Swift 中的指针操作
默认情况下,Swift 是内存安全的,这意味着它禁止我们直接操作内存,并且确保所有的变量在使用前都已经被正确地初始化了。但是,Swift 也提供了我们使用指针直接操作内存的方法,直接操作内存是很危险的行为,很容易就出现错误,因此官方将直接操作内存称为 “unsafe 特性”。
一旦我们开始直接操作内存,一切就得靠我们自己了,因为在这种情况下编译能给我们提供的帮助实在不多。正常情况下,我们在与 C 进行交互,或者我们需要挖掘 Swift 内部实现原理的时候会需要使用到这个特性。
Memory Layout
Swift 提供了 MemoryLayout 来检测特定类型的大小以及内存对齐大小:
MemoryLayout<Int>.size // return 8 (on 64-bit) MemoryLayout<Int>.alignment // return 8 (on 64-bit) MemoryLayout<Int>.stride // return 8 (on 64-bit) MemoryLayout<Int16>.size // return 2 MemoryLayout<Int16>.alignment // return 2 MemoryLayout<Int16>.stride // return 2 MemoryLayout<Bool>.size // return 2 MemoryLayout<Bool>.alignment // return 2 MemoryLayout<Bool>.stride // return 2 MemoryLayout<Float>.size // return 4 MemoryLayout<Float>.size // return 4 MemoryLayout<Float>.alignment // return 4 MemoryLayout<Double>.stride // return 8 MemoryLayout<Double>.alignment // return 8 MemoryLayout<Double>.stride // return 8
MemoryLayout<Type> 是一个用于在编译时计算出特定类型(Type)的 size, alignment 以及 stride 的泛型类型。返回的数值以字节为单位。例如 Int16 类型的大小为 2 个字节,内存对齐为 2 个字节以及当我们需要连续排列多个 Int16 类型时,每一个 Int16 所需要占用的大小(stride)为 2 个字节。所有基本类型的 stride 都与 size 是一致的。
接下来,看看结构体类型的 MemoryLayout:
structEmptyStruct{}
MemoryLayout<EmptyStruct>.size // returns 0
MemoryLayout<EmptyStruct>.alignment // returns 1
MemoryLayout<EmptyStruct>.stride // returns 1
structSampleStruct{
let number: UInt32
let flag: Bool
}
MemoryLayout<SampleStruct>.size // returns 5
MemoryLayout<SampleStruct>.alignment // returns 4
MemoryLayout<SampleStruct>.stride // returns 8
空结构体的大小为 0,内存对齐为 1, 表明它可以存在于任何一个内存地址上。有趣的是 stride 为 1,这是因为尽管结构为空,但是当我们使用它创建一个实例的时候,它也必须要有一个唯一的地址。
对于 SampleStruct ,它所占的大小为 5,但是 stride 为 8。这是因为编译需要为其填充空白的边界,使其符合它的 4 字节内存边界对齐。
再来看看类:
classEmptyClass{}
MemoryLayout<EmptyClass>.size // returns 8 (on 64-bit)
MemoryLayout<EmptyClass>.alignment // returns 8 (on 64-bit)
MemoryLayout<EmptyClass>.stride // returns 8 (on 64-bit)
classSampleClass{
let number: Int64 = 0
let flag: Bool = false
}
MemoryLayout<SampleClass>.size // returns 8 (on 64-bit)
MemoryLayout<SampleClass>.aligment // returns 8 (on 64-bit)
MemoryLayout<SampleClass>.stride // returns 8 (on 64-bit)
由于类都是引用类型,所以它所有的大小都是 8 字节。
