干什么,水平相当的对手仔细思考后总是能发现对手的战术意图,如设个套双吃对手的马和车,如果对手防着了,就能吃个兵。
而“AI棋”的特征是,它背后并不是一条或者少数几条战术意图,而是有一个庞大的搜索树支持,人类对手作出任何应对,它都能在几手、十几手后占得优势,整个战略并不能用几句话解释清楚,可能需要写一篇几千字的文章。
这种“AI棋”要思考非常周密深远,人类选手很难下出来。近年来中国象棋成绩最好的是王天一,他的棋艺特点就是主动用软件进行训练,和上一辈高手方法不同。王天一下出来的招有时就象AI,以致于有些高手风言风语影射他用软件作弊引发风波,我认为应该是训练方法不同导致的。国际象棋界对软件的重视与应用比中国象棋界要强得多,重大比赛时,一堆人用软件分析双方的着手好坏,直接作为判据,增加了比赛的可看性。
软件能下出“AI棋”,是因为经过硬件以及算法的持续提升,程序的搜索能力终于突破了人类的脑力限制,经过高效剪枝后,几千万次搜索可以连续推理多步并覆盖各个分枝,在深度与广度方面都超过人类,可以说搜索能力已经超过人类。
其实最初的围棋AI也是用这个思路开发的,也是建立搜索树,在叶子节点上搞局面评估函数计算。但是围棋的评估函数特别难搞,初级的程序一般用黑白子对周边空点的“控制力”之类的原始逻辑进行估值,差错特别大,估值极为离谱,棋力极低。无论怎么人工加调整,也搞不好,各种棋形实在是太复杂。很长时间围棋AI没有实质进步,受限于评估函数极差的能力,搜索能力极差。
实在是没有办法了,才搞出MCTS这种非自然的随机下至终局统计胜率的办法。MCTS部分解决了估值精确性问题,因为下到终局数子是准确的,只要模拟的次数足够多,有理论证明可以逼近最优解。用这种变通的办法绕开了局面评估这个博弈搜索的核心问题。以此为基础,以ZEN为代表的几个程序,在根据棋形走子选点上下了苦功,终于取得了棋力突破,能够战胜一般业余棋手。
接下来自然的发展就是用深度学习对人类高手的选点直觉建模,就是“策略网络”。这次突破引入了机器学习技术,不需要开发者辛苦写代码了,高水平围棋AI的开发变容易了。即使这样,由于评估函数没有取得突破,仍然需要MCTS来进行胜率统计,棋力仍然受限,只相当于业余高手。
“价值网络”横空出世
AlphaGo在局面评估函数上作出了尝试性的创新,用深度学习技术开发出了“价值网络”。它的特点是,局面评分也是胜率,而不是领先多少目这种较为自然的优势计算。但是从《自然》论文以及版本V13与V18的表现来看,这时的价值网络并不是太准确,不能单独使用,应该是一个经常出错的函数。论文中提到,叶子节点胜率评估是把价值网络和MCTS下至终局混合使用,各占0.5权重。这个意思是说,AlphaGo会象国际象棋搜索算法一样,展开一个叶子节点很多的树。
在叶子节点上,用价值网络算出一个胜率,再从叶子节点开始黑白双方一直轮流走子终局得出胜负。两者都要参考,0.5是一个经验性的数据,这样棋力最高。这其实是一个权宜之计,价值网络会出错,模拟走子终局也并不可靠,通过混合想互相弥补一下,但并不能解决太多问题。最终棋力还是需要靠MCTS海量模拟试错,模拟到新的关键分枝提升棋力。所以版本V18特别需要海量计算,每步需要的时间相对长,需要的CPU与GPU个数也不少,谷歌甚至开发了特别的TPU进行深度神经网络并行计算提高计算速度。
