Cherami:Uber Engineering的可持续和可扩展的任务队列
Cherami是一个分布式、可扩展、可持续和高可用性的消息队列系统,我们在 Uber Engineering 开发并用于传输异步任务。我们将这个任务队列系统,以一只英雄传信鸽的名字命名,希望这个系统具备同样的弹性和容错能力,允许Uber的任务关键业务逻辑组件依赖于它的消息传递。

Cher Ami 是 第一次世界大战中的美国陆军传信鸽 。尽管她腿部中弹,但依然成功传递了报信, 拯救了194条生命。
引言
允许分布式系统中的一个任务队列解耦组件以异步方式进行通信。通信双方可以单独扩展,以增加负载平滑或节流的功能。在复杂的分布式系统中,任务队列必不可少。在Uber的基础设施生态系统中,Cherami充当简单队列服务( Simple Queue Service,SQS )的角色。将我们自己的系统与现有的基础设施更好地集成,同时解决一些独特的产品开发需求,如支持多个消费者组,提高可用性,特别是在网络分区中。
Cherami的用户被定义为生产者或消费者。生产者将任务排队。消费者是异步接收和处理排队任务的工作进程。Cherami的交付模式是典型的 竞争消费者 模式,其中同一消费者组中的消费者接收不相交的任务集(除了失败情况,这会导致重新交付)。使用这种模式,多个工作程序能够并行运作。工作程序的数量独立于Cherami内部的任何分区或分片机制,并且可以简单地通过添加或删除工作程序来扩展和缩小。如果工作程序无法执行任务,则另一个工作程序可以重新传送并重试该任务。
Cherami还支持多个消费者组,其中每个消费者组接收队列中的所有任务。每个消费者组都与一个死信队列( dead letter queue )相关联。超过最大重试计数的任务(例如,“poison pill”)驻留在此队列中,以便消费者组可以继续处理其他消息。这些消费者处理简单消息总线,从中区分Cherami,通常用于大数据摄取和分析(如 Apache Kafka ),使Cherami在任务队列用例中处于优势。
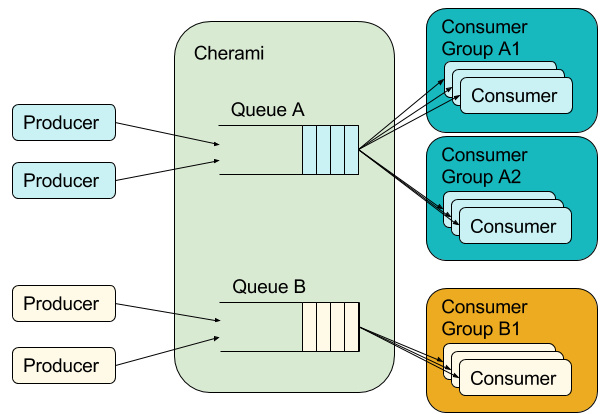
