Yann LeCun最新演讲再谈预测学习:记忆网络和对抗训练是很有前景的方向
当地时间 2017 年 1 月 13 日,Yann LeCun 在爱丁堡大学做了一个题为《 预测学习(Predictive Learning) 》的演讲。在这篇文章中,我很高兴能向大家分享我在这个演讲中的收获。虽然我并没有完全理解他在讲座中提到的所有概念,但我会尽我所能分享我了解到的知识。

人工智能在过去几年的快速进展很大程度上可归功于深度学习和神经网络算法的进步,当然还有大规模数据集和高性能 GPU 的可用性。我们现在已经具有准确度可媲美人类的图像识别系统了,而这也引发了一些领域的革命性发展,其中包括信息存取(information access)、自动运输系统(autonomous transportation)和医学影像分析(medical image analysis)。
但是所有这些系统目前都在使用监督学习,即使用人工标记的数据作为机器的输入。所以接下来几年内的挑战就是让机器能从原始、未标记的数据(如视频或文本)中进行学习,这就是人们称为预测学习或无监督学习的方法。智能系统如今并不能掌握「常识」,而在人类和动物的世界里,常识是通过观察世界、参与世界和理解世界的物理约束而获得的。Yann LeCun 认为机器学习世界的预测模型的能力将会是人工智能的重大进步。然而主要的难点在于世界只是部分可预测的。接下来将会介绍无监督学习的一种一般形式,其能够应对部分可预测的世界。这种形式连接了许多众所周知的无监督学习方法以及一些新的和令人兴奋的方法(如对抗训练)。
Yann LeCun 简介
Yann LeCun 是 Facebook 的人工智能研究主管,纽约大学的 Silver 教授,隶属于纽约大学数据科学中心、Courant 数学科学研究所、神经科学中心和电气与计算机工程系。
Yann LeCun 在 1983 年在巴黎 ESIEE 获得电气工程学位,1987 年在 Université P&M Curie 获得计算机科学博士学位。在完成了多伦多大学的博士后研究之后,他在 1988 年加入了 AT&T 贝尔实验室(AT&T Bell Laboratories /Holmdel, NJ),后来在 1996 年成为 AT&T Labs-Research 的图像处理研究部门主管。2003 年,他加入纽约大学获得教授任职,并在 NEC 研究所(普林斯顿)呆过短暂一段时间。2012 年他成为纽约大学数据科学中心的创办主任。2013 年末,他成为了 Facebook 的人工智能研究中心(FAIR)负责人,并仍保持在 NYU 中兼职教学。从 2015 到 2016 年,Yann LeCun 还是法兰西学院的访问学者。
LeCun 目前感兴趣的研究领域包括人工智能、机器学习、计算机感知、机器人和计算神经科学。他最出名的是对深度学习和神经网络的贡献,特别是广泛用于计算机视觉和语音识别应用的卷积神经网络模型。他在这些主题以及手写字体识别、图像压缩和人工智能硬件等主题上发表过 190 多份论文。
LeCun 是 ICLR 的发起人和常任联合主席(general co-chair),并且曾在多个编辑委员会和会议组织委员会任职。他是加拿大高级研究所(Canadian Institute for Advanced Research)机器与大脑学习(Learning in Machines and Brains)项目的联合主席。他同样是 IPAM 和 ICERM 的理事会成员。他曾是许多初创公司的顾问,并是 Elements Inc 和 Museami 的联合创始人。LeCun 位列新泽西州的发明家名人堂,并获得 2014 年 IEEE 神经网络先锋奖(Neural Network Pioneer Award)、2015 年 IEEE PAMI 杰出研究奖、2016 年 Lovie 终身成就奖和来自墨西哥 IPN 的名誉博士学位。
概述
在这篇演讲中,LeCun 一开始介绍了最近人工智能的发展情况,然后谈到了人工智能面临的难题。接着,他深入论述了预测性学习以及 Goodfellow 在 2014 年提出的新概念:生成对抗性网络。除此之外,「常识」也是这篇演讲中多次提及的重要概念,我稍后会做解释。
这篇演讲的主题分为 4 个部分:
-
人工智能当前发展情况概览
-
人工智能所面临的难题
-
预测学习(无监督学习)
-
对抗训练
-
监督学习
实际上,去年取得的所有成功都是基于监督学习。我们在大量样本上(比如桌子、椅子、狗、汽车和人)训练机器,不过,机器可以识别之前没有见过的桌子、椅子等吗?