整个《自然》论文给人的感觉是,AlphaGo在围棋AI的工程实施的各个环节都精益求精做到最好,最后的棋力并不能简单地归因于一两个技术突破。算法研发与软件工程硬件开发多个环节都不计成本地投入,需要一个人数不小的精英团队全力支持,也需要大公司的财力与硬件支持。V13与V18更多给人的感觉是工程成就,之前的围棋AI开发者基本是两三个人的小团队小成本开发,提出了各式各样的算法思想,AlphaGo来了个集大成,终于取得了棋力突破。
即使这样,V18在实战中也表现出了明显缺陷,输给李世石一局,也出了一些局部计算错误。如果与国际象棋AI的表现对比,对人并不能说有优势,而是各有所长。人类高手熟悉这类围棋AI的特点后,胜率会上升,正如对腾讯AI刑天与绝艺的表现。
ZEN、刑天、AlphaGo版本V18共同的特点是大局观很好。连ZEN的大局观都超过一些不太注意大局的职业棋手,但是战斗力不足。这是MCTS海量模拟至终局精确数目带来的优势,对于地块的价值估计比人要准。它们共同的弱点也是局部战斗中会出问题,死活搞不清,棋力高的问题少点。这虽然出乎职业棋手的预料,从算法角度看是自然的。海量终局模拟能体现虚虚的大局观,但是这类围棋AI的“搜索能力”仍然是不足的,局面评估函数水平不高,搜索能力就不足,或者看似搜得深但有漏洞。正是因为搜索能力不足,才需要用MCTS来主打。
但是AlphaGo的价值网络是一个非常重要而且有巨大潜力的技术。它的革命性在于,用机器学习的办法去解决局面评估函数问题,避免了开发者自己去写难度极大甚至是不可能写出来的高水平围棋局面评估函数。国际象棋开发者可以把评估思想写进代码里,围棋是不可能的,过去的经验已经证明了这一点。机器学习的优点是,把人类说不清楚的复杂逻辑放在多达几百M的多层神经网络系数里,通过海量的大数据把这些系数训练出来。
给定一个围棋局面,谁占优是有确定答案的,高手也能讲出一些道理,有内在的逻辑。这是一个标准的人工智能监督学习问题,它的难度在于,由于深度神经网络结构复杂系数极多,需要的训练样本数量极大,而高水平围棋对局的数据更加难于获取。Deepmind是通过机器自我对局,积累了2000万局高质量对局作为训练样本,这个投入是海量的,如果机器数量不多可能要几百年时间,短期生成这么多棋局动用的服务器多达十几万台。但如果真的有了这个条件,那么研究就是开放的,怎么准备海量样本,如何构建价值网络的多层神经网络,如何训练提升评估质量,可以去想办法。
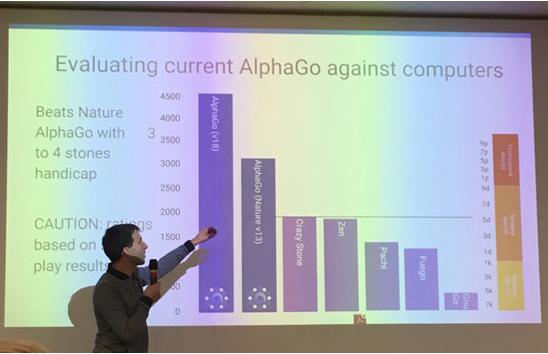
AlphaGo团队算法负责人David Silver在2016年中的一次学术报告会上说,团队又取得了巨大进步,新版本可以让V18四个子了,主要是价值网络取得了巨大进步。这是非常重要的信息。
V25能让V18四个子,如果V18相当于人类最高水平的棋手,这是不可想象的。根据Master对人类60局棋来看,让四子是绝对不可能的,让二子人类高手们都有信心。我猜测,V18是和V25下快棋才四个子还输的。AlphaGo的训练与评估流水线中,机器自我对局是下快棋,每步5秒这样。2016年9月还公布了三局自我对局棋谱,就是这样下出来的。V18的快棋能力差,V25在价值网络取得巨大进步能力后,搜索能力上升极大,只要几秒的时间,搜索质量就足够了。为什么价值网络的巨大进步带来的好处这么大?
