利用R语言对用户进行深度挖掘
作者简介:谢佳标
乐逗游戏高级数据分析师,负责大数据挖掘及可视化。资深R语言用户,有九年以上数据挖掘工作实战经验,多次在中国R语言大会上作主题演讲。与张良均老师、杨坦老师合著的《R语言与数据挖掘》一书已在2016年7月出版,新书《R语言游戏数据分析》一书也即将于2017年初出版。
随着游戏市场竞争的日趋激烈,在如何获得更大收益延长游戏周期的问题上,越来越多的手机游戏开发公司开始选择借助大数据,以便挖掘更多更细的用户群、了解用户习惯来进行精细化、个性化的运营。游戏行业对用户的深度挖掘一般从两方面着手:
- 一方面是用户游戏行为的深度分析,如玩家在游戏中的点击事件行为挖掘,譬如说新手教程中的点击事件,我们一般选择最关心的点击事件(即关键路径)进行转化率的分析(统计每个关键路径的点击人数或次数),通过漏斗图的展现形式就可以直接看出每个关键路径的流失和转化情况。漏斗图适合于单路径转化问题,如果涉及到多路径(点击完一个按钮后有多个按钮同时提供选择)情况时,可以使用路径分析的方法,路径分析更加基础、更加全面、更加丰富、更能真实再现玩家在游戏中的行为轨迹。
- 另一方面是对用户付费行为的深度挖掘。付费用户是直接给公司创造价值的核心用户群,通过研究这批用户的付费数据,把脉其付费特征,可以实现精准推送,有效付费转化率。
Part 1:路径分析
总体来说,路径分析有以下一些典型的应用场景:

可以根据不同的应用场景选择不同的算法实现,比如利用sunburst事件路径图对玩家典型的、频繁的模式识别,利用基于时序的关联规则发现前后路径的关系。
最朴素遍历法是直接对主要路径的流向分析,因此最直观和最容易让人理解。
1)当用户行为路径比较复杂的时候,我们可以借助当前最流行的数据可视化D3.js库中的Sunburst Partition来刻画用户群体的事件路径点击状况。从该图的圆心出发,层层向外推进,代表了用户从开始使用产品到离开的整个行为统计;sunburst事件路径图可以快速定位用户的主流使用路径。灵活使用sunburst路径统计图,是我们在路径分析中的一大法宝。
在R中,我们可以利用sunburstR包中的sunburst函数实现sunburst事件路径图,通过install.packages(“sunburstR”)命令完成安装。
我们以sunburstR包中自带的visit-sequences.csv数据集为例进行演示,用sunburst函数绘制sunburst事件路径图。
# sunburst事件路径图
# 加载sunburstR包
library(sunburstR)
# 导入sequences数据
sequences <- read.csv(
system.file("examples/visit-sequences.csv",package="sunburstR")
,header = FALSE
,stringsAsFactors = FALSE
)
# 查看前六行
head(sequences)
## V1 V2 ## 1 account-account-account-account-account-account 22781 ## 2 account-account-account-account-account-end 3311 ## 3 account-account-account-account-account-home 906 ## 4 account-account-account-account-account-other 1156 ## 5 account-account-account-account-account-product 5969 ## 6 account-account-account-account-account-search 692
# 绘制sunburst事件路径图 sunburst(sequences)
可见,当我们选中某条路径时,其他路径颜色变暗,圆圈中的数字表示选中路径的人数(或次数)在总人数(或次数)的占比。右上角是图例,不同颜色代表不同的点击事件。左上角是我们选中的事件路径流向。
2)我们可以利用基于时序的关联规则来研究玩家的点击情况。目的是想找出玩家点击玩牌前一部分的点击情况。在R中,可以使用arulesSequences包中的核心函数cspade实现。此分析的关键是如何将普通数据集转换成模型能识别的事务型数据集。
棋牌游戏玩家从进入游戏到玩牌的点击路径是:欢迎界面操作,大厅界面点击操作,进入房间玩牌。

现在统计某个周期内该款棋牌游戏的玩家点击事件数据,先查看前六行情况:
## V1 V2 V3 ## 1 1 1 11008 ## 2 1 2 11001 ## 3 1 3 11034 ## 4 1 4 11002 ## 5 2 1 11017 ## 6 2 2 11004
第一列是玩家id,第二列是玩家点击按钮的顺序,第三列是点击事件ID(其中11034表示点击开始玩牌按钮,其他ID表示点击“个人信息”、“房间列表”、“好友列表”、“halltool”四大板块的按钮)。接下来,我们可以利用as函数将数据类型转换成事务型数据,结果如下所示:
## transactions in sparse format with ## 24338 transactions (rows) and ## 250 items (columns)
## items transactionID sequenceID eventID
## [1] {click=11008} 1 1 1
## [2] {click=11001} 2 1 2
## [3] {click=11034} 3 1 3
## [4] {click=11002} 4 1 4
## [5] {click=11017} 5 2 1
## [6] {click=11004} 6 2 2
利用arulesSequences包中的cspade函数实现cSPADE算法。由于要找出所有到达开始打牌的路径,所以将支持度阈值support设置为0,且欲返回点击开始打牌和前一次的点击事件,即返回序列的数据项数最大为2,所以maxlen被设置为2。
然后使用sort函数将myrules按照支持度的数值进行降序排序,并设置规则表达式,筛选出序列中最后一个数据项为{click=11034}的序列。
# 利用arulesSquences包中的cspade函数实现cSPADE算法
myrules <- cspade(data_click_tran,parameter=list(support=0,maxlen=2),
control=list(verbose=TRUE))
## ## parameter specification: ## support : 0 ## maxsize : 10 ## maxlen : 2 ## ## algorithmic control: ## bfstype : FALSE ## verbose : TRUE ## summary : FALSE ## tidLists : FALSE ## ## preprocessing ... 1 partition(s), 0.56 MB [0.08s] ## mining transactions ... 0.16 MB [0.13s] ## reading sequences ... [0.57s] ## ## total elapsed time: 0.78s
myrules <- sort(myrules,by="support") # 按照support进行排序
targetclick <- paste0(".*click=11034","[^//}]*//}>") # 设置规则表达式
finalrules <-myrules[grep(targetclick ,as(myrules,"data.frame")$sequence)]
inspect(finalrules[1:3]); # 查看序列的前三条
## items support
## 1 <{click=11034}> 1.0000000
## 2 <{click=11008},
## {click=11034}> 0.6791511
## 3 <{click=11017},
## {click=11034}> 0.2769455
##
序列2中的<{click=11008},{click=11034}>表示点击行为顺序是从11008(从新手场进入玩牌房间)到11034(开始玩牌),支持度为0.679。
最后,筛选关键点击按钮,衡量其对11034的贡献度。首先计算各点击事件支持度的百分比,并使用cumsum()函数计算支持度support的累计百分比,并把累计百分比达到75%以上的点击事件作为引导用户点击玩牌11034的重要事件触发点。并利用recharts包的echartr函数绘制垂直的金字塔图。
# 绘制支持度占比的垂直金子塔图
library(reshape)
md <- melt(result,id="click") # 对result数据进行重组
md$value[md$variable == "conf"] <- -md$value[md$variable == "conf"]/3
md <- md[order(md$variable,decreasing=T),] # 按照variable变量进行降序排序
# 绘制垂直金字塔图
library(recharts)
echartr(md,click,value,variable,type="vbar",subtype="stack") %>%
setTitle("引导用户进入开始打牌11034的重点事件id分析") %>%
setXAxis(axisLine=list(onZero=TRUE)) %>%
setYAxis(axisLabel=list(
formatter=JS('function (value) {return Math.abs(value);}')))
主要结论:11008是为按钮11034的点击贡献最大的引流按钮,support占比为19.5%,接近全部引流按钮的五分之一。
Part 2:付费用户深度挖掘
针对游戏付费用户常用的深度挖掘手段如下图所示:
LTV预测法是根据玩家的前期付费能力预测未来一段时间的用户生命周期价值,这在市场做广告投放时候有很大的参考意义。玩家物品购买的关联分析和社群发现,可以发现不同物品间的关系,从而可以进行物品捆绑销售策略的建议。基于玩家物品的智能推荐是利用物品的协同过滤方法对每一个玩家的购物可能进行推荐,从而实现个性化推荐,这个在现在的电商、互联网是非常流行的做法。
