微店实时计算平台实践
引言
随着微店业务的蓬勃发展,目前很多核心系统都需要使用实时数据,归纳了下微店的实时业务形态,大致分为如下几方面:
1. 实时在线系统,比如搜索、推荐和广告
2. 监控预警,比如用户行为预警、app crash预警、风控
3. 实时ETL,主要是进行数据清洗,归并,结构化
4. 实时报表,比如交易大盘,微团购大盘
5. 消息异地同步,比如binlog消息转换成业务消息
除了上述五种常见业务,还有例如像实时push消息以及短信通知等都可以通过实时计算平台进行统一分发。
在支撑业务的过程中,发现一些具有共性的问题,具体表现如下:
1. 技术选型多种多样,各个团队独自维护,导致实时开发门槛高,主要体现在开发者需要关注很多实时底层处理细节。
2. 效率低,主要体现在调试不方便,新发布中断时间长等。
3. 稳定性不能保障,主要体现:没有规范的开发流程,上线随意等。
4. 缺少统一的监控运维配套,常常线上发现故障,很长时间之后才能发现。
5. 数据共享不透明,比如业务团队需要使用推荐团队的用户特征,通过统一的平台可以避免重复开发,数据信息共享等。
为了更好的支持上述各种实时业务以及解决上述问题,提供统一高效的实时计算开发平台显得很有必要。实时计算平台代号comet,comet原意彗星,我们希望微店的实时处理能力能像彗星划过天空一样快速而精彩。
实时计算平台的整体架 构
整体架构描述
comet 实时计算平台整体架构如下图所示:
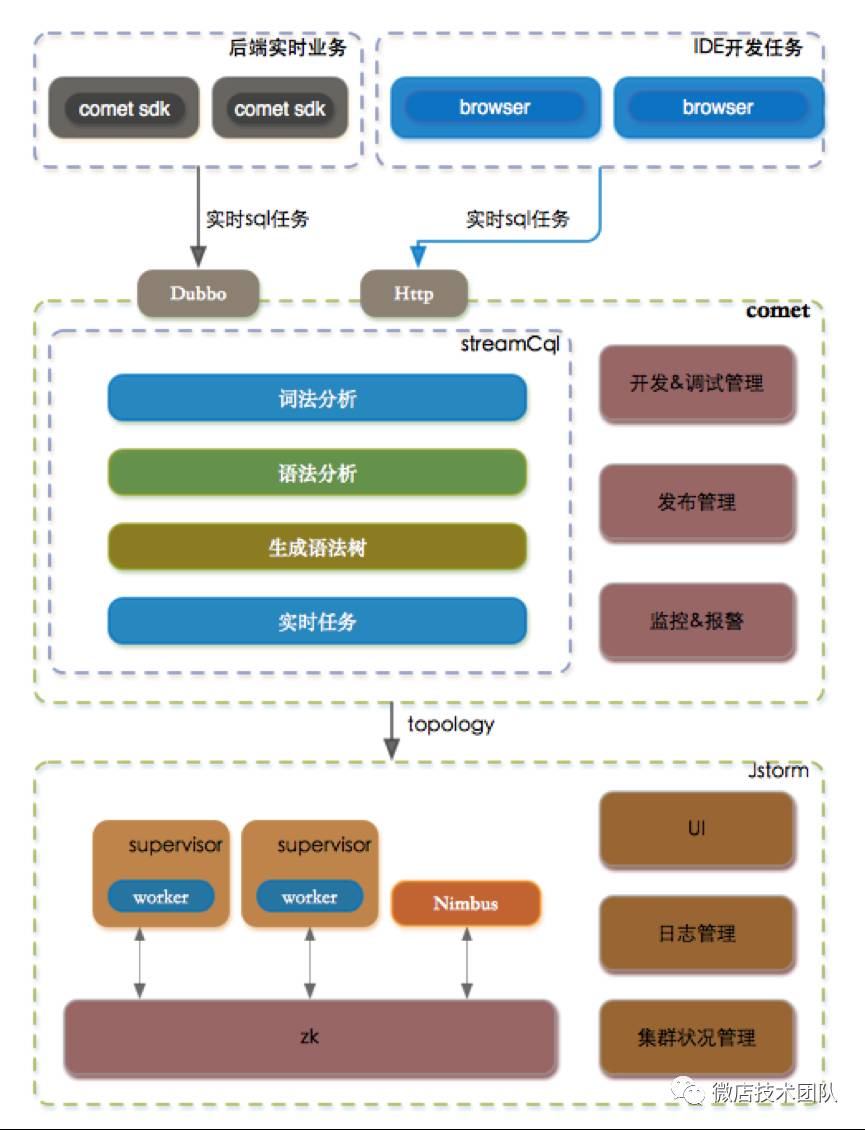
任务开发流程
通过comet平台重新定义了实时数据开发的整个流程,下图主要展示通过sql开发实时数据的流程:
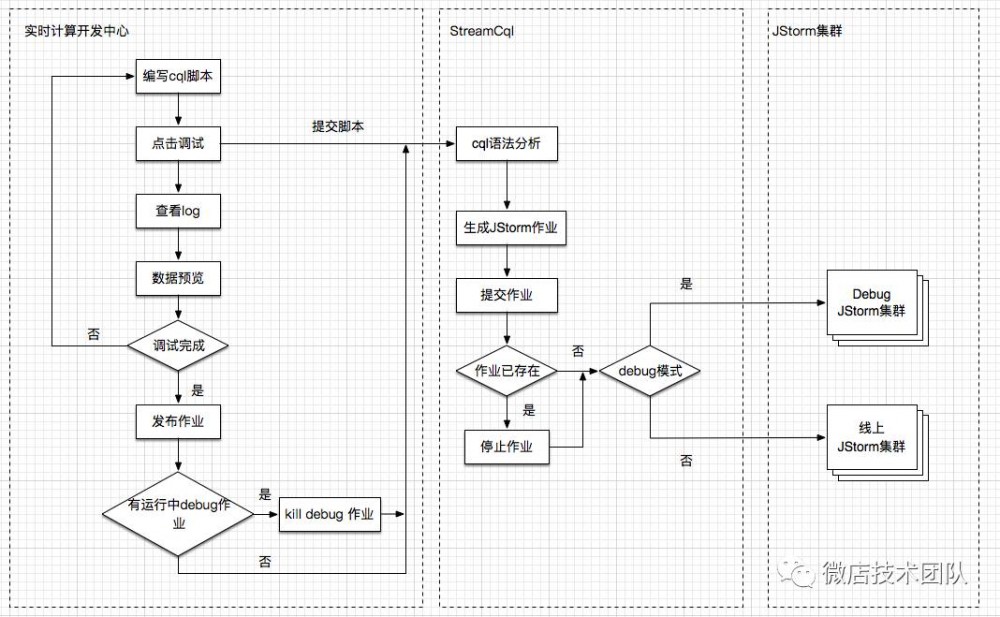
(看不清,请点击放大)
选择 sql 开 发实时 任 务 的考量
微店开发实时数据大概经过三个阶段,初始阶段每个实时业务开发都是各自为战,这个时期的实时业务处于萌芽阶段,规模相对比较小。数据开发人员使用Storm原生API开发流式作业,开发门槛高,系统调试难,存在大量重复的人肉工作,举个例子,这个时期处理H5的日志文件,每条业务线从消息队列kafka接收到逻辑解析处理到最后存储,都是各自开发一套逻辑,有时候不同业务消费group设置成同一个都未曾发觉。