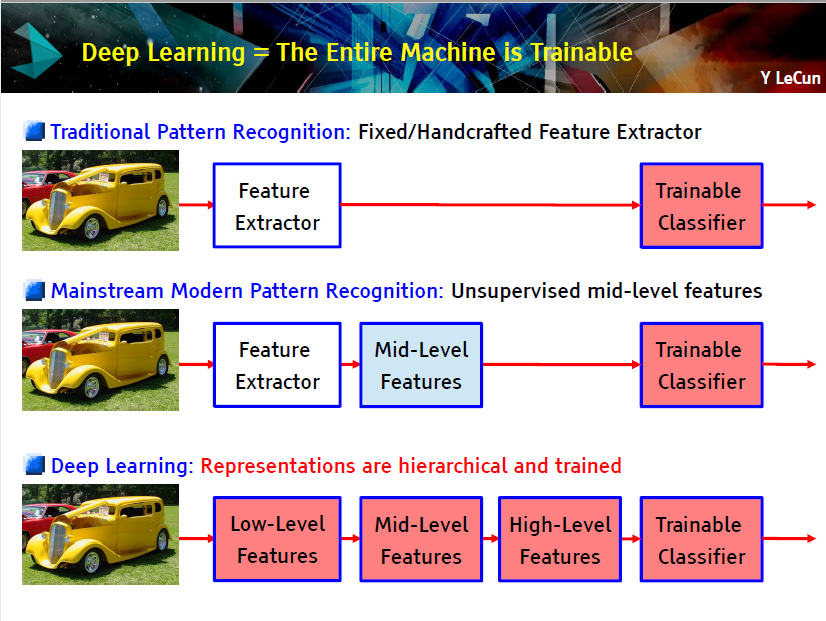

这两张幻灯片讲的是训练深度神经网络的过程,所有灰色图片是每一层提取的特征。当然,如果你觉得这些幻灯片内容很难理解,可以首先学习卷积神经网络以及反向传播算法。
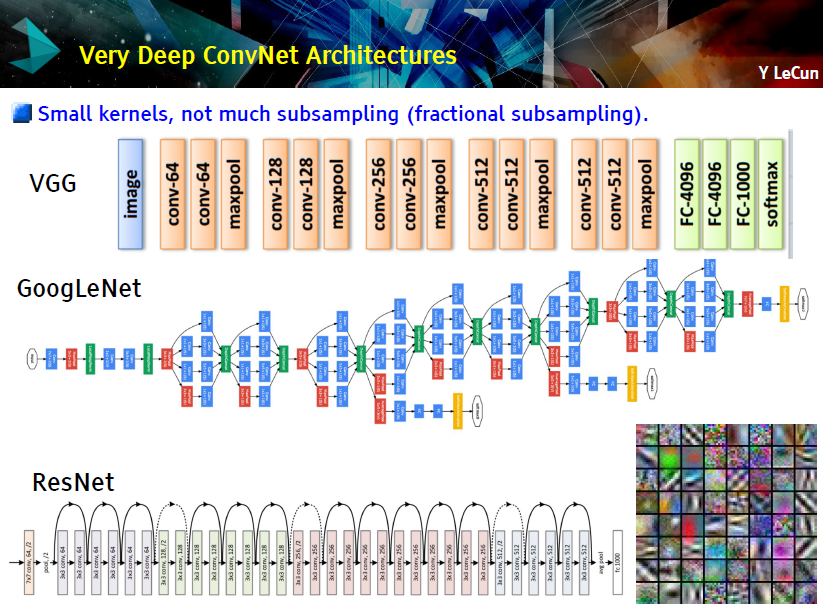
他也介绍了 深度卷积网络的架构:VGG、GoogleNet 和 ResNet
接着,他介绍了一些驾驶方面的研究——使用卷积网络对行驶中的汽车进行图像标注和语义分割。另外,他也给出了一些图像识别的例子。

在这一过程中,我们使用了计算机视觉和卷积网络方面的知识。
人工智能发展中所面临的难题

上面这张幻灯片告诉我们,机器需要通过观察和行动来获取某种程度的常识,这样才能准确预测、规划以及关注重要事项。记忆相关事件并预测如何行动才能得到我们想要的世界的状态。
-
智能&常识=感知+预测模型+记忆+推理&规划
-
常识是一种填空能力
-
从部分信息推出世界状态
-
从过去和现在推断未来
-
从当前状态推断过去事件
-
补充视觉盲点的视野内容
-
补充被遮挡的图像
-
补充文本、语音缺失部分
-
预测行动结果
-
预测导致结果的行动序列
人类有常识。比如,看看下面这幅图片

