TensorFlow白皮书阅读笔记
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Gregory S. Corrado, Andy Davis,Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian J. Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard,Yangqing Jia, Rafal Józefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore,Derek Gordon Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul A. Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda B. Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, Xiaoqiang Zheng:
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems . (2015.11)
编程模型与基本概念
TensorFlow的计算过程采用一张有向图(DAG)来描述,有向图由许多节点(nodes)构成,图代表了一个数据流(dataflow)计算过程,用户通常用某种前端语言(C++/Python)建立一个计算图,来执行某个过程。
在TensorFlow图中,每个节点(node)可以有任意个输入,任意个输出,代表了一个操作的实例化,流过图中正常的边(edge)(从输出到输入)的值(Values)称为张量(Tensor),可以理解为任意维的array。有一些特殊的边,称为控制依赖(control dependencies),没有数据流过,表示节点与节点之间一种序关系,也即happens-before关系。
- 操作(Operation):一个操作代表一次抽象计算,有一个名字,还能有一个属性,所有的属性必须给定或者能够在图建立的时候就推断出来,属性的作用主要就是是操作在不同的张量类型上保持多态(?)
- 核(Kernel):操作的特殊实现,可以运行在一个特定设备上。
- 会话(Session):用户与TensorFlow系统交互的客户端程序,提供许多操作。主要是Run,即获取需要计算的输出,以及fed进来的输入,运行一次整个流图的计算,得到结果填入输出中。一般是对一个图启动一个Session,然后执行多次。
- 变量(Variable):大多数情况下,图是执行多次的,大多数的Tensor在一次执行后不会继续存活,然而变量(Variable)是一种特殊的操作,它返回一个到持久化可变张量(persistent mutable tensor)的句柄,就是说它的生命周期是整个图的计算过程。这样可以保证许多机器学习任务中参数的持续迭代改变。
- 设备(device):设备是TensorFlow的计算核心,每个worker负责一到多个设备,每个设备有一个名字,设备通常指的就是某个CPU或者GPU,它的命名方式有一定讲究,比如
/job:localhost/device:cpu:0等。 - 张量(Tensor):一种有类型的多维数组,元素类型包括大小为从 8 bit 到 64 bit 的带符号和无符号整型,IEEE 浮点数和双精度类型、复数类型和字符串类型(任意长的字节数组)。通过一个分配器来管理其后台存储(backing store),且维持一个引用计数,在没有引用时释放。
Implementation
单设备执行
单设备执行不用说了,一切都在本地,每个节点维护一个依赖计数,表示该节点的先序节点还有多少个没有执行,如果该计数为0,则将该节点放入准备队列ReadyQueue等待执行。
多设备执行
多设备执行中,主要有两个复杂性:
- 如何分配哪个节点在哪台设备上计算?
- 管理跨设备的数据通信
节点置放
现在有一张计算图,TensorFlow需要将这些节点的计算放置到可用给的设备上,如何分配每个节点到具体的设备是要解决的问题。
此版本的TensorFlow采用了一种模拟执行过程的启发式的cost model,即先模拟一遍图的执行过程,采用启发式贪心策略来分配。首先设备需要满足能够执行该node所需的操作,然后再谈分配的问题,在备选的设备中选取一个预计执行时间最小的设备,放置,然后进行下面的分配,当然在有控制依赖的时候还需要加以考虑。目前来说, 置放算法还在进一步地研究优化 。
设备间通信
TensorFlow采用Send节点和Receive节点来实现跨设备的数据交换。将设备A中a节点到设备B中b节点之间的边用send和recv的节点隔开,如图所示。

这使得我们将Send和Receive内部的通信机制与节点与节点之间的通信隔离开来。而且这种方式下,master只需要提出“任务”(通过Run)给workers,而无需管理workers之间的通信,这就相当于去中心化(decentralized)了,大大减小了master的负载。
要注意的是,如果一台设备上的两个或多个tensor都依赖于另一台设备的某一个tensor,TensorFlow只使用一个Recv节点,参看上图右边的b,c。
分布式执行
分布式执行非常像多设备执行,之中要解决容错的问题。
错误主要发生在:
- Send/Recv的通信错误
- 周期性的保活检查(keep-alive)时
如果发生了错误,那么整个图会终止执行,并重启。如果简单地这样处理的话,那些正确计算好的节点就得重新计算,不高效,所以TensorFlow支持在重启过程中一致的检查点和状态恢复。
怎么实现的呢?
每个节点有一个到Save节点的连接,也被一个Restore节点所连接,周期性地执行Save,持久化变量到比如分布式文件系统等存储上。类似的,Restore节点负责在重启后的第一个迭代中恢复变量的值(或状态?)