第二个阶段我们把很多重复使用的组件进行抽象封装,比如实现了简单过滤、聚合、窗口等等作为基础的编程组件,这个阶段很多实时任务就是基于这些基础编程组件进行组装,一定程度上降低了使用门槛,但是开发人员还是需要了解整套编程组件,使用起来门槛依然比较高。第三个阶段就是我们引入类sql语言来开发实时任务,sql语言经过几十年的发展,接受度比较高,同时学习门槛很低,适合群体相对更加广泛,数据分析师、算法等也很容易上手进行开发。下面举个简单的采用sql开发实时任务的例子,主要逻辑是从消息队列接受日志数据,经过实时清洗到存储到elasticsearch,供业务方报表展示。
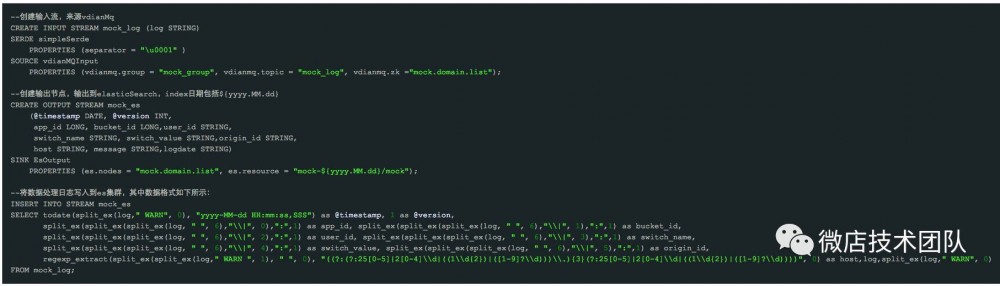
(看不清,请点击放大)
底 层选择 Jstorm 的技 术 考量
之前微店采用的storm作为底层实时处理引擎,comet实时计算平台基于以下考量采用了Jstorm作为底层实时处理引擎:
1. 兼容之前storm任务,无需二次开发
2. 稳定性更高:相比storm,nimbus实现了HA,彻底解决雪崩问题,资源分配更加合理,减少对ZK的访问等
3. 调度更强大:资源调度深度优化等
4. 相比heron,jstorm任务的维度为线程,heron为进程,避免了消息的传输全部走网络。根据jstorm官方文档,heron无性能优势
在开源基 础 上做了哪些二次开 发
SQL 解析并未进行自主研发,采用的是华为开源的streamCql,streamCql底层采用的主流的语法解析工具antlr,一方面华为在这方面做得相对比较完善,另一方面之前在这一块有一定的技术积累。综合考虑在开源的基础进行二次开发显得比较适合。针对streamCql做了大量的二次开发以满足目前微店的业务,列举如下:
1. 增加了ack机制,目前streamCql并未实现ack机制
2. 输入算子开发,目前支持kafka,vdianMq,rocketMq,覆盖微店主流的数据输入源。
3. 输出算子开发,目前支持mysql,elasticSearch,vdianMq,kafka,rocketMq,redis等,覆盖主流的输出。
4. DataSource 开发,支持mysql,搜索引擎,redis等,主要为了支持实时数据过滤,补全等功能。
5. UDF 开发,参考Hive目前支持的大部分功能,开发了对应的UDF。