生产者将任务排到队列A和B。队列A将提要发送到两个消费者组,这两个消费者组都接收所有任务,分布在相应组内的消费者。队列B仅将提要发送到一个消费者组。
在未使用Cherami之前,Uber使用 Redis 支持的 Celery 队列用于所有任务队列用例。Celery和Redis的组合帮助了Uber迅速扩张,达到巅峰。至于缺点,那就是Celery只有Python,而我们越来越依赖Go和Java来构建性能更高的后端服务。此外,Redis存储是内存支持的,这不符合我们对可持续或可扩展的要求。
为了Uber的未来,我们需要一个长期解决方案。所以我们构建了Cherami来满足这些要求:
- 持续性、无损性和硬件故障容错性
- 网络分区期间 可用性和一致性(AP vs CP) 之间的灵活性
- 轻松调整每个队列吞吐量的扩展能力
- 完全支持竞争消费者消费模式
- 语言无关性
为了满足这些要求,Cherami的设计遵循这些设计原则:
-
最终我们选择了一致性作为核心原则。这允许高可用性和持续性,为此,我们牺牲了订购保证。无论如何,这意味着我们可以在灾难性故障或网络分区期间继续接受请求,并通过消除对像 Zookeeper 这样一致的元数据存储的需求,进一步提高可用性。
-
我们选择不支持分区消费者模式,不向用户公开分区。这简化了消费者工作程序的管理,因为工作程序不需要协调要使用哪个分区。它还简化了配置,因为生产者和消费者都可以独立扩展。
在下面的章节中,我们进一步阐述Cherami的关键设计元素,并解释我们如何应用设计原则和权衡。
Cherami的关键设计元素
1.故障恢复和复制
为了真正的无损性和可用性,Cherami必须容忍硬件故障。实际上,这需要Cherami通过不同的硬件复制每条消息,以便消息能够可靠地读取;但当硬件暂时或永久失效时,Cherami也必须能够接收新消息。
Cherami的容错性源于利用消息系统的附加属性和消息传输中的流水线。消息队列中的每个消息都是一个自包含的元素,一旦创建就不会被修改。换句话说,消息队列只能添加(append-only)而不能修改。如果包含队列的存储主机失效,我们可以选择不同的存储主机并继续写入,从而保证入列操作继续可用。