扩展
TensorFlow内嵌地支持自动梯度计算。
在存储管理(memory management),TensorFlow的作者们也在寻求提升的方法。一些可能的选项包括:
- 使用更加复杂的启发式算法来决定图的执行顺序
- 重新计算tensor而不用把他们保持在主存
- 将长久存在的tensor从GPU memory中交换到更加丰富的主机CPU
TensorFlow支持图的部分计算,如图:
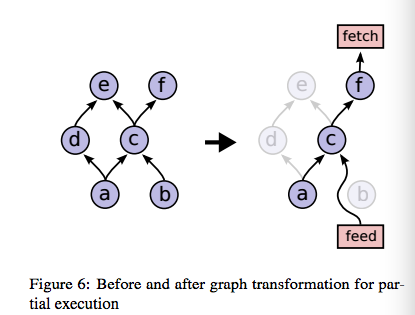
显然,支持条件与循环会导致更加精确和高效地表示机器学习算法,TensorFlow提供了一些控制流操作原语包括Switch,Merge,Enter,Leave,NextIteration等。
每轮迭代由一个唯一的tag标识,执行状态由一个frame来表示,一个输入只要可用就可以进入一个迭代过程,因此,多个迭代可以并发地执行。
尽管输入数据可以通过feed节点提供,另一个典型的训练大规模机器学习模型的机制是在图中采用特殊的输入操作节点(input operation nodes),节点通过文件名配置,这使得工作节点可以直接从存储系统中将数据拿到内存。
队列是很有用的一个特性,允许图的不同部分亦不知悉,按照不同的节奏通过Enqueue和Dequeue来处理数据。队列的一个用途是允许输入数据提前从文件中取出,此时并不耽误前一批数据的处理,更有效率。TensorFlow不仅实现了基本的FIFO队列,还实现了一个shuffling队列,可以随机shuffle一个大型内存buffer中的元素。
容器是用来管理长期存在的可变状态的机制。默认的话,容器一直保持到进程结束。
优化
本部分描述了TensorFlow的实现过程中所做的一些优化,提升性能并且提高了资源的重用率。
这些优化包括:
- 消除公共子表达式
- 控制数据通信与内存使用,调度优化是必要的且有效的
- 异步核(?)
- 核实现的优化库,cuDNN,cuda-convnet,cuBLAS等
- 有损压缩。为了减少通信量,将一些浮点数的位数压缩,比如32位浮点数压缩到16位,通过损失一定精度换来跨机通信的高效。
一些经验
本部分介绍了作者们在移植/迁移机器学习模型(从一个系统到另一个系统)中的一些经验教训。
包括:
- 对参数的个数有一个洞察
- 从小(模型)开始逐步扩展
- 保证目标函数的正确性
- 先单机,再分布式
- 防备数值错误/误差
- 分析网络,理解数值误差的量级和容忍度。可以同时在两个系统中跑,看结果是否一致来判断有无数值误差/错误
数据并行,模型并行与并发步
TensorFlow关心的一大领域就是加速计算密集型的大规模神经网络的训练。本部分描述了一些方法。
数据并行
数据并行分为同步数据并行和异步数据并行。见图:
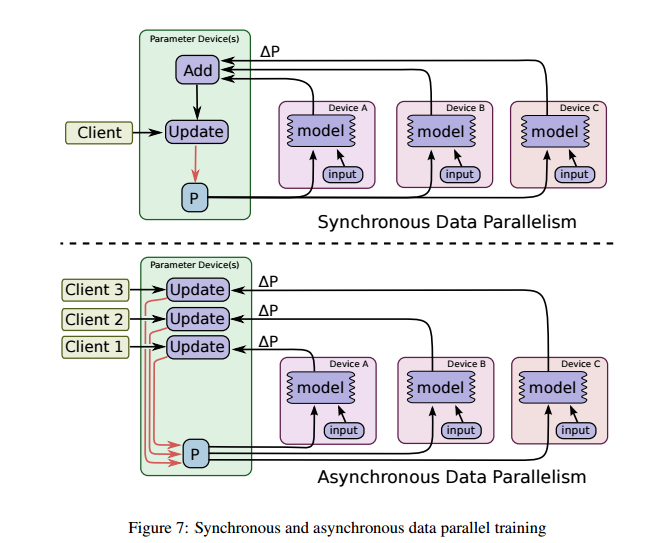
数据并行的意思是,用很多的模型副本,每个副本运行在不同的数据上,然后同时训练,更新模型。通过更新模型的方式不同,可以分为同步和异步,同步的方式是一个用户线程驱动整个大循环,如图上部,等到所有的$/Delta P$都算出来后,将它们相加去更新模型。而异步的方式不同,每个模型副本自己异步地对模型参数进行更新,不用等到所有的梯度算出来再更新,每个模型副本有一个用户线程。见图下部。
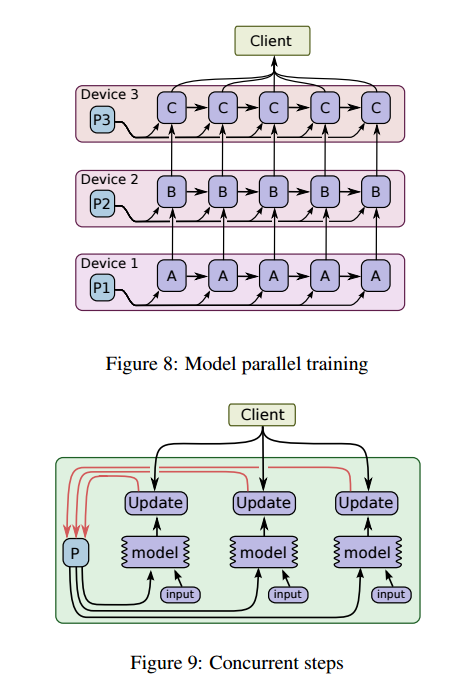
模型并行和并发步(concurrent steps)
模型并行的意思是,对于同样一批数据,模型计算的不同部分分散在不同的计算设备上同时进行。如图是一个循环深度LSTM用来做序列到序列学习的例子。(?)
并发步是另一种通常的做法,即通过在同样的设备集合中运行少数的并发步来将同一设备中的模型计算流水线化。(?)
工具
TensorBoard用来对计算图,总结信息和训练过程等进行可视化,方便观察训练过程。
性能追踪(performance tracing),了解哪些地方是瓶颈时间。EEG。
未来工作
未来工作包括:
- 子图的重用,像函数一般
- 置放算法与节点的调度,可能采用DNN和强化学习相结合来学习置放
- just-in-time compiler
- 跨操作动态编译框架(cross-operation dynamic compilation framework)
- 等等。。。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