关于 MemoryLayout 的更多详细信息可以参考 Mike Ash 的演讲 。
指针
一个指针就是对一个内存地址的封装。在 Swift 当中直接操作指针的类型都有一个 “unsafe” 前缀,所以它的指针类型称为 UnsafePointer 。这个前缀似乎看起来很令人恼火,不过这是 Swift 在提醒你,你现在正在跨越雷池,编译器不会对这种操作进行检查,你需要对自己的代码承担全部的责任。
Swift 中包含了一打类型的指针类型,每个类型都有它们的作用和目的,使用适当的指针类型可以防止错误的发生并且更清晰地表达开发者的意图,防止未定义行为的产生。
Swift 的指针类型使用了很清晰的命名,我们可以通过名字知道这是一个什么类型的指针。可变或者不可变,原生(raw)或者有类型的,是否是缓冲(buffer)类型,这三种特性总共组合出了 8 种指针类型。
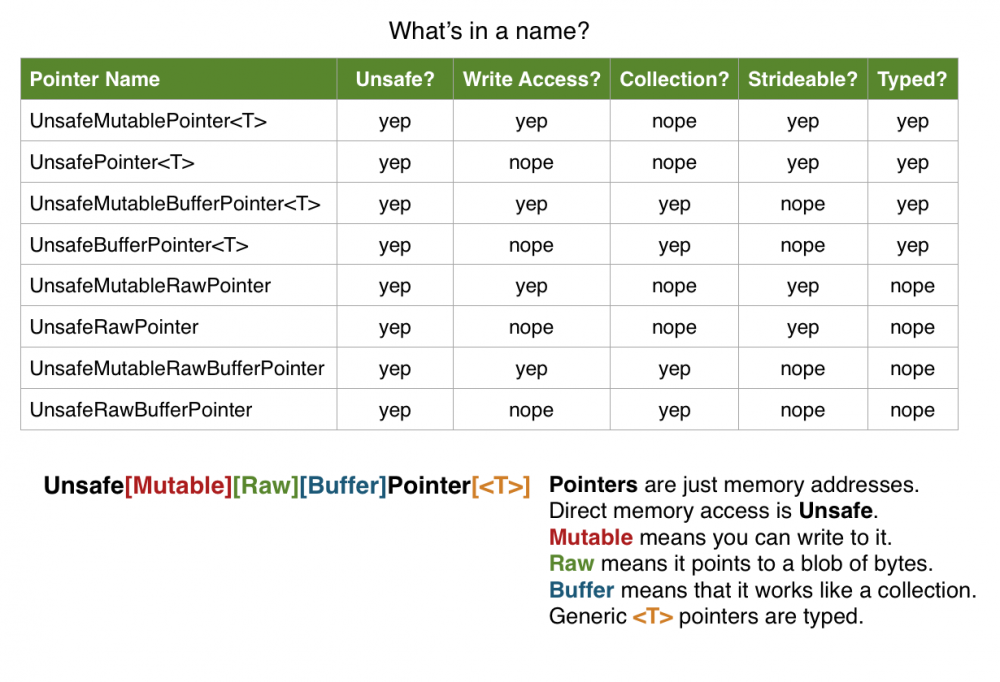
接下来的几个小节会详细介绍这几种指针类型。
使用原生(Raw)指针
在 Playground 中添加如下代码:
// 1
let count = 2
let stride = MemoryLayout<Int>.stride
let alignment = MemoryLayout<Int>.alignment
let byteCount = stride * count
// 2
do {
print("Raw pointers")
// 3
let pointer = UnsafeMutableRawPointer.allocate(bytes: byteCount, alignedTo: alignment)
// 4
defer {
pointer.deallocate(bytes: byteCount, alignedTo: alignment)
}
// 5
pointer.storeBytes(of: 42, as: Int.self)
pointer.advanced(by: stride).storeBytes(of: 6, as: Int.self)
pointer.load(as: Int.self)
pointer.advanced(by: stride).load(as: Int.self)
// 6
let bufferPointer = UnsafeRawBufferPointer(start: pointer, count: byteCount)
for (index, byte) in bufferPointer.enumerated() {
print("byte /(index): /(byte)")
}
}
在这个代码段中,我们使用了 Unsafe Swift 指针去存储和读取两个整型数值。接下来是对这段代码的解释:
- 声明了接下来都会用到的几个常量:
-
count表示了我们要存储的整数的个数 -
stride表示了 Int 类型的 stride -
alignment表示了 Int 类型的内存对齐 -
byteCount表示占用的全部字节数
-
- 使用
do来增加一个作用域,让我们可以在接下的示例中复用作用域中的变量名 - 使用
UnsafeMutableRawPointer.allocate方法来分配所需的字节数。我们使用了 UnsafeMutableRawPointer,它的名字表明这个指针可以用来读取和存储(改变)原生的字节。 - 使用 defer 来保证内存得到正确地释放。操作指针的时候,所有内存都需要我们手动进行管理。
-
storeBytes和load方法用于存储和读取字节。第二个整型数值的地址通过对 pointer 的地址前进 stride 来得到。因为指针类型是Strideable的,我们也可以直接使用指针算术运算(pointer+stride).storeBytes(of: 6, as: Int.self)。 -
UnsafeRawBufferPointer类型以一系列字节的形式来读取内存。这意味着我们可以这些字节进行迭代,对其使用下标,或者使用filter,map以及reduce这些很酷的方法。缓冲类型指针使用了原生指针进行初始化。
使用类型指针
我们可以使用类型指针实现跟上面代码一样的功能,并且更简单:
do {
print("Typed pointers")
let pointer = UnsafeMutablePointer<Int>.allocate(capacity: count)
pointer.initialize(to: 0, count: count)
defer {
pointer.deinitialize(count: count)
pointer.deallocate(capacity: count)
}
pointer.pointee = 42
pointer.advanced(by: 1).pointee = 6
pointer.pointee
pointer.advanced(by: 1).pointee