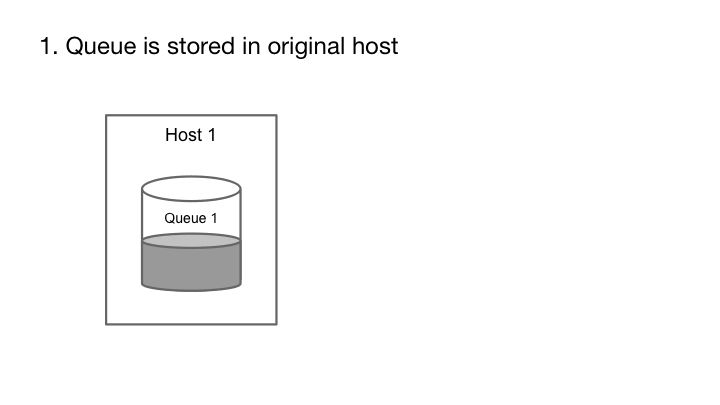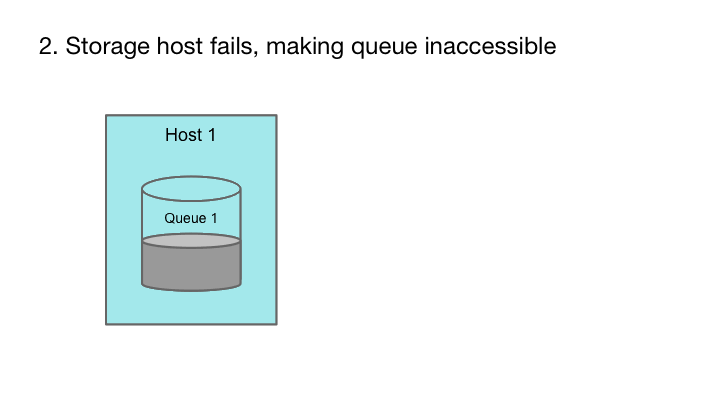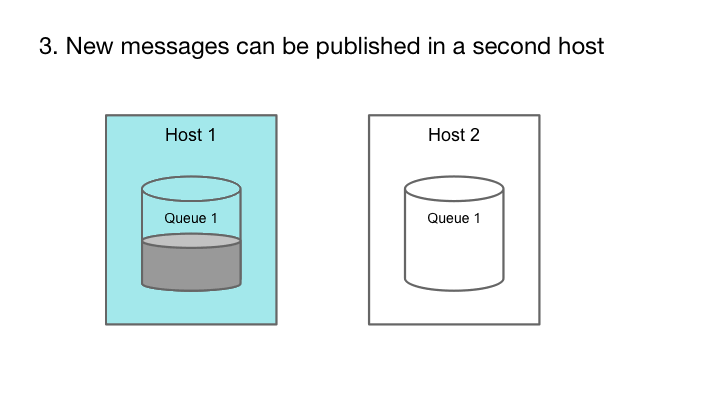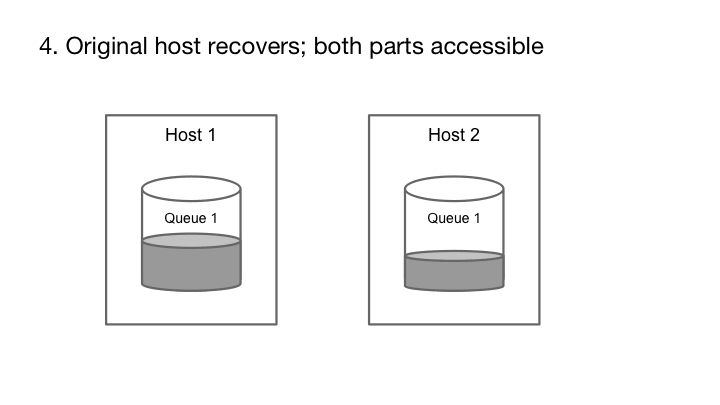
append-only属性允许队列在硬件故障期间仍然可以进行发布。
Cherami队列由一个或多个区段组成,这些区段是队列中独立支持附加消息的概念性子流。通过称为输入主机的角色将扩展区复制到存储层。创建扩展时,其元数据包含不可变的主机信息元组(输入主机和存储主机列表)。在每个存储主机中,扩展的复制副本称为副本,存储主机可以托管不同扩展数据块的多个副本。如果单个存储主机发生故障,我们不会丢失消息,因为该区段仍可从其他副本读取。
Cherami处理存储主机故障。
生产者连接到特定输入主机以发布到属于某个队列的区段。在从生产者接收到消息时,通过 WebSocket 连接到所有区段副本的同时输入到主机消息管道。并从同一连接中的相应副本接收确认(ack)。
流水线意味着输入主机在写下一条消息之前不等待ack,并且在输入主机和所有副本之间没有消息重排序或消息跳过。这也适用于从每个副本返回ack;ack按照相应的写入顺序排列。输入主机跟踪所有ack。只有当接收到相同消息的所有存储主机收到ack时,输入主机确认生产者。这个最后的ack意味着消息已经持久地存储在所有副本中。
由于流水线属性,在每个区段内消息将被排序。这将确保所有副本的消息是一致的,除了存储主机尚未持久消息的尾部。
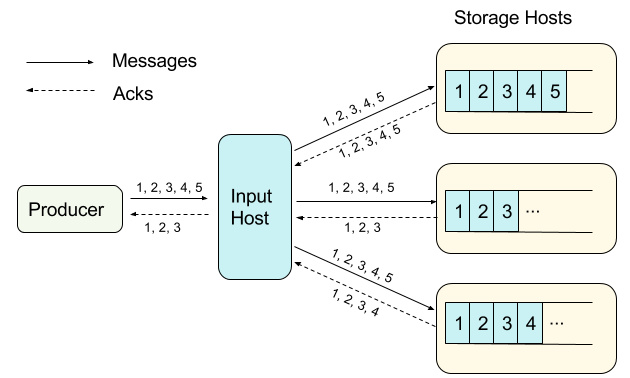
输入主机只接收来自所有存储主机的前三个消息的ack。它将前三个消息发送给生产者,因为这些消息被保证被完全复制。
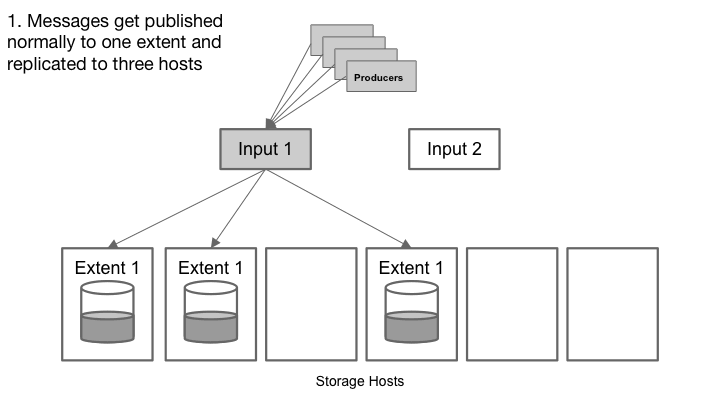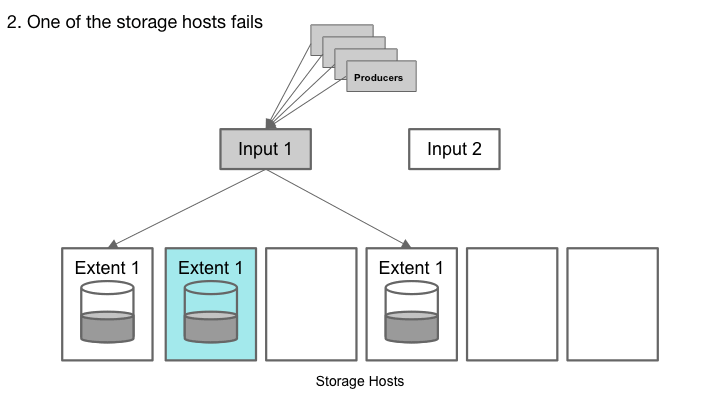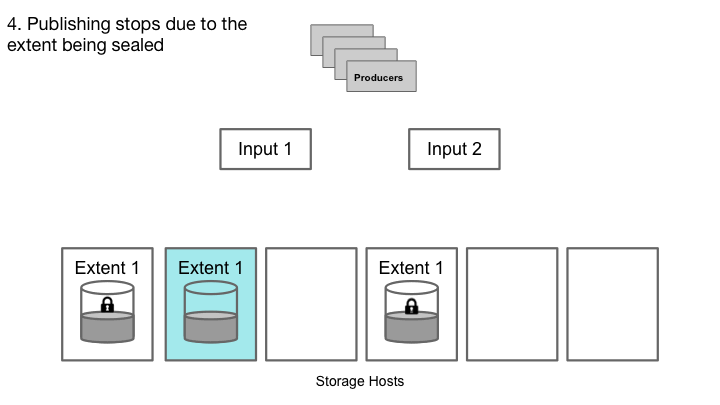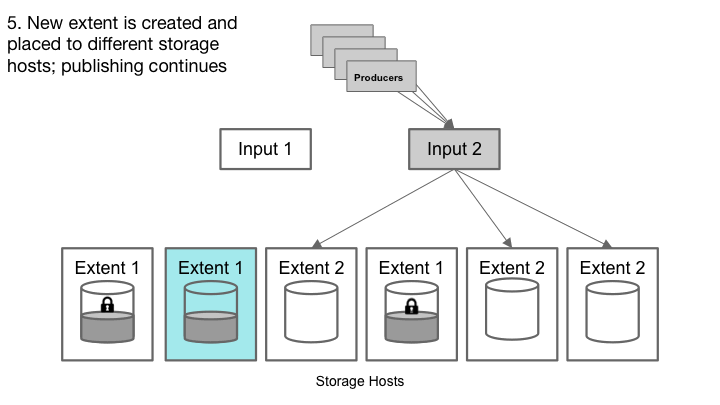
