ILSVRC2016目标检测任务回顾:图像目标检测(DET)
雷锋网 (公众号:雷锋网) 注:本文作者李瑜,中科院计算所前瞻研究实验室跨媒体组硕博士生,硕士导师唐胜副研究员,博士导师李锦涛研究员。2016年,作为360+MCG-ICT-CAS_DET团队核心主力参加了ImageNet大规模视觉识别挑战赛(ILSVRC)的 DET任务并获得第四名。目标检测相关工作受邀在ECCV 2016 ImageNet和COCO视觉识别挑战赛联合工作组会议上做大会报告。

计算机视觉领域权威评测——ImageNet大规模图像识别挑战赛(Large Scale Visual Recognition Challenge)自2010年开始举办以来,一直备受关注。2016年,在该比赛的图像目标检测任务中,国内队伍大放异彩,包揽该任务前五名(如图1所示)。我们将根据前五名参赛队伍提交的摘要与公开发表的论文或技术文档,简析比赛中用到的图像目标检测方法。
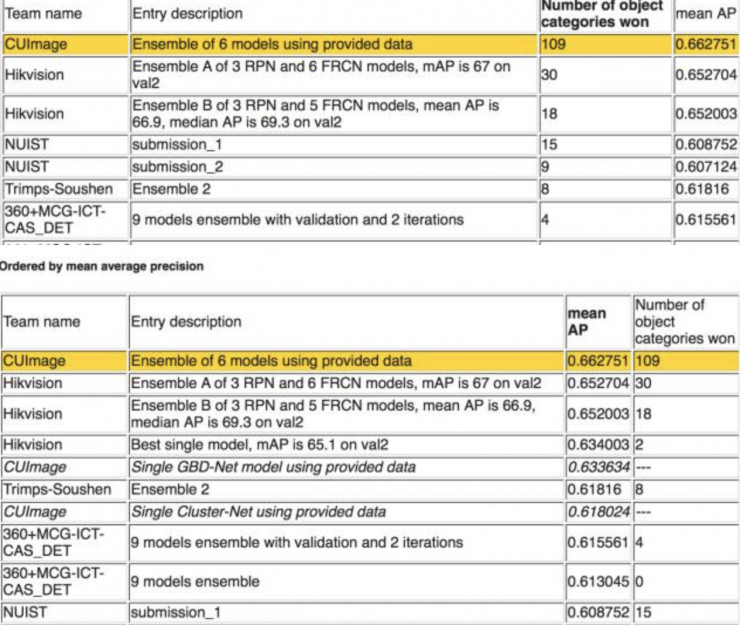
图1. ILSVRC2016目标检测(无额外数据)任务比赛结果
总体上说,参赛队伍大多采用ResNet/Inception网络+Faster R-CNN框架,注重网络的预训练,改进RPN,并利用Context信息,测试时结合普遍被使用的多尺度测试、水平翻转、窗口投票等方法,最终融合多个模型得到结果。
下面我们将细数参赛方法中的诸多亮点。
一、利用Context信息
1、GBD-Net
GBD-Net(Gated Bi-Directional CNN)是CUImage团队的成果,也是今年DET任务中的一大亮点。该方法利用双向门控的CNN网络在不同尺度的上下文窗口中选择性地传递信息,以此对context建模。
GBD-Net的研究动机源于对context信息在候选窗口分类过程中起到的作用的仔细分析。首先,Context信息在对窗口分类时能起到关键的作用,如图2(a)(b)所示,图中的红框必须结合Context信息才能准确判断其类别(包括判断为背景)。所以很多时候,我们可以利用context信息作出如图1(c)所示的判断。但是如图1(d)所示,并不是所有的context信息都能给我们正确的指导,所以context信息需要选择性的利用。
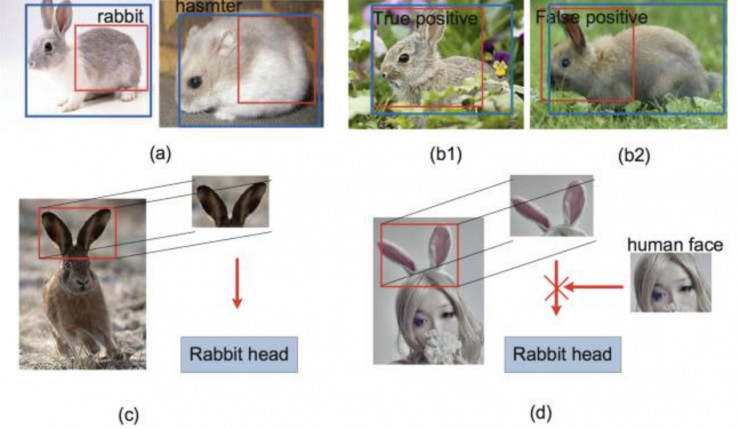
图2. GBD-Net的研究动机
