人工智能硬件不能遗忘的4S机遇
2017 年 1 月 11 日至 12 日,首届 AI Frontier 大会在加州硅谷 Santa Clara 召开。主办方 Silicon Valley AI and Big Data Association 邀请 Google Brain 负责人 Jeff Dean,Microsoft 人工智能首席科学家 Li Deng,Amazon Alexa 首席科学家 Nikko Storm,Facebook-Caffe 创始人 Yangqing Jia 等人工智能专家以及多家人工智能初创公司展开热烈的讨论。矽说 携手 机器之心,进驻湾区硅谷核心区域,发回了「独家」场记。
十年前,初创公司都是 e 开头的
那是互联网的时代
五年前,初创公司都是 i 开头的
那是移动终端的时代
今年,初创公司都是 N 开头的
那是人工智能的时代
N 是什么?
Neural Network
身处人工智能大潮,矽说在过去的一段时间在人工智能硬件领域,携手机器之心,多次发表评论及《脑芯编》系列。今天,在观摩了 AI frontier 后,矽说小编再次指点江山,人工智能硬件发展过程中容易被忽略的四大决胜关键趋势。(个人观点,仅供参考)
Scalable 规模化扩展
几乎每一个讲者都会提及 Scalablity,从框架到实现。无论是 Tensorflow 还是 Caffe,各个框架平台都需要考虑面向不同硬件运行深度学习网络的完整性、一致性。而那些对于需要实现成实际产品的工程,比如自动驾驶(Google Waymo 等)、语音助手(Amazon Alexa 等),高效的选择硬件规模更是一个需要攻关的主要难题。可规模化扩展的能力 (Scalable)成为每个能广为使用的人工智能实现的铲平必须具备的特性。




Reference: Y. Jia, Caffe Talk
其实,归根结底,Scalabe 是因为硬件总是有限的。过去几年,人工智能网络已经从 AlexNet、VGG-19 的浅层网络的迅速成长成超深层的 ResNet,以及多个网络相辅相成的生成对抗式网络(Generative Adversarial Network)。虽然,以 NVdia 为首的硬件公司也在不断突破,但是其增长速度恐怕无法与目前的神经网络相媲美。