当任何副本失败时,输入主机不能从该副本接收任何进一步写入的ack。因此,这个意义上来说不再是可追加的。如果输入主机失效,我们将失去来自存储主机的空中ack。在这两种情况下,副本的尾部可能不一致:一个或多个消息不会在所有副本中被复制。为了从这种不一致性中恢复,而不是试图扫描和修复尾部,这是一个复杂的操作,我们简单地声明这个区段“密封”它是可读的,但不允许更多的写入。
密封后,Cherami为此队列创建一个新的区段,并且一个信令通道通知生产者重新连接并发布到新的区段。如果队列只包含一个打开区段,那么密封该队列将使队列在创建新的区段之前暂时无法在很短时间内发布。为了避免在故障期间出现峰值延迟,队列通常设置最小数量的区段,以便在密封一个区段并创建新区段时,发布可以继续。
我们选择使用密封作为恢复机制,因为它易于实施。复制的原因是,在失败之后,副本将包含未发布给发布者的消息,并且如果输入主机已经失效,则不可能确定哪些消息是未封装的。因此,在读取路径中,我们将必须传递一切,包括这些未封装的消息。当消息队列失败时,发布者通常会重试,所以这些部分消息可以发布到一个新的区段,使得消费者能够重复接收。
2.写入的缩放
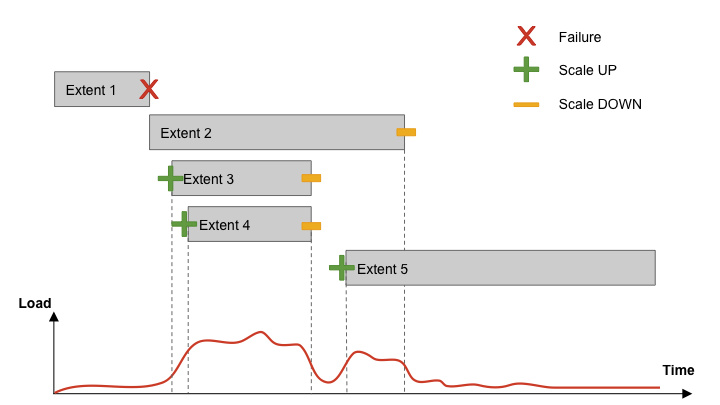
Cherami中的区段是非共享子流。Cherami观察每个区段的吞吐量。由于对特定队列的写入负载增加,并且某些区段超过其吞吐量限制,Cherami就会自动为该队列创建附加区段。新区段接收部分写入负载,减轻现有区段上的负载。
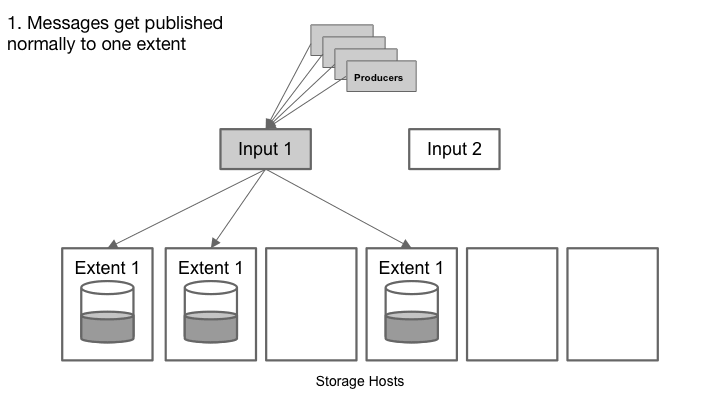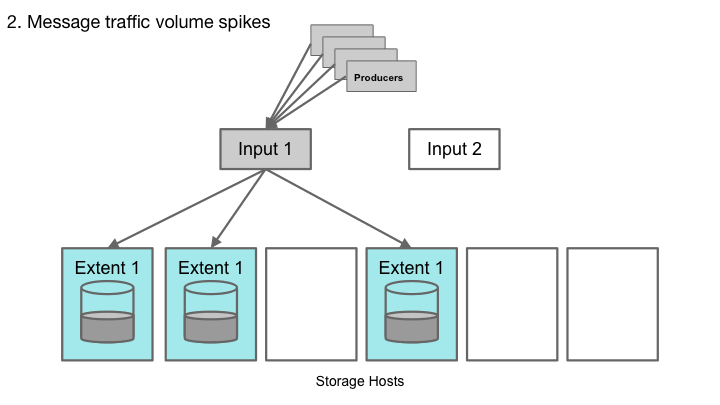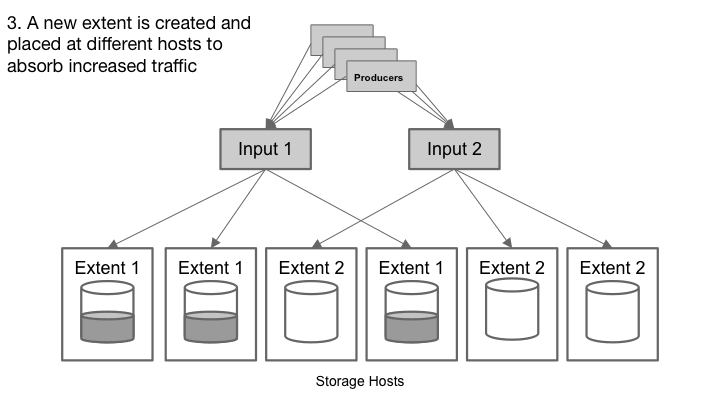
随着写入负载的减少,Cherami密封一些区段,而不用新的替换。这样,Cherami减少了维持开放区段所需的一些开销(内存、网络连接和其他维护)。
