使用Akka构建集群(二)
前言
在《 使用Akka构建集群(一) 》一文中通过简单集群监听器的例子演示了如何使用Akka搭建一个简单的集群,但是这个例子“也许”离我们的实际业务场景太远,你基本不太可能去做这样的工作,除非你负责运维、监控相关的工作(但实际上一个合格的程序员在实现功能的同时,也应当考虑监控的问题,至少应当接入一些监控系统或框架)。
本文将介绍一个相对看来更符合我们对于集群使用的业务需求的例子——将客户端请求的字符串转换为大写(假如客户端真的没有这个能力的话)。
服务端
本文的Akka配置继续沿用《 使用Akka构建集群(一) 》一文中所展示的配置,但在正式编码之前我们需要在配置中增加一个新的配置项akka.cluster.roles指定集群中服务端的角色,重新编辑过后的application.conf如下:
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 2551
}
}
cluster {
seed-nodes = [
"akka.tcp://metadataAkkaSystem@127.0.0.1:2551",
"akka.tcp://metadataAkkaSystem@127.0.0.1:2552"]
#//#snippet
# excluded from snippet
auto-down-unreachable-after = 10s
#//#snippet
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
# auto-down-unreachable-after = 10s
roles = [backend]
# Disable legacy metrics in akka-cluster.
metrics.enabled=off
}
} 你仍然不需要过多产生于集群直接相关的细节。如果你已经阅读了《
使用Akka构建集群(一)
》一文,本文介绍的内容应该不会花费你太多的时间。
客户端与服务端通信需要一些pojo,它们的实现如下:
public interface TransformationMessages {
public static class TransformationJob implements Serializable {
private final String text;
public TransformationJob(String text) {
this.text = text;
}
public String getText() {
return text;
}
}
public static class TransformationResult implements Serializable {
private final String text;
public TransformationResult(String text) {
this.text = text;
}
public String getText() {
return text;
}
@Override
public String toString() {
return "TransformationResult(" + text + ")";
}
}
public static class JobFailed implements Serializable {
private final String reason;
private final TransformationJob job;
public JobFailed(String reason, TransformationJob job) {
this.reason = reason;
this.job = job;
}
public String getReason() {
return reason;
}
public TransformationJob getJob() {
return job;
}
@Override
public String toString() {
return "JobFailed(" + reason + ")";
}
}
public static final String BACKEND_REGISTRATION = "BackendRegistration";
}
TransformationJob代表待转换的任务,其text属性是需要处理的字符串文本;TransformationResult是任务处理的结果,其text属性是转换完成的字符串文本;JobFailed是任务失败,其reason属性代表失败原因;字符串常量BACKEND_REGISTRATION用于服务端向客户端注册,以便于客户端知道有哪些服务端可以提供服务。
服务端用于将字符串转换为大写的Actor(正如我之前的文章所言,真正的处理应当从Actor中分离出去,只少通过接口解耦)的实现见代码清单1所示。
代码清单1
@Named("TransformationBackend")
@Scope("prototype")
public class TransformationBackend extends UntypedActor {
private static Logger logger = LoggerFactory.getLogger(TransformationBackend.class);
Cluster cluster = Cluster.get(getContext().system());
// subscribe to cluster changes, MemberUp
@Override
public void preStart() {
cluster.subscribe(getSelf(), MemberUp.class);
}
// re-subscribe when restart
@Override
public void postStop() {
cluster.unsubscribe(getSelf());
}
@Override
public void onReceive(Object message) {
if (message instanceof TransformationJob) {
TransformationJob job = (TransformationJob) message;
logger.info(job.getText());
getSender().tell(new TransformationResult(job.getText().toUpperCase()), getSelf());
} else if (message instanceof CurrentClusterState) {
CurrentClusterState state = (CurrentClusterState) message;
for (Member member : state.getMembers()) {
if (member.status().equals(MemberStatus.up())) {
register(member);
}
}
} else if (message instanceof MemberUp) {
MemberUp mUp = (MemberUp) message;
register(mUp.member());
} else {
unhandled(message);
}
}
void register(Member member) {
if (member.hasRole("frontend"))
getContext().actorSelection(member.address() + "/user/transformationFrontend").tell(BACKEND_REGISTRATION, getSelf());
}
}
TransformationBackend在preStart方法中订阅了集群的MemberUp事件,这样当它发现新注册的集群成员节点的角色是frontend(前端)时,将向此节点发送BACKEND_REGISTRATION消息,后者将会知道前者提供了服务。TransformationBackend所在的节点在刚刚加入集群时,TransformationBackend还会收到CurrentClusterState消息,从中可以解析出集群中的所有前端节点(即roles为frontend的),并向其发送BACKEND_REGISTRATION消息。经过以上两步可以确保集群中的前端节点和后端节点无论启动或加入集群的顺序怎样变化,都不会影响后端节点通知所有的前端节点及前端节点知道哪些后端节点提供了服务。
客户端
客户端除了监听端口不同外,也需要增加akka.cluster.roles配置项,我们指定为frontend。客户端的配置如下:
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka.tcp://metadataAkkaSystem@127.0.0.1:2551",
"akka.tcp://metadataAkkaSystem@127.0.0.1:2552"]
#//#snippet
# excluded from snippet
auto-down-unreachable-after = 10s
#//#snippet
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
# auto-down-unreachable-after = 10s
roles = [frontend]
}
}
客户端用于处理转换任务的Actor见代码清单2所说。
代码清单2
@Named("TransformationFrontend")
@Scope("prototype")
public class TransformationFrontend extends UntypedActor {
List<ActorRef> backends = new ArrayList<ActorRef>();
int jobCounter = 0;
@Override
public void onReceive(Object message) {
if ((message instanceof TransformationJob) && backends.isEmpty()) {
TransformationJob job = (TransformationJob) message;
getSender().tell(
new JobFailed("Service unavailable, try again later", job),
getSender());
} else if (message instanceof TransformationJob) {
TransformationJob job = (TransformationJob) message;
jobCounter++;
backends.get(jobCounter % backends.size())
.forward(job, getContext());
} else if (message.equals(BACKEND_REGISTRATION)) {
getContext().watch(getSender());
backends.add(getSender());
} else if (message instanceof Terminated) {
Terminated terminated = (Terminated) message;
backends.remove(terminated.getActor());
} else {
unhandled(message);
}
}
}
可以看到TransformationFrontend处理的消息分为以下三种:
- BACKEND_REGISTRATION:收到此消息说明有服务端通知客户端,TransformationFrontend首先将服务端的ActorRef加入backends列表,然后对服务端的ActorRef添加监管;
- Terminated:由于TransformationFrontend对服务端的ActorRef添加了监管,所以当服务端进程奔溃或者重启时,将收到Terminated消息,此时TransformationFrontend将此服务端的ActorRef从backends列表中移除;
- TransformationJob:此消息说明有新的转换任务需要TransformationFrontend处理,处理分两种情况:
- backends列表为空,则向发送此任务的发送者返回JobFailed消息,并告知“目前没有服务端可用,请稍后再试”;
- backends列表不为空,则通过取模运算选出一个服务端,将TransformationJob转发给服务端进一步处理;
运行展示
初始化服务端TransformationBackend的代码如下:
logger.info("Start transformationBackend");
final ActorRef transformationBackend = actorSystem.actorOf(springExt.props("TransformationBackend"), "transformationBackend");
actorMap.put("transformationBackend", transformationBackend);
logger.info("Started transformationBackend"); 初始化客户端TransformationFrontend的代码如下:
logger.info("Start transformationFrontend");
final ActorRef transformationFrontend = actorSystem
.actorOf(springExt.props("TransformationFrontend"), "transformationFrontend");
actorMap.put("transformationFrontend", transformationFrontend);
logger.info("Started transformationFrontend");
final FiniteDuration interval = Duration.create(2, TimeUnit.SECONDS);
final Timeout timeout = new Timeout(Duration.create(5, TimeUnit.SECONDS));
final ExecutionContext ec = actorSystem.dispatcher();
final AtomicInteger counter = new AtomicInteger();
actorSystem.scheduler().schedule(interval, interval, new Runnable() {
public void run() {
ask(transformationFrontend, new TransformationJob("hello-" + counter.incrementAndGet()), timeout)
.onSuccess(new OnSuccess<Object>() {
public void onSuccess(Object result) {
logger.info(result.toString());
}
}, ec);
}
}, ec); 可以看到我们在客户端每2秒将发送一个新的消息,这个消息以“hello-”开头,后边是一个不断自增的数字。当收到处理结果后,客户端还会将结果打印出来。
我们以3个服务端节点(host相同,端口分别为2551、2552及随机)、1个客户端节点(端口随机)组成的集群为例,我们首先启动第一个种子节点,然后以任意顺序启动其它服务端或者客户端节点(启动顺序问题在《 使用Akka构建集群(一) 》一文中已介绍,此处不再赘述),集群成员变化的日志如下图:

从上面展示的日志中可以看到集群的3个服务端节点和1个客户端节点先后加入集群的信息。
我们再来看看端口为57222的角色为frontend的节点的日志信息,如下图:


看来2551节点处理了hello-4、hello-7及hello-10三条任务。我们再来看看端口为2552的backend节点,其处理任务的日志如下图:
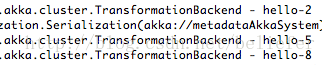
可以看到2552节点处理了hello-2、hello-5及hello-8三条任务。最后看看端口为57211的backend节点,其处理任务的日志如下图:

可以看到从hello-3到hello-10这8条处理任务被均衡的分配给了3个不同的后端节点处理。奇怪的是hello-1这条消息居然没有任何显示,那是因为前端节点刚开始处理消息时,backends列表里还没有缓存好任何backend的ActorRef。我们向上查找frontend节点的日志,在相隔很远的日志中发现了下面的输出:

这也印证了我们的猜测。
总结
根据本文的例子,大家应当看到使用Akka构建集群,开发人员只需要关注消息的发送与接收,而无需过多涉及集群的细节。无论前端还是后端节点都可以加入同一个集群,而且多个后端节点处理消息也能达到负载均衡的功效。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