因此,对于每一个深度学习神经网络的实现,在每一个层次实现时,除了计算的高效性外,将大规模网络裂解(partition)并且映射(mapping)到有限的硬件上就成为了一个踏踏实实的问题。表现在接口设计、数据结构的选择等各个层次。而只有那些可以规模化扩展的人工智能硬件,才能在算法日新月异的今天立于不败之地。
Sensable 传感,也要智能
如果你还觉得传感器和人工智能计算是两个完全独立的模块的,恭喜你,你已经被时代抛弃了。大会上,北京文安与 Bosch 都秀出了新一代的图像传感/VR 传感器。毫无例外的,人工智能算法已经与传感器拥抱,同时出现在前端。
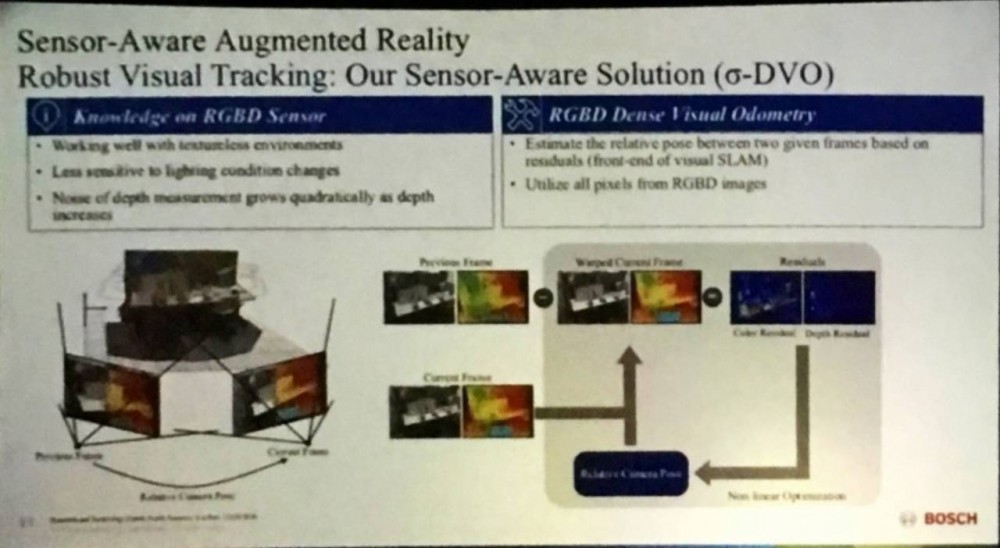
Reference: R. Liu, Bosch Sensor Talk
传感器,作为实时推理(Real-time Inference)的最前端,是模拟信号与数字化的人工智能算法间的桥梁。他可以是摄像头,可以是 lidar/radar,可以是音频,林林总总。当信号越原始,越早地进入神经网络处理,他就越容易带来意想不到的效果。紧密拥抱传感器的 AI 算法已经在 end-to-end Learning 领域迸发出了不一样的火花。未来的人工智能硬件,将不可逆地与传感器结合,成为 IoT 时代的大趋势。
Sythesizable 综和再生,机器变成人
每天醒来,你唤的第一个名字叫做 Alexa,每天睡去,最后一声念叨的是 Siri,基于人工智能的语音综合(speech synthesis)已经成为了我们生活中不可缺少的一部分。甚至,未来的骚扰、诈骗电话都会用到 AI Sythesize 技术。
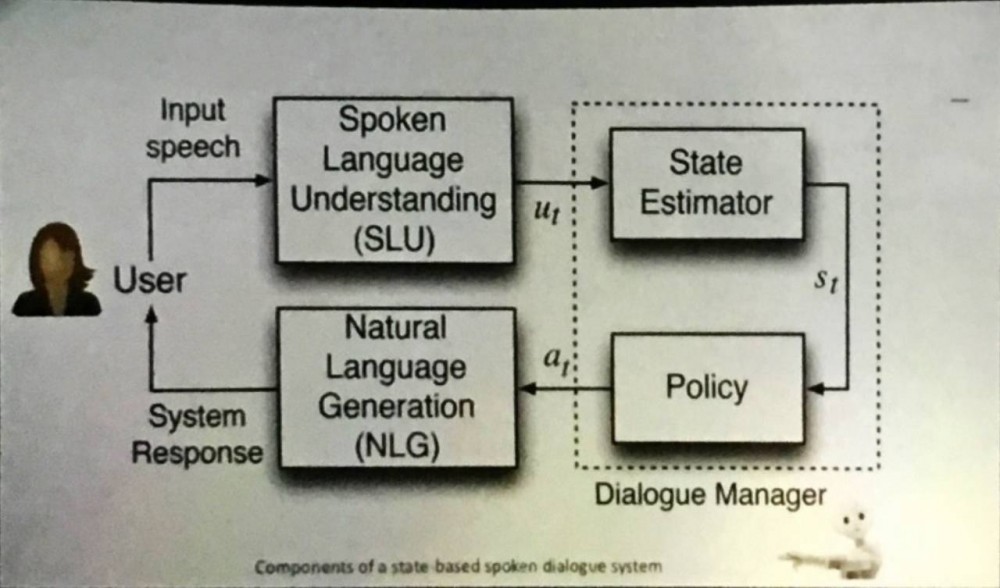 Reference: L. Deng, Microsoft Chatbot Talk
Reference: L. Deng, Microsoft Chatbot Talk
可以被综合的难道仅仅是语音么?Chatbot 们已经学会用自然语言调戏人类,新一代美颜滤镜会造出以一个个印象派的蒙娜丽莎,自动驾驶的车辆们,直接生成方向盘指令。基于 Policy Evaluation 的增强学习(Reinforcement Learning)已经革多少人的命?更勿论,生成对抗学习的大 boss 已经磨刀霍霍向猪羊。