3.消费处理
同一消费者组中的消费者从同一队列接收任务,但也可以从一个或多个区段接收。当消费者收到消息并成功处理消息时,消费者使用ack答复Cherami。如果Cherami在一些配置的时间后没有获得确认,它会重新提交消息以重试。当消费者崩溃时,或者当下游依赖不可用时,或者当单个任务花费太长时,或者当由于死锁而导致处理被阻塞时,消费者的确认可能被延迟或丢失。消费者还可以否定地确认或否认消息,触发立即重新传递。Nacks允许消费者组处理某些成员不能处理的任务(例如,由于本地故障、消费者组到新任务模式的部分/滚动升级)。
因为不同的消费者可以花费不同的时间来处理消息,所以ack到达Cherami的顺序,与副本提供的顺序并不同。一些消息系统存储每个消息的已读/未读状态(也称为可见性状态)。但是,为了做到这一点,我们需要在磁盘上使用随机写入更新这些状态,并为多个消费者组中处理每一个复杂的操作。
Cherami采取了不同的方法。在每个消费者组中,对于每个区段,我们维护一个ack偏移量,这是一个消息序列号,在其下所有消息都被确认。我们有一个称为输出主机的角色,消费者为了接收交付而连接到它。输出主机按顺序从存储主机读取消息,将它们缓存在内存中。它记录正在传输的消息(传递给消费者,但尚未确认),并在可能时更新ack偏移量。输出主机还跟踪定时和nack,以便消息可以根据需要重新传递给另一个消费者。在Cherami中,一个扩展可以由多个消费者组同时使用,因此多个输出主机可能从同一区段读取。
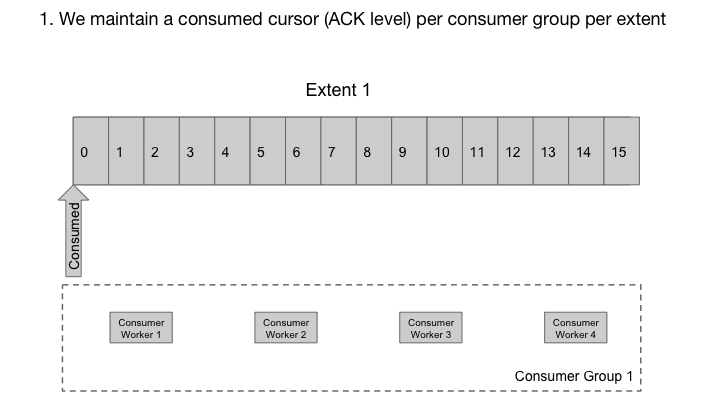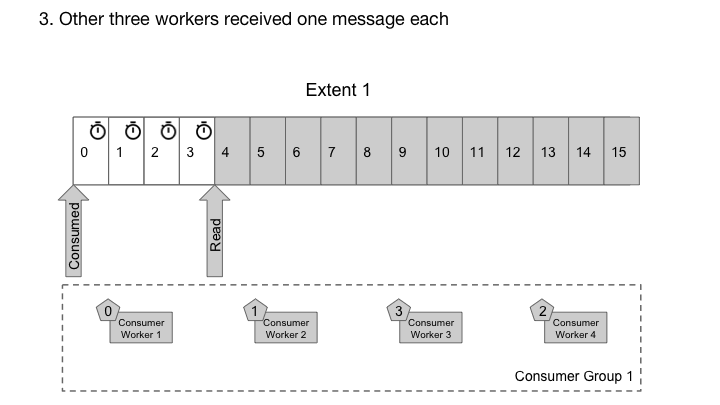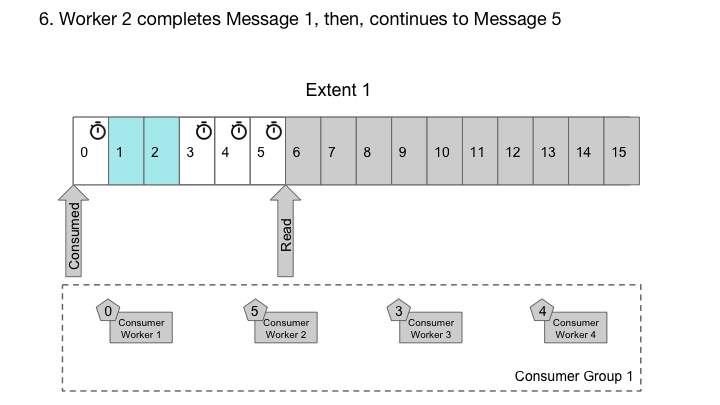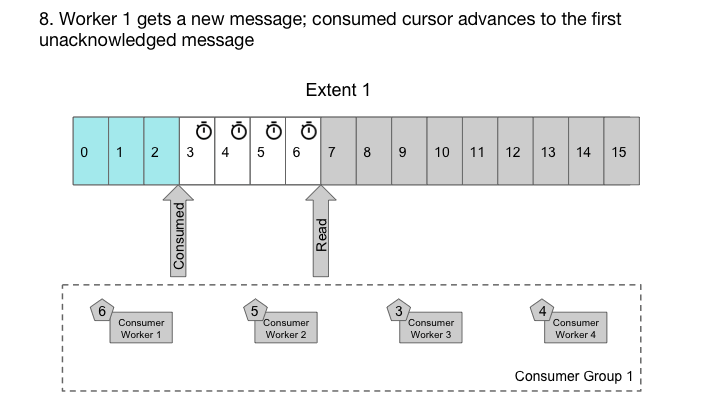
输出主机处理工作程序的乱序ack。