如果有了一个比V18要靠谱得多的价值网络,就等于初步解决了局面评估函数问题。这样,AlphaGo新的prototype就更接近于传统的以局面评估为核心的搜索框架,带有确定性质的搜索就成为算法能力的主要力量,碰运气的MCTS不用主打了。因此,V25对人类高手的实战表现,可以与高水平国际象棋AI相当了。
我可以肯定V25的搜索框架会给价值网络一个很高的权重(如0.9),只给走子至终局数子很低的权重。如果局面平稳双方展开圈地运动,那么各局面的价值网络分值差不多,MCTS模拟至终局的大局观会起作用。如果发生局部战斗,那么价值网络就会起到主导作用,对战斗分枝的多个选择,价值网络都迅速给出明快的判断,通过较为完整的搜索展开,象国际象棋AI一样论证出人类棋手看不懂的“AI棋”。
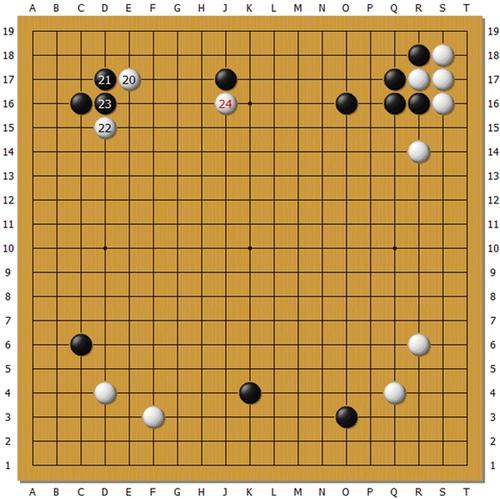
上图为Master执白对陈耀烨。在黑子力占优的左上方,白20挂入,黑21尖顶夺白根据地意图整体攻击,白22飞灵活转身是常型,23团准备切断白,这时Master忽然在24位靠黑一子。Master比起之前的版本V18,感觉行棋要积极一些,对人类棋手的考验也更多。可以想见这里黑内扳外扳两边长脱先各种应法很多,并不是很容易判断。
但是如果有价值网络对各个结果进行准确估值,Master可能在下24的时候就已经给出了结论,黑无论如何应,白棋都局势不错。陈耀烨自战解说认为,24这招他已经应不好了,实战只好委屈地先稳住阵脚,复盘也没有给出好的应对。同样的招法Master对朴廷桓也下过。
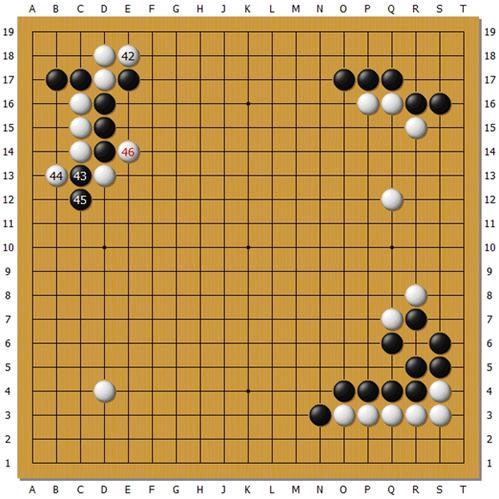
上图为Master执白对芈昱廷,左上角的大雪崩外拐定式,白下出新手。白44职业棋手都是走在E13长的,后续变化很复杂。但是Master却先44打一下,下了让所有人都感到震惊的46扳,在这个古老的定式下出了从未见过的新手。这个新手让芈昱廷短时间内应错了,吃了大亏。后来芈昱廷自战回顾时说应该可以比实战下得好些,黑棋能够厚实很多,但也难说占优。但是对白46这招还没有完全接受。这个局面很复杂,有多个要点,Master的搜索中是完全没有定式的概念的。
我猜测它会各种手段都试下,由于价值网络比过去精确了,可以建立一个比较庞大的搜索树,然后象国际象棋AI一样多个局面都考虑过之后综合出这个新手。这次Master表现得不怕复杂变化,而之前版本感觉上是进行大局掌控,复杂变化算不清绕开去。Master却经常主动挑起复杂变化,明显感觉搜索能力有进步,算路要深了。
局面评估函数精确到一定程度突破了临界点,就可以带来搜索能力的巨大进步。因为开发者可以放心地利用局面评估函数进行高效率的剪枝,节省出来的计算能力可以用于更深的推导,表现出来就是算得深算得广。实际人类的剪枝能力是非常强大的,计算速度太慢,如果还要去思考一些明显不行的分枝,根本没办法进行细致的推理。在一个局面人类的推理,其实就是一堆变化图,众多高手可能就取得一致意见了。而Master以及国际象棋AI也是走这个路线了,它们能摆多得多的变化图,足以覆盖人类考虑到的那些变化图给出靠谱的结论。