所以硬件创业者们,classification/inference 的年代早已随岁月顺水流,未来的硬件的机遇已经超越了理解人类的范畴。这将是一个机器能与人沟通的年代。以综合(synthesis)为目标的人工智能硬件正向我们走来。
Savable 从头开始,你就输了
总是改变生态的 G 家大神总在你意想不到的给大家送福利。比如正式出版的 Tensorflow 1.0 提供了不少基于图片识别的预训练(pre-trained)网络,基于 Inception 结构。对于很多智能开发者而言,只需要根据实际情况,对最后一到两层的全链接(Fully connected layer)训练下,就能达到玩美智能的效果。高效、省时、省力、省硬件。
同样的故事发生在 Baidu 和 Amazon 的语音识别系统中。大家不约而同的发现,对于不同语言的识别系统,其实只要训练输出层(output layer)就能得到相近的结果。而省去 RNN/CNN 层训练就好像是时间的馈赠,来自上天的礼物。
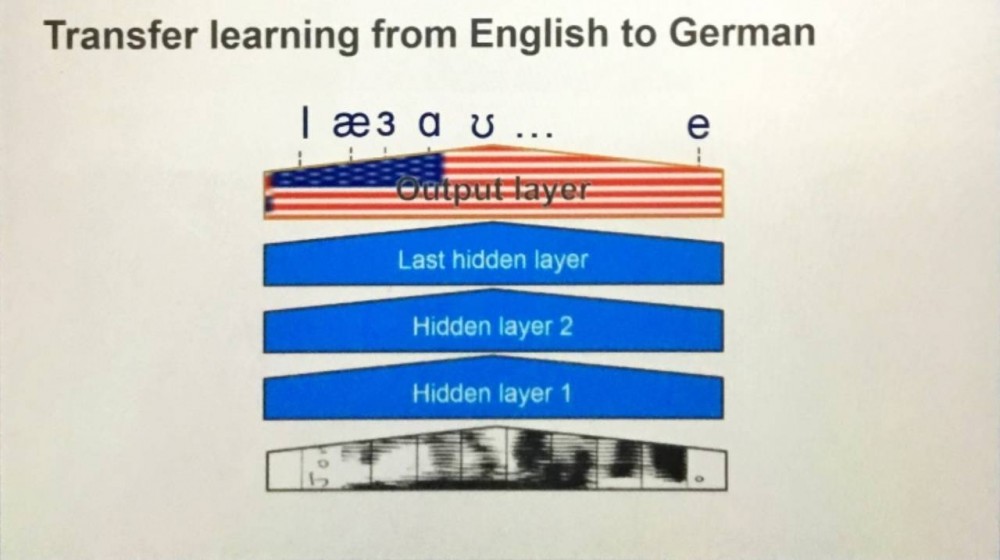
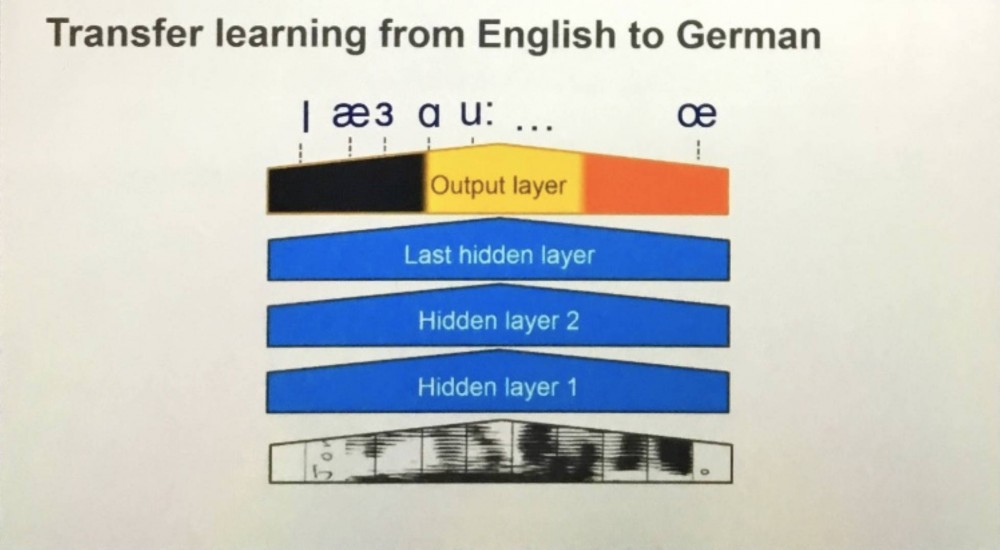
Reference: N. Storm, Amazon Alexa Talk
这样的馈赠何尝只是算法层面的专属?首先,可节省(savable)的实现方法让硬件在合理安排存储空间和可配置维度上带来的新的启示。同时,若硬件的可重复使用率提升到了新的高度,那将对云端/终端的 AI 计算资源配置比关系提出一轮新的思考与挑战。其次,面向成熟体系框架 framework 的硬件,对于客户和使用者来说,本身就是一种节省。如果有合适的 scalable 接口和 complier,在 inference 端的映射也将朝向更简约、更低门槛的方式前进。只有充分体会到这一点,完善与框架的接口的设计,才终将改变 AI 硬件的大潮流。
总结:感谢 AI frontier,让小编能从一个更宏观的角度去仰视人工智能算法的大趋势,也凝练四大智能硬件的重要关键——Scalable,Sensable, Synthesizable and Savable。最后,预祝第二届 AI Frontier 顺利召开。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