let bufferPointer = UnsafeBufferPointer(start: pointer, count: count)
for (index, value) in bufferPointer.enumerated() {
print("value /(index): /(value)")
}
}
注意到以下几点不同:
- 我们使用了 UnsafeMutablePointer.allocate 进行内存的分配。指定的泛型参数让 Swift 知道我们将会使用这个指针来存储和读取 Int 类型的值。
- 在使用类型指针前需要对其进行初始化,并在使用后销毁。这两个功能分别是使用 initialize 和 deinitialize 方法。
- 类型指针提供了
pointee属性,它可以以类型安全的方式读取和存储值。 - 当需要指针前进的时候,我们只需要指定想要前进的个数。类型指针会自动根据它所指向的数值类型来计算 stride 值。同样的,我们可以直接对指针进行算术运算
(pointer + 1).pointee = 6。 - 有类型的缓冲型指针也会直接操作数值,而非字节
将原生指针转换为类型指针
类型指针并不总是使用初始化得到的,它们可以从原生指针中转化而来。
在 Playground 中添加如下代码:
do {
print("Converting raw pointers to typed pointers")
let rawPointer = UnsafeMutableRawPointer.allocate(bytes: byteCount, alignedTo: alignment)
defer {
rawPointer.deallocate(bytes: byteCount, alignedTo: alignment)
}
let typedPointer = rawPointer.bindMemory(to: Int.self, capacity: count)
typedPointer.initialize(to: 0, count: count)
defer {
typedPointer.deinitialize(count: count)
}
typedPointer.pointee = 42
typedPointer.advanced(by: 1).pointee = 6
typedPointer.pointee
typedPointer.advanced(by: 1).pointee
let bufferPointer = UnsafeBufferPointer(start: typedPointer, count: count)
for (index, value) in bufferPointer.enumerated() {
print("value /(index): /(value)")
}
}
这段代码与上一段类似,除了它先创建了原生指针。我们通过将内存 绑定(binding) 到指定的类型上来创建类型指针。通过对内存的绑定,我们可以通过类型安全的方法来访问它。将我们手动创建类型指针的时候,系统其实自动帮我们进行了内存绑定。
获取一个实例的字节
很多时候我们需要从一个现存的实例里获取它的字节。这时可以使用 withUnsafeBytes(of:) 方法。
在 Playground 中添加如下代码:
do {
print("Getting the bytes of an instance")
var sampleStruct = SampleStruct(number: 25, flag: true)
withUnsafeBytes(of: &sampleStruct) { bytes in
for byte in bytes {
print(byte)
}
}
}
这段代码会打印出 SampleStruct 实例的原生字节。 withUnsafeBytes(of:) 方法可以获取到 UnsafeRawBufferPointer 并传入闭包中供我们使用。
withUnsafeBytes 同样适合用 Array 和 Data 的实例。
使用 Swift 操作指针的三大原则
当我们使用 Swift 操作指针的时候必须加倍小心,防止写出未定义行为的代码。下面是几个坏代码的示例。
不要从 withUnsafeBytes 中返回指针
// Rule #1
do {
print("1. Don't return the pointer from withUnsafeBytes!")
var sampleStruct = SampleStruct(number: 25, flag: true)
let bytes = withUnsafeBytes(of: &sampleStruct) { bytes in
return bytes // strange bugs here we come ☠️☠️☠️
}
print("Horse is out of the barn!", bytes) /// undefined !!!