但这个路线的必须依靠足够精确的价值网络,否则会受到多种干扰。一是估值错了,好局面扔掉坏局面留着选错棋招。二是剪枝不敢做,搜索大量无意义的局面,有意义的局面没时间做或者深度不足。三是要在叶子节点引入快速走子下完的“验证”,这种验证未必靠谱,价值网络正确的估值反而给带歪了。
从实战表现反推,Master的价值网络质量肯定已经突破了临界点,带来了极大的好处,思考时间大幅减少,搜索深度广度增加,战斗力上升。AlphaGo团队新的prototype,架构上可能更简单了,需要的CPU数目也减少了,更接近国际象棋的搜索框架,而不是以MCTS为基础的复杂框架。比起国际象棋AI复杂的人工精心编写的局面评估函数,AlphaGo的价值网络完全由机器学习生成,编码任务更为简单。
理论上来说,如果价值网络的估值足够精确,可以将叶子节点价值网络的权重上升为1.0,就等于在搜索框架中完全去除了MCTS模块,和传统搜索算法完全一样了。这时的围棋AI将从理论上完全战胜人,因为人能做的机器都能做,而且还做得更好更快。而围棋AI的发展过程可以简略为两个阶段。第一阶段局面估值函数能力极弱,被逼引入MCTS以及它的天生弱点。第二阶段价值网络取得突破,再次将MCTS从搜索框架逐渐去除返朴归真,回归传统搜索算法。
由于价值网络是一个机器学习出来的黑箱子,人类很难理解里面是什么,它的能力会到什么程度不好说。这样训练肯定会碰到瓶颈,再也没法提升了,但版本V18那时显然没到瓶颈,之后继续取得了巨大进步。通常机器学习是模仿人的能力,如人脸识别、语音识别的能力超过人。但是围棋局面评估可以说是对人与机器来说都非常困难的任务。
职业棋手们的常识是,直线计算或者计算更周密是可以努力解决的有客观标准的问题,但是局面判断是最难的,说不太清楚,棋手们的意见并不统一。由于人的局面评估能力并不太高,Master的价值网络在几千万对局巧妙训练后超过人类是可以想象的,也带来了棋力与用时表现的巨大进步。但是可以合理推测,AlphaGo团队也不太可能训练无缺陷的价值网络,不太可能训练出国际象棋AI那种几乎完美的局面评估函数。
我的猜测是,Master现在是一个“自信”的棋手,并不象之前版本那样对搜索没信心靠海量模拟至终局验算。它充分相信自己的价值网络,以此为基础短时间内展开庞大的搜索树,下出信心十足算路深远的“AI棋”,对人类棋手主动挑起战斗。这个姿态它是有了。但是它这个“自信”并不是真理,它只是坚定地这样判断了。肯定有一些局面它的评估有误差,如围棋之神说是白胜的,Master认为是黑胜。人类棋手需要找到它的推理背后的错误,与之进行判断的较量,不能被它吓倒。
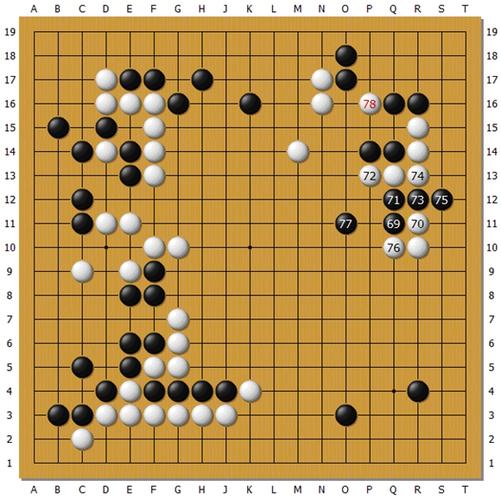
上图是Master执黑对孟泰龄。本局下得较早,Master虽然连胜但没有战胜太多强手,孟泰龄之前有战胜绝艺的经验,心理较为稳定并不怕它,本局发挥不错。Master黑69点入,71、73、75将白棋分为两段发起凶猛的攻击。但是孟泰龄下出78位靠的好手,局部结果如下图。

黑棋右边中间分断白棋的四子已经被吃,白棋厚势与左下势力形成呼应,右上还有R17断吃角部一子的大官子。黑棋只吃掉了白棋上边两子,这两子本就处于受攻状态白并不想要。这个结果无论如何应该是白棋获利,Master发生了误算,或者局面评估失误。