基于这一点,CUImage提出了GBD-Net。如图3所示,GBD-Net采集Context信息的方式与[2][3]一脉相承,直接在目标窗口基础上放大窗口以获得更多的context信息,或缩小窗口以保留更多的目标细节,以此得到多个support region,双向连接的网络让不同尺度和分辨率的信息在每个support region之间相互传递,从而综合学习到最优的特征。然而如研究动机中所说,并非所有的上下文信息都能给决策带来“正能量”,所以在双向互通的连接上都加了一个“门”,以此控制context信息的相互传播。GBD-Net在ImageNet DET数据集上,在ResNet-269为基础网络,带来了2.2%的mAP提升。
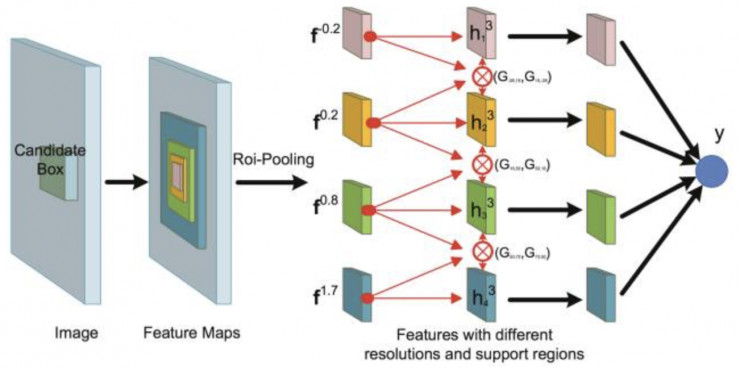
图3. GBD-Net框架图
2、Dilation as context
360+MCG-ICG-CAS_DET团队将用膨胀卷积获取context信息的方法迁移至目标检测任务,将8个膨胀卷积层削减到3层,在ROI pooling前就组织好每个像素点对应的context信息,如图4,省去了对每个ROI反复提取context特征的操作。该方法在VOC07数据集上,以Res50为基础网络,能获得1.5%的提升。

图4. Dilation as context方法示意图
3、Global context
2015年提出利用ROI pooling对全图进行pooling获取context信息的方法,Hikvision团队在此基础上进一步细化,提出了图5(a)所示的global context方法,在ILSVRC DET验证集上获得了3.8%的mAP性能提升。该方法此前的文章中有详细描述,此处不再赘述。
除了基于ROI pooling的global context方法,CUImage沿用[6]中提到的global context方法,为每个ROI加入全局的分类结果信息,如图5(b)示。该方法在GBD-net局部context的基础上又加入了全局的context信息,进一步将mAP提高了1.3%。
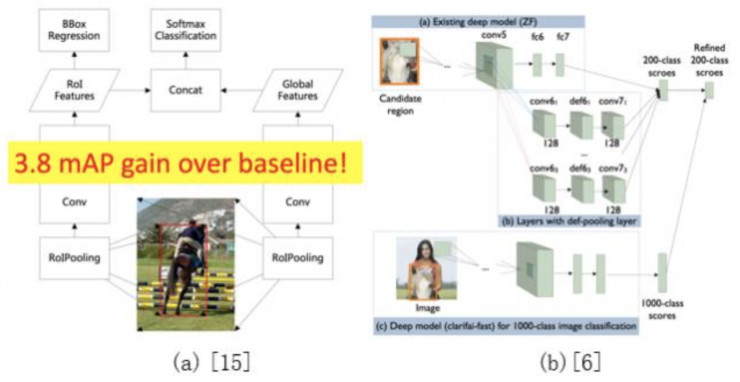
图5. Global context方法示意图
二、改进分类损失
360+MCG-ICG-CAS_DET团队提出了两种改进的softmax损失: 将背景类分成若干隐式子类别(Implicit sub-categories for background)、必要时加入sink类别(Sink class when neCESsary) 。