此外,系统为将每个消息配置重新传递有限次数。如果达到重新传递的限制次数,消息将被发布到死信队列( dead letter queue,DLQ )并被标记为acked,使得ack偏移可以提前。这样,没有“毒丸”消息阻塞队列中其他消息的处理。使用者组所有者可以手动检查DLQ中的消息,然后使用以下两种方式之一处理消息:清除或合并它们。清除它们将删除消息,并且当它们无效或者没有值(例如它们是时间敏感的)时是适当的。否则,所有者可以将它们合并回消费者组,这在消费者软件已经修复可处理先前不能处理的消息时或者当暂时故障条件已经消退时是适当的。
4. 存储
Cherami中的消息持久存储在磁盘上。在存储主机上,为了性能和索引功能,我们选择了 RocksDB 作为存储引擎。我们使用一个独立的RocksDB实例,每个盘区有一个共享 LRU 块缓存。消息存储在数据库中,增加的序列号作为键,消息本身作为值。因为键总是增加,RocksDB优化其压缩,所以我们不会经历写入放大。当输出主机从一个区段读取消息时,它只是寻找其服务的消费者组的ack偏移量,并按序列号重复读取更多消息。
使用RocksDB,我们也可以轻松实现定时器队列,这是每个消息与延迟时间相关联的队列。在这种情况下,消息仅在指定的延迟后传送。对于定时器队列,我们构造包含高位位中的递送时间和低位位中的序列号的密钥。由于RocksDB提供了一个排序的迭代器,按照交付时间的顺序迭代密钥,而低位的序列号确保密钥的唯一性:
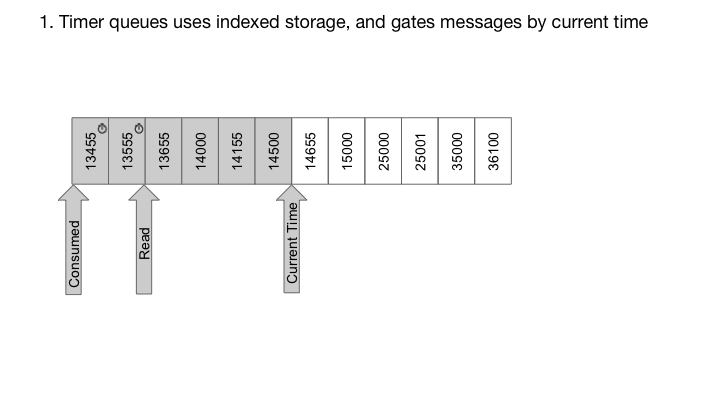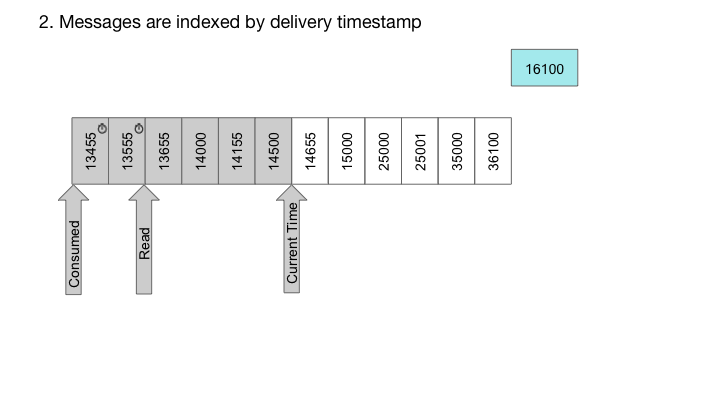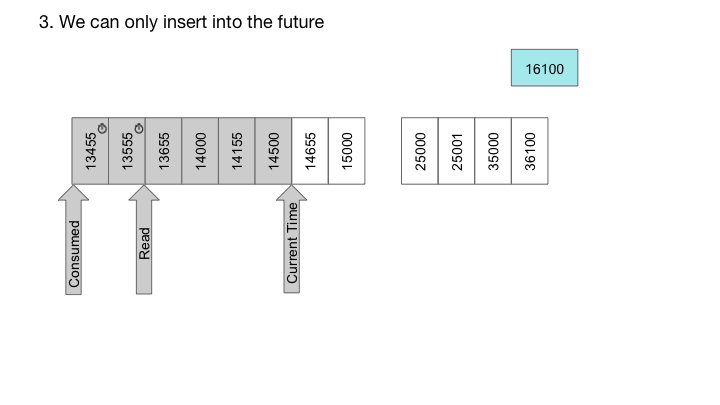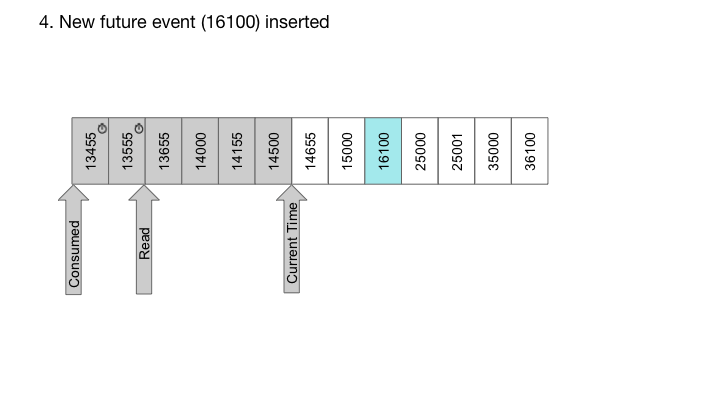
系统架构
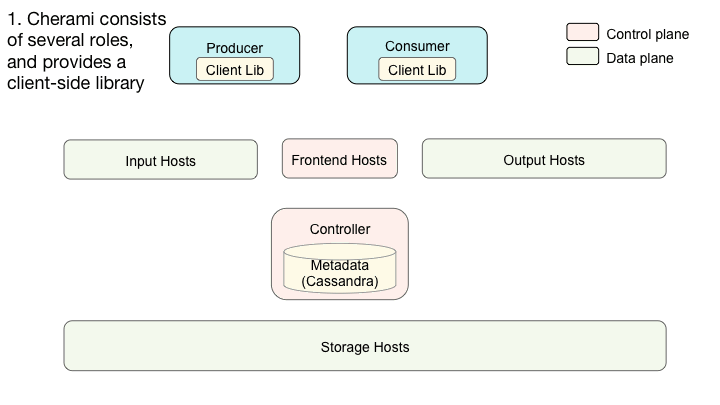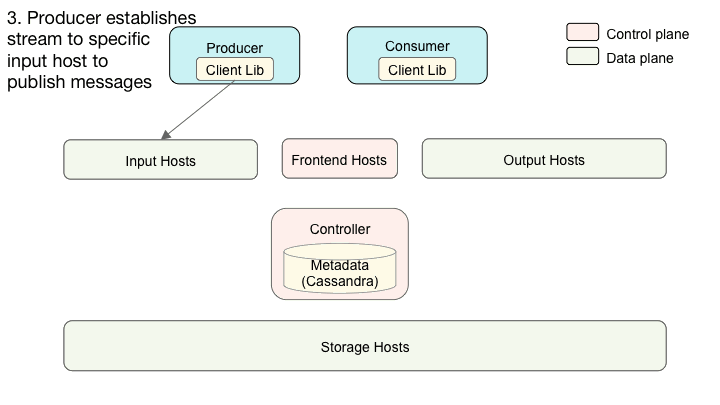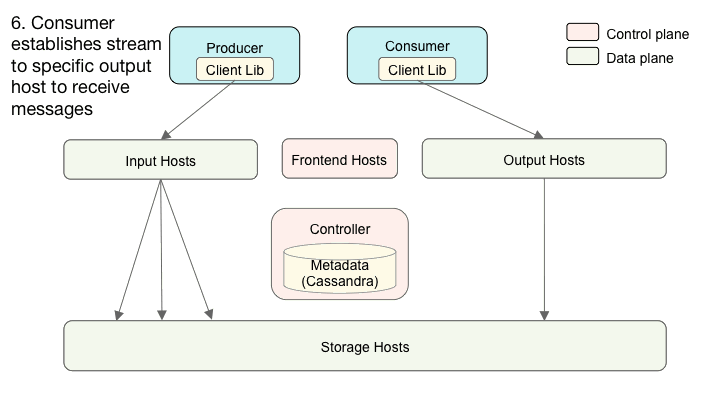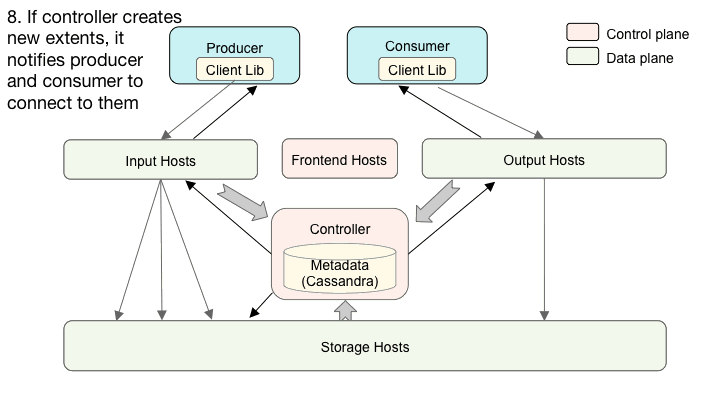
Cherami由几个不同的角色组成。除了我们已经介绍的输入、存储和输出角色之外,还有控制器和前端。典型的Cherami部署包括每个角色的几个实例:
Cherami系统组件的相互作用。
不同的角色可以存在于同一物理主机上,甚至可以链接到单个二进制文件中。在Uber,每个角色在一个单独的Docker容器中运行。输入、存储和输出形成系统的数据平面。控制器和前端控制平面功能和元数据操作。
控制器
控制器是最好的协调器,它具备协调所有其他组件的智能。它主要确定何时创建和在哪里放置(对于哪个输入和哪些存储主机)区段。它还确定哪些输出主机处理使用者组的消耗。
所有数据平面角色通过RPC调用向控制器报告负载信息。有了这个信息,控制器做出放置决定和平衡负载。有几个这种控制器角色的实例。Ringpop还执行分布式健康检查和隶属功能。
前端
前端主机公开 TChannel – Thrift API,执行队列和消费者组的 GRUD 操作。它们还公开用于数据平面路由的API。当生产者想要将消息发布到队列中时,它调用路由API来发现哪些输入主机包含队列的区段。接下来,生产者使用WebSocket连接连接到那些输入主机,并在已建立的流中发布消息。
类似地,当消费者想从队列消费消息时,它首先调用路由API来发现哪些输出主机管理队列的区段的消费。然后,生产者使用WebSocket连接到那些输出主机,并提取消息。创建新区段时,Cherami会向生产者和使用者发送通知,以便它们可以连接到新区段。我们开发了客户端库,使得这些交互得以简化。
Cassandra和排队
最后,Cherami将元数据存储在 Cassandra 上,这是单独部署的。元数据包含关于队列,所有其区段以及所有消费者组信息的信息,例如每个消费者组每个区段的ACK偏移量。我们选择Cassandra不仅因为Cassandra是一个高度可用的数据存储系统,而且还因为它的可调谐一致性模型。这种灵活性允许我们在这样的分区事件期间提供可以是分区容忍的而不是顺序保留(AP队列)或者顺序保留(CP队列)但在次分区中不可用的队列。两种类型的队列的处理的主要区别是,区段创建是否需要条件更新操作。
AP队列