现在职业棋手与AlphaGo团队的棋艺竞争态势可能是这样的。AlphaGo不再靠MCTS主导搜索改而以价值网络主打,思考时间大大缩短,在10秒以内就达到了极高棋力,之后时间再长棋力增长也并不多。棋力主要是由价值网络的质量决定的,堆积服务器增加搜索时间对搜索深度广度意义并不太大。所以Master已经较充分的展示了实力,并不是说还有棋力强大很多的版本。这和国际象棋AI类似,两个高水平AI短时间就能大战100局,并不需要人类那么长的思考时间。
Master的60局快棋击中了人类棋艺的弱点,它极为自信地主动发起挑战敢于导入复杂局面,而人类高手却没有能力在30秒内完善应对这些不太熟悉的新手。而这些新手并不是简单的新型,背后有Master的价值网络支持的庞大搜索树。如果价值网络的这些估值是准确的,人类高手即使完美应对,也只能是不吃亏,犯错就会被占便宜。有些局面下,价值网络的估计会有误差,这时人类高手有惩罚Master的机会,但需要充足的时间思考,也要有足够的自信与Master的判断进行较量。这次60局中棋手由于用时太短心态失衡很少做到,一般还是会吃亏。
以下是我对柯洁与AlphaGo的人机大战的建议:
1. 要对机器有足够了解,不要盲目猜测。可以简单的理解,它接近一个以价值网络为基础的传统搜索程序。
2. 要相信机器并不完美。如果它的局面评估函数没有错误了,或者远远超过人,那就和国际象棋AI一样不可战胜了。但围棋足够复杂,即使是几千万局的深度学习,也不可能训练出特别好的价值网络,一定会有漏洞与误差。只是因为人的局面评估也不是太好,才显得机器很厉害。
3. 这次机器会坚定而自信地出手,它改变了风格,在局面仍然胶着的时候不会回避复杂变化。因为它的搜索深度广度增加了,它认为自己算清了,坚定出手维护自己的判断,甚至会主动扑劫造劫。
4. 机器的退让是在胜定的情况下,它认为反正是100%获胜了,就随机选了一手。后半盘出现这种情况不用太费劲去思考了,应该保留体力迅速下完,下一局再战斗。
5. 机器的大局观仍然会很好,基于多次模拟数空,对于虚空的估计从原理上就比人强,这方面人要顶住但不能指望靠此获胜。还是应该在复杂局部中与机器进行战斗,利用机器价值网络的估值失误,以人对局面估计的自信与机器的自信进行比拼。机器是自信的,人类也必须自信。也许机器评估正确的概率更大,但是既然都不完美,人类也可能在一些局面判断更为正确。
6. 机器对稍复杂战斗局面的评估是有庞大搜索树支持的,并不会发生简单的漏算,不应该指望找到简单的手段给机器毁灭性打击。由于人类的思考速度慢,时间有限,不能进行太全面的思考。应该集中思考自己判断不错的局面,围绕它进行论证。如果这个判断正好是人类正确、机器错误,那人是有机会占优的。
通过以上分析,我对人机大战柯洁胜出一局甚至更多局还是抱有一定期望的。希望柯洁能够总结分析围棋AI的技术特点,增加自信,针锋相对采取正确的战略,捍卫人类的围棋价值观。
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