从数据库中导出一份关于玩家物品购买数据,包括用户id、商品名称和购买数量三个变量。前六行如下:
## player_id product_name qty ## 1 107204535 感恩大礼包 1 ## 2 107204535 新手礼包 1 ## 3 213666611 8条钥匙 1 ## 4 226500629 0.1元大礼包 1 ## 5 226500629 8条钥匙 1 ## 6 226500629 限量版角色 1
1)现在,希望利用arules包中的apriori算法对上面的数据进行关联规则发现。此时,需要把数据转化成事务型数据。代码如下:
# 利用cast函数对数据进行重组 library(reshape) data_matrix <- cast(data,player_id~product_name)
## Using qty as value column. Use the value argument to cast to override this choice
# 查看前三行五列数据 data_matrix[1:3,1:5]
## player_id 0.1元大礼包 10块滑板 15000金币 15元大礼包 ## 1 107204535 NA NA NA NA ## 2 213666611 NA NA NA NA ## 3 226500629 1 NA NA NA
# 进行替换,将NA转化为0,其他数字为1
data_matrix_new <- apply(data_matrix[,-1],2,function(x) {ifelse(is.na(x),0,1)})
# 对矩阵行名称、列名称进行赋值
data_matrix_new <- matrix(data_matrix_new,nrow=dim(data_matrix_new)[1],
ncol=dim(data_matrix_new)[2],
dimnames = list(data_matrix[,1],colnames(data_matrix)[-1]))
# 查看前三行五列数据
data_matrix_new[1:3,1:5]
## 0.1元大礼包 10块滑板 15000金币 15元大礼包 1条钥匙 ## 107204535 0 0 0 0 0 ## 213666611 0 0 0 0 0 ## 226500629 1 0 0 0 0
# 利用as函数将矩阵转换成事务型 library(arules) data_class <- as(data_matrix_new,"transactions") inspect(data_class[1:6]) # 查看前六条交易记录
## items transactionID
## [1] {感恩大礼包,新手礼包} 107204535
## [2] {8条钥匙} 213666611
## [3] {0.1元大礼包,8条钥匙,限量版角色} 226500629
## [4] {38000金币,限量版角色,新手礼包} 230329140
## [5] {50条钥匙} 264162836
## [6] {15000金币,70000金币,快速复活} 278620434
现在,可以利用aurles进行关联规则分析和利用aurlesViz包进行规则可视化。
# 建立关联规则rules library(arules) rules <- apriori(data_class,parameter=list(support=0.005,confidence=0.1,minlen=2,target="rules"))
## Apriori ## ## Parameter specification: ## confidence minval smax arem aval originalSupport maxtime support minlen ## 0.1 0.1 1 none FALSE TRUE 5 0.005 2 ## maxlen target ext ## 10 rules FALSE ## ## Algorithmic control: ## filter tree heap memopt load sort verbose ## 0.1 TRUE TRUE FALSE TRUE 2 TRUE ## ## Absolute minimum support count: 31 ## ## set item appearances ...[0 item(s)] done [0.00s]. ## set transactions ...[26 item(s), 6252 transaction(s)] done [0.00s]. ## sorting and recoding items ... [21 item(s)] done [0.00s]. ## creating transaction tree ... done [0.00s]. ## checking subsets of size 1 2 3 done [0.00s]. ## writing ... [48 rule(s)] done [0.00s]. ## creating S4 object ... done [0.00s].