Faster R-CNN中将所有与Ground Truth的IOU大于0.5的窗口当做正样本,IOU介于0.1~0.4之间的当做背景类别样本,所以虽然正常目标类别的样本之间有较大的相似性,但背景类别的样本之间差异却非常大,在这种情况下,仍然同等对待目标类别和背景类别对背景类别来说是不公平的。所以背景隐式子类别方法将背景类别分为若干个子类别,想让更多的参数去描述多变的背景,在softmax之前重新将所有子类别聚合为一个背景类,以避免显式定义各个子类别的问题(如图6(a)所示)。
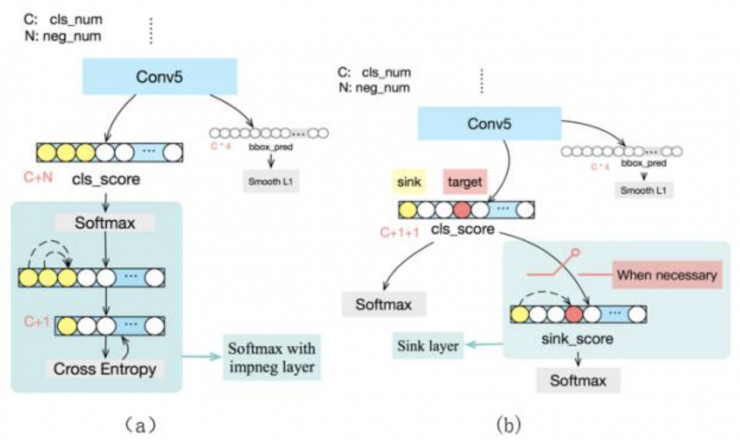
图6 改进分类损失
另外,由于训练数据本身的一些冲突性(比如同样的图像内容在不同场景下会同时成为正样本和负样本,或不同类别的样本之间非常相似),对于某些窗口,ground truth类别的得分始终不是很高,而其他一些错误类别的得分会超过ground truth类别。所以sink方法加入一个sink类,在ground truth得分不在Top-K时,同时优化sink类别和ground truth类别,否则正常优化ground truth类别。以此将那些错误类别上的得分引流到sink类别上,使得在对窗口分类时,即使ground truth类别得分不是特别高,仍然可以高于其他类别,如图6(b)所示。
三、改进RPN
CUImage和Hikvision都提出改进RPN,并且两者的改进策略都源于CRAFT(如图7所示),在RPN之后再连接一个二分类的Fast R-CNN,进一步减少窗口数量并提高定位精度。
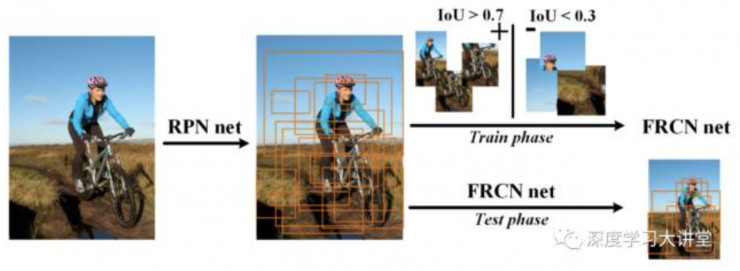
图7 CRAFT
CUImage进一步将CRAFT升级为CRAFT-v3,训练过程加入随机crop,测试中采取多尺度策略,并且平衡正负样本比例,用2个模型进行融合,将ILSVRC DET val2上的recall@300 proposal提升到95.3%。
Hikvision则是直接按照box refinement的思想,直接在RPN网络基础上进行一次级联,如图8所示。同时他们注意到,Faster R-CNN在理想情况下希望PRN的正负样本比是1:1,而实际运行中,正样本数量往往较少,使得正负样本比差异较大,所以将正负样本比强制限制在不超过1:1.5后,recall提升3%。
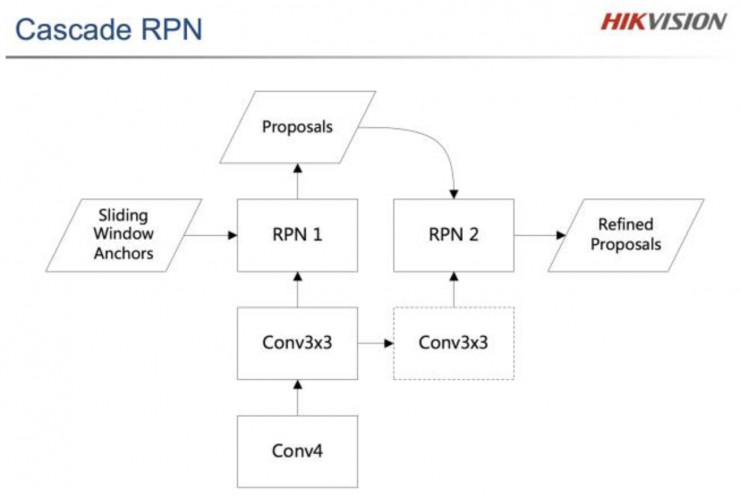
图8 级联的RPN
四、网络选择与训练技巧
自ILSVRC2015后,ResNet和后续的Inception v4,Identity mapping由于其强大的分类性能,被广泛使用到目标检测、场景分割等应用中。不同的网络通常能收敛到不同的极值点,这种网络差异性是模型融合获得较大提升的关键。CUImage、Hikvision、Trimps Soushen、360+MCG-ICT-CAS_DET、NUIST都用不同的基础网络训练了多个模型用于融合。