对于AP队列,创建区段不需要Cassandra中的仲裁级一致性。当发生网络分区时,可以在分区的两侧创建区段。让我们调用分区A和B。分区A中的生产者可以发布到该分区中的区段,而分区B中的生产者可以发布到分区B中的区段。因此,写入不会被网络分区阻塞。对于读取,分区A中的消费者只能使用该分区中的区段,并且分区B中的消费者也是如此。不过,当网络分区恢复时,消费者能够访问所有的区段。这里的代价是消息最终是一致的:不可能建立消息的全局排序,因为可以随时随地创建区段。在我们的实现中,当我们写入区段元数据时,我们使用Cassandra一致性级别“ONE”。
CP队列
对于CP队列,区段创建需要是可线性化的:在网络分区的情况下,我们必须确保只有一个分区可以创建一个区段以来继承先前密封的区段。为了确保这一点,我们使用Cassandra的轻量级事务,以便如果同时由于任何原因创建了多个区段,则只有一个可以用于CP队列。
Cherami的总结
Cherami是一个竞争消费者消息队列,具有持久性、容错性、高可用性和可扩展性。我们通过在存储主机之间复制消息来实现持久性和容错性,并通过利用消息队列的仅附加属性和选择最终一致性作为我们的基本模型来实现高可用性。Cherami也是可扩展的,因为设计没有单一的瓶颈。
Cherami是 Uber Engineering西雅图办公室 耗费半年从零开始进行设计并构建的。目前,每天Cherami在Uber Engineering的 许多微服务 中持续传输数亿个任务,应用于这些用例:旅程后处理、欺诈检测、用户通知、激励活动和许多其他用例。
Cherami完全 用Go语言编写 ,这种语言使得构建高性能和并发系统软件变得很有趣。此外,Cherami使用Uber已经开源的几个库:用于RPC的 TChannel 和用于健康检查和组成员资格的 Ringpop 。Cherami依赖于多种第三方开源技术: Cassandra 用于元数据存储,RocksDB用于消息存储,以及GitHub上提供的许多其他第三方Go软件包。我们计划在不久的将来 开源 Cherami。
感谢陈兴璐对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

