贝叶斯机器学习到底是什么?看完这篇你就懂啦
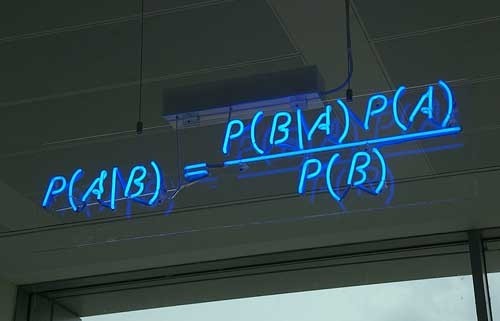
雷锋网按:不少人都在机器学习的过程中听说过贝叶斯分类器,但它是如何与机器学习建立联系的?作者Zygmunt Zając 提供了一些基础概念,雷锋网也尝试对其中的一些概念进行简化说明,让小白们也能容易地理解贝叶斯在机器学习中所起的作用。
贝叶斯学派与频率主义学派
简单说来,贝叶斯学派认为,概率是一个人对于一件事的信念强度,概率是主观的。
但频率主义学派所持的是不同的观念:他们认为参数是客观存在的, 即使是未知的,但都是固定值,不会改变。
雷锋网参阅了一些资料,尝试以我们以前课堂上所学的概率论来解释一下,频率学派认为进行一定数量的重复实验后,如果出现某个现象的次数与总次数趋于某个值,那么这个比值就会倾向于固定。最简单的例子就是抛硬币了,在理想情况下,我们知道抛硬币正面朝上的概率会趋向于1/2。
非常好理解不是么?但贝叶斯提出了一种截然不同的观念,他认为概率不应该这么简单地计算,而需要加入先验概率的考虑。
先验概率也就是说,我们先设定一个假设(或信念,belief)。然后我们通过一定的实验来证明/推翻这个假设,这就是后验。随后,旧的后验会成为一个新的先验,如此重复下去。而归根结底,就得到了这样一个著名的公式:
P( A | B ) = P( B | A ) * P( A ) / P( B )
(A | B表示A给定B的概率,也就是说,如果B发生,A发生的可能性有多大。反之亦然。)
从数据中推断模型参数
在贝叶斯机器学习中,我们同样采用贝叶斯公式从 data(D)中推导模型参数(θ)。
P(θ|D) = P(D|θ) * P(θ) / P(data)
值得说明的是,P(data)在通常情况下无法被计算,但这并不会带来什么问题。因为我们在推导及求解的过程中,最重要的还是那些含有θ的表达式,而 P(data)到底是多少,其实并不需要真的求出来。
P(θ) 为先验概率,也就是我们对样本空间中各类样本所占比例的可能性推测。通常我们认为,当训练集包含重组的独立同分步样本时,P(θ) 可通过各类样本出现的频率进行判断。关于先验的其它知识,可以参考 Where priors come from 的介绍。
P(D|θ) 是样本 D 相对于类标记θ的类条件概率,也就是我们理解的「似然」。人们经常会使用可能性来评估模型,如果对实际数据能做出更高可能性的预测,那么这个模型自然更为有效。
那么,等式左边的 P(θ|D) 就是我们最终想得到的东西,也就是基于先验概率与数据所获得的模型参数所呈现的概率分布。
如果能通过数据采样来估计概率分布参数,最经典的方法就是最大似然估计(maximum-likelihood estimation,MLE),也就是我们所说的极大似然法。而如果将先验考虑在内,那么就是最大后验概率(MAP)。如果在先验均匀分布的情况下,这两者应该相同。
统计建模
我们先将贝叶斯方法分为两类:一为统计建模,另一个为概率机器学习。后者包括了所谓的非参数方法。
建模通常在数据稀缺且难以获得时得以应用,比如在社会科学和其它难以进行大规模对照实验的环境中。想象一下,如果一个数据学家手头只拥有少量的数据,那么他会不遗余力地对算法进行调整,以期让每个数据都发挥最大的功用。
此外,对于小数据而言,最重要的是量化不确定性,这也正是贝叶斯方法所擅长的。而贝叶斯方法——尤其是 MCMC——通常计算量巨大,这又与小数据是共存的。
在名为 《Data Analysis Using Regression Analysis and Multilevel/Hierarchical Models》 的书中,介绍了从一个没有预测变量的线性模型开始,不断增加到 11 个预测变量的情况并进行讨论。这种劳动密集性模式实际上与我们的机器学习方向背道而驰,我们还是希望能使用数据,让计算机自动学习。
概率机器学习
我们现在尝试把“概率”一词替换“贝叶斯”。从这个角度而言,它与其它分类方法并没有区别。如果从分类考虑,大多数分类器都能够输出概率预测,比如最经典的SVM(支持变量机)。但需要指出的是,这些概率只是源于分类器的信念陈述,而它们是否符合真实的概率则完全是另一回事了,这也就是所谓的校准(calibration)。
贝叶斯非参数模型