6. 新增支持复杂结构,比如map和array等,支持转义字符等。
7. 针对目前streamCql生成的Jstorm任务效率不高,做了算子合并,序列化等优化。
Jstorm 相对比较成熟,主要是将调试日志、业务日志以及系统日志做了分离,并且存储到elasticsearch里,供comet做调试,追踪bug以及报警使用。同时为了保障线上各任务之间不互相影响,采用cgroup做资源隔离,目前正在测试中,还未正式上线。
踩过的坑
1. streamCql 生成拓扑优化
通过sql生成的bolt层级太多,导致实时任务吞吐量比较低,同时延迟比较大,通过优化拓扑图,让出度和入度都为1的算子进行有策略的合并,减少网络IO,减少数据shuffle。
2. streamCql 支持复杂类型
在微店的业务场景里,很多数据格式是json类型的,一开始采用各种嵌套UDF表达json,导致sql可读性极差且容易出错,后面通过支持map和array相关复杂类型,彻底解决这类问题。
3. 输出算子流控
app 端的日志通过实时处理,写入到elasticsearch中供数据业务方使用,初期版本并未做流控设计,当日志从5000w增长到亿级别的时候,出现bolt写入变慢,出现日志大规模处理延迟。通过实现写入elasticsearch流控控制,解决该问题,单条写入转变为批量写入,但是一定程度上牺牲了实时性。
4. Jstorm 相关问题
比如acker数量设置为0,这时候不发送任何消息,另外比如worker数量设置为大于10,这个时候topologyMaster从线程变为进程级别,需要额外一个worker进程处理。Jstorm使用过程中遇到过一些问题,后续会有专门的Jstorm使用经验分享。
展望 & 后 续 工作
目前comet平台并不支持trident和batch等特性,后续会整合到streamCql中,更好的支持微店的业务,同时目前comet平台监控报警等还不完善,后续会逐步完善,力争提供一体化的实时数据开发平台。目前比较火热的spark streaming,此外google提出的新一代的数据处理引擎dataflow以及twitter提出的heron等,这些会结合微店具体业务去做一些尝试,毕竟在实时处理领域也并没有银弹。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