在训练目标检测模型之前,具有针对性的模型预训练通常可以使得最后训练的目标检测模型能收敛到更优的位置。Hikvision提到在初始化global context的分支时使用预训练的模型效果远远好于随机初始化。另外,他们用ILSVRC LOC的数据首先在1000个类别上预训练一个精细分类的目标检测模型,再迁移到DET数据上训练200类的模型。CUImage同样提到模型预训练的重要性。他们在1000类Image-centric方式训练分类网络后,又采取基于ROI-Pooling的Object-centric方式训练分类网络,预训练网络使最终目标检测模型的mAP提升约1%。
此外,Hikvision提出在训练过程中强制平衡正负样本比会产生积极的影响。OHEM、多尺度训练等技巧都是简单有效的提高mAP的方式。
五、测试技巧
测试过程中可采用的技巧很多,会对最终目标检测结果起到锦上添花的作用。多尺度测试、水平翻转、窗口微调与多窗口投票、多模型融合、NMS阈值调整、多模型融合等方法被广泛使用,并经过普遍验证证明了其有效性。
Trimps Soushen、360+MCG-ICT-CAS_DET采用了Feature Maxout的方法融入多尺度测试,尽量让每个窗口都缩放到接近224x224的尺度上进行测试,充分利用预训练网络的性能。窗口微调与多窗口投票(box refinement and box voting)方法首先利用Fast R-CNN系列框架中对窗口进行回归的这个过程,反复迭代,然后用所有窗口投票,决定最终的目标类别与位置。在往年比赛中很少提到目标检测如何进行模型融合,ILSVRC2016中,CUImage、Hikvision、Trimps Soushen、360+MCG-ICT-CAS_DET都采用了几乎一致的融合策略,即先用一个或多个模型的RPN网络产生固定的ROI,再把这些ROI经过不同模型得到的分类和回归结果相加,得到最终的融合结果。经过多种融合方法的实验,分数相加的方式能获得较好的融合性能。
总结
本文对2016年ILSVRC DET任务中用到的方法进行了概括性的归纳和介绍。目标检测系统步骤甚多,过程繁琐,其中的每一个细节都非常重要。研究过程中,在把握整体结构的同时,如何处理好重要的细节会成为一种方法是否有效的关键。
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