接下来我们要说说贝叶斯非参数模型的一些内容,顾名思义,这个名字代表着模型中的参数数量可以随着数据的增大或减少而自适应模型的变化。这与SVM有些相似,它能在训练点中选择支持向量,而贝叶斯非参数模型也能根据数据多少来选择参数确定模型。比较流行的贝叶斯非参数模型包括高斯回归过程,还有隐含狄里克雷分布(LDA)。
高斯回归过程
高斯回归过程有点类似于 SVM——采用内核并具有类似的可伸缩性。其最大的特点在于回归特性,分类做为事后的判断,而对于 SVM 而言,这个过程是相反的。
此外,GP 是从头开始进行概率判断,而 SVM 不是。大多数的常规方法只提供数据点估计,而贝叶斯非参数模型则会输出不确定性估计。
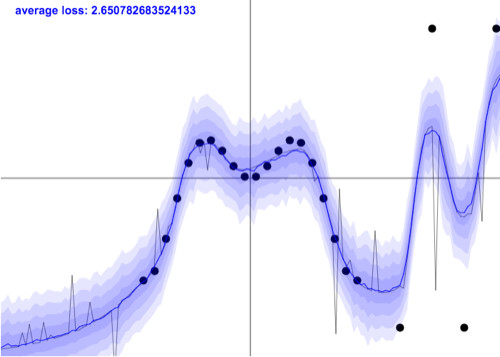
不过,「悲剧」还没有结束,像 GP 这样的复杂方法通常在假设均匀的情况下操作,而实际上,噪声实际上可能出现于输入空间(异方差)上。
高斯回归过程的流行主要应用于机器学习算法的超参数优化上。数据非常小,也只有几个参数需要调整。
LDA
Latent Dirichlet Allocation(LDA)是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeproCESs):
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
软件
至于软件,Stan 可以说是贝叶斯最为知名的概率性编程语言,它能够根据你的指定训练你想要的贝叶斯模型,能用 Python、R 或其它语言编写,不过现在 Stan 有了一个叫 NUTS(No-U-Turn Sampler)的现代采样器,它能够得到比静态 HMC 更高的计算效率。
Stan 的另一个有趣的地方在于它能自动变分推理。
变分推理是用于近似贝叶斯推理的可缩放技术。推导变分推理算法需要繁琐的模型特定计算,而自动变分推理(ADVI)算法能够为中型数据应用于小型建模铺平道路。
而在 Python 中,最为有名的是 PyMC。它并非是最先进的一个,也没有经常进行优化或迭代,但它的效果也很不错。
Infer.NET 是微软的概率编程库,它主要由 C# 或 F# 等语言提供,但也能从.NET 的 IronPython 中调用。
此外,还有 CrossCat 等用于分析高维数据表领域通用的贝叶斯方法。
资源
如果你想了解下你刚刚所学的知识,可了解下 Radford Neal 的 《Bayesian Methods for Machine Learning》。
此外还可以看看 Kruschke 的 《Doing Bayesian Data Analysis》 ,它被视为最易读的贝叶斯数据分析读物,作者对建模的内容做出了详细阐述。
基于同样内容的 《Statistical rethinking》 出版年代更新,加入了 R 语言的 Stan 实例。此外作者 Richard McElreath 也在YouTube 上发布了一系列课程,可以点击此处查看。
而如果你不想只局限于线性模型的话,Cam Davidson-Pylon 的 《Probabilistic Programming & Bayesian Methods for Hackers》 覆盖了贝叶斯的部分。Alex Etz 的 《understanding Bayes》 也可以读读。
对于数学爱好者,Kevin Murphy 的 《Machine Learning: a Probabilistic Perspective》 是一本不可多得的读物,如果对模式识别是真爱的话,可以看下 《Pattern Recognition and Machine Learning》 。
David Barber 的 《Bayesian Reasoning and Machine Learning》 目前在网上已经有免费电子版,最近也非常流行,主要讨论了机器学习的高斯过程。
据雷锋网所了解的是,目前贝叶斯机器学习还没有 MOOC 课程, 但 mathematicalmonk 频道的机器学习视频有对贝叶斯进行介绍。
Stan 也有一个通用手册,另外 PyMC 的引导书上也有不少例子。
关于贝叶斯与机器学习的一切,雷锋网 (公众号:雷锋网) 就为大家介绍到这里,所提供的资源也可能无法完全覆盖现在所有的优秀读物,如果你有更好的建议,欢迎与雷锋网交流讨论。
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