# 对关联规则进行可视化 rules_lift <- subset(rules,subset=lift>2) library(arulesViz) plot(rules_lift,method="grouped") #绘制分组矩阵
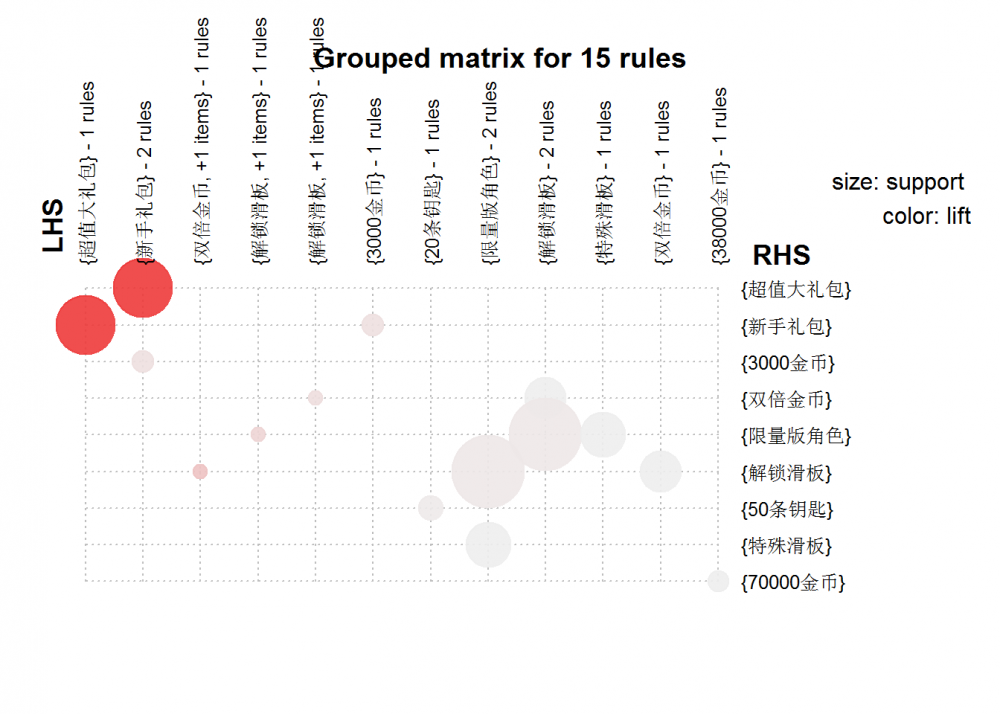
由图可知,{超值大礼包} & {新手礼包}说明这两条规则的提升度最大;{解锁滑板} & {限量版角色}圆圈最大,说明这两条规则的支持度最大。
2)最后,让我们用recommenderlab对玩家购买道具进行智能推荐。在构建模型之前,我们需要将数据转换为评分矩阵。
library(recommenderlab) # 将矩阵转化为binaryRatingMatrix对象 data_class <- as(data_matrix_new,"binaryRatingMatrix") as(data_class,"matrix")[1:3,1:5] #显示部分物品购买情况
## 0.1元大礼包 10块滑板 15000金币 15元大礼包 1条钥匙 ## 107204535 FALSE FALSE FALSE FALSE FALSE ## 213666611 FALSE FALSE FALSE FALSE FALSE ## 226500629 TRUE FALSE FALSE FALSE FALSE
选择IBCF建立推荐模型,对玩家进行top3推荐。
#选择IBCF作为最优模型 model.best <- Recommender(data_class,method="IBCF") # 使用precict函数,对玩家进行Top3推荐 data.predict <- predict(model.best,newdata=data_class,n=5) recom3 <- bestN(data.predict,3) as(recom3,"list")[1:5] #查看前五个玩家的top3推荐
## $`107204535` ## [1] "超值大礼包" "3000金币" "超级大礼包" ## ## $`213666611` ## [1] "15000金币" "20条钥匙" ## ## $`226500629` ## [1] "解锁滑板" "双倍金币" "特殊滑板" ## ## $`230329140` ## [1] "超值大礼包" "解锁滑板" "双倍金币" ## ## $`264162836` ## [1] "70000金币" "20条钥匙" "15000金币"
从上面的分享可知,我们在做数据分析建模之前,数据转化处于非常重要的地位。如何把原始数据转化成模型可以识别的数据,需要大家平时的经验积累。以上内容是在第九届中国R语言会议的分享内容。也是明年初将要出版的《R语言游戏数据分析》一书关于用户分析的部分内容。
审稿 | 何通
编辑 | 范超
版权公告
原创文章,版权所有。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name ),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都二维码。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