}
绝对不要让指针逃出 withUnsafeBytes(of:) 的作用域范围。这样的代码会成为定时炸弹,你永远不知道它什么时候可以用,而什么时候会崩溃。
一次只绑定一种类型
// Rule #2
do {
print("2. Only bind to one type at a time!")
let count = 3
let stride = MemoryLayout<Int16>.stride
let alignment = MemoryLayout<Int16>.alignment
let byteCount = count * stride
let pointer = UnsafeMutableRawPointer.allocate(bytes: byteCount, alignedTo: alignment)
let typedPointer1 = pointer.bindMemory(to: UInt16.self, capacity: count)
// Breakin' the Law... Breakin' the Law (Undefined behavior)
let typedPointer2 = pointer.bindMemory(to: Bool.self, capacity: count * 2)
// If you must, do it this way:
typedPointer1.withMemoryRebound(to: Bool.self, capacity: count * 2) {
(boolPointer: UnsafeMutablePointer<Bool>) in
print(boolPointer.pointee) // See Rule #1, don't return the pointer
}
}
**绝对不要**让一个内存同时绑定两个不同的类型。如果你需要临时这么做,可以使用 `withMemoryRebound(to:capacity:)` 来对内存进行重新绑定。并且,这条规则也表明了不要将一个基本类型(如 Int)重新绑定到一个自定义类型(如 class)上。不要做这种傻事。
### 不要操作超出范围的内存
```swift
// Rule #3... wait
do {
print("3. Don't walk off the end... whoops!")
let count = 3
let stride = MemoryLayout<Int16>.stride
let alignment = MemoryLayout<Int16>.alignment
let byteCount = count * stride
let pointer = UnsafeMutableRawPointer.allocate(bytes: byteCount, alignedTo: alignment)
let bufferPointer = UnsafeRawBufferPointer(start: pointer, count: byteCount + 1) // OMG +1????
for byte in bufferPointer {
print(byte) // pawing through memory like an animal
}
}
这是最糟糕的一种错误了,请再三检查你的代码,保证不要有这种情况出现。切记。
示例:随机数生成
随机数在很多地方都有重要的作用,从游戏到机器学习。macOS 提供了 arc4random 方法用于随机数生成。不幸的是,这个方法无法在 Linux 上使用。并且, arc4random 方法只提供了 UInt32 类型的随机数。事实上, /dev/urandom 这个设备文件中就提供了无限的随机数。
这一小节中,我们将使用指针读取这个文件,并产生完全类型安全的随机数。
创建一个新 Playground,命名为 RandomNumbers ,并确保选择了 macOS 平台。
创建完成后,添加如下代码:
import Foundation
enumRandomSource{
static let file = fopen("/dev/urandom", "r")!
static let queue = DispatchQueue(label: "random")
static funcget(count: Int) -> [Int8] {
let capacity = count + 1 // fgets adds null termination
var data = UnsafeMutablePointer<Int8>.allocate(capacity: capacity)
defer {
data.deallocate(capacity: capacity)
}
queue.sync {
fgets(data, Int32(capacity), file)
}
return Array(UnsafeMutableBufferPointer(start: data, count: count))
}
}
为了确保整个系统中只存在一个 file 变量,我们对其使用了 static 修饰符。系统会在我们的进程结束时关闭文件。因为我们有可能在多个线程中同时获取随机数,所以需要使用一个串行的 GCD 队列来进行保护。
get 函数是所有功能完成的地方。首先,我们根据传入的大小分配了必要的内存,注意这里需要 +1 是因为 fets 函数总是以 /0 结束。接下来,我们就使用 fgets 函数从文件中读取数据,确保我们在串行队列中进行读取操作。最后,我们先将数据封装为一个 UnsafeMutableBufferPointer ,并将其转化为一个数组。
在 playground 的最后添加如下代码:
extensionInteger{
static var randomized: Self {
let numbers = RandomSource.get(count: MemoryLayout<Self>.size)
return numbers.withUnsafeBufferPointer { bufferPointer in
return bufferPointer.baseAddress!.withMemoryRebound(to: Self.self, capacity: 1) {
return $0.pointee
}
}
}
}
Int8.randomized
UInt8.randomized
Int16.randomized
UInt16.randomized
Int16.randomized
UInt32.randomized
Int64.randomized
UInt64.randomized
这里我们为 Integer 协议添加了一个静态属性,并为其提供了默认实现。我们首先获取了随机数,随后我们将获得字节数组重新绑定为所需要的类型,然后返回它的值。简单!
就这样,我们使用 unsafe Swift 实现了一个类型安全的随机器生成方法。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