我们知道这个人拿起包并要离开房间。我们之所以有常识是因为我们知道世界运行原理,不过,机器怎么学会常识呢?
从提供的任何信息预测过去、现在以及未来的任何一部分。这就是预测学习(predictive learning)。不过,这是很多人对无监督学习(unsupervised learning)的定义。
无监督学习/预测学习的必要性
训练大型学习机器所需的样本数量(无论为了完成何种任务)取决于我们需要预测的信息量大小。
你需要机器回答的问题越多,样本数量就要越大。
如果想用很多参数训练一个非常复杂的系统,就需要海量训练样本让系统预测很多内容
「大脑有 10 的 14 次方个突触,我们却只能活大概 10 的 9 次方秒。因此我们的参数比我们所获得的数据会多的多。这一事实激发了这一思想:既然感知输入(包括生理上的本体感受)是我们每秒获取 10^5 维度约束(10^5 dimensions of constraint)的唯一地方,那么,就必须进行大量的无监督学习。」
预测人类提供的标签,一个价值函数(value function)是不够的。
然后 LeCun 举了个例子,解释了不同的学习算法进行预测需要多少信息。如下幻灯片所示。
随后,他使用两篇预测视频帧的论文阐述了强化学习系统,这是 Facebook 赢得 VizDoom 2016 比赛的研究结果。[Wu & Tian, submitted to ICLR 2017] 和 Plug: TorchCraft: interface between Torch and StarCraft [Usunier, Synnaeve, Lin, Chintala, submitted to ICLR 2017].
他在这里还提到了人工智能的成功案例 AlphaGo,不过很难将其用于真实世界。因为围棋的世界一步步的,我们的学习系统可以通过许多训练样本获得经验。但真实的世界是存在许多问题的,我们永远不能加速真实世界来进行训练模型。

智能系统的架构
这一部分是关于人工智能系统架构的,我认为这对我们很重要,所以我把四张 PPT 贴到这里。但是,除了 PPT 上的内容,Yann 并没有展开太多。
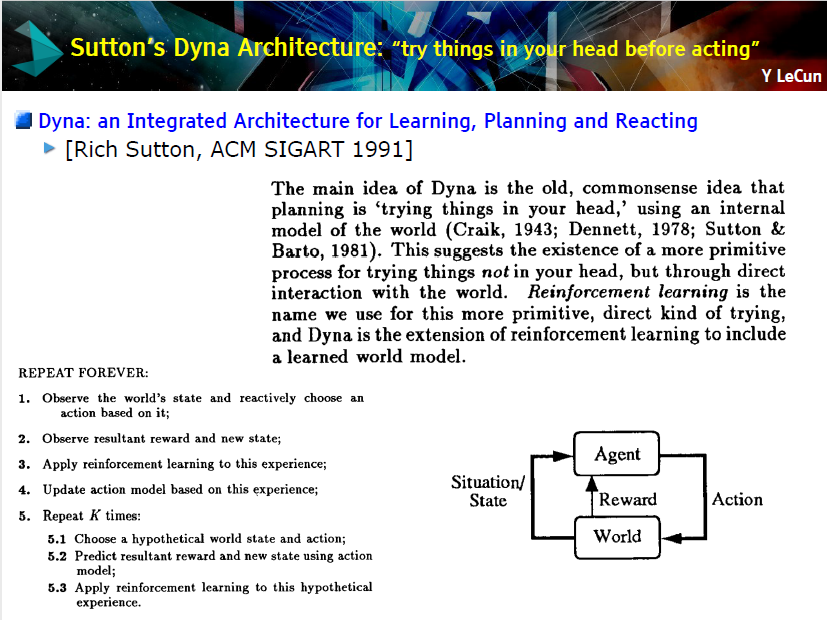
上述理论非常类似于下述的控制论。
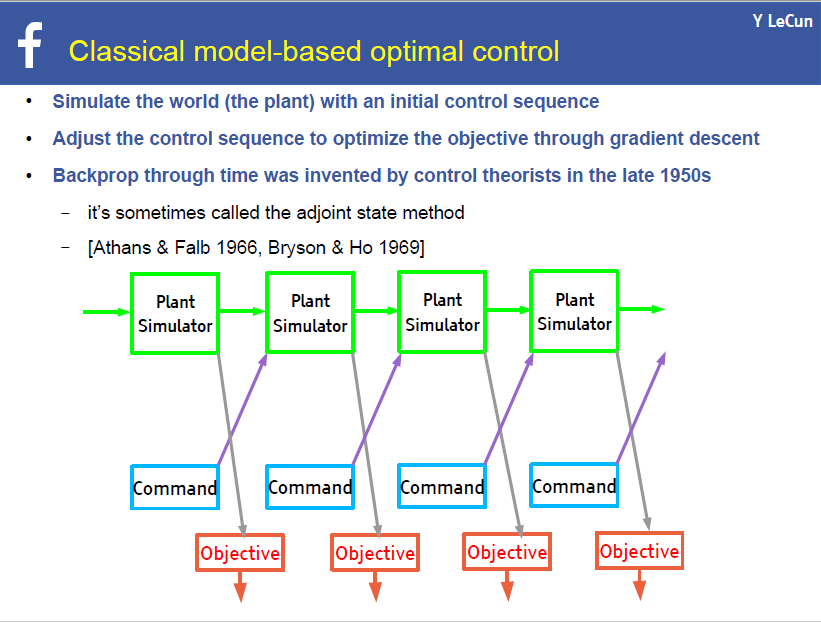
下面的这个幻灯片简单但非常清楚地勾勒了人工智能的架构,如果读者了解模式识别的基本过程,你也能理解这个架构。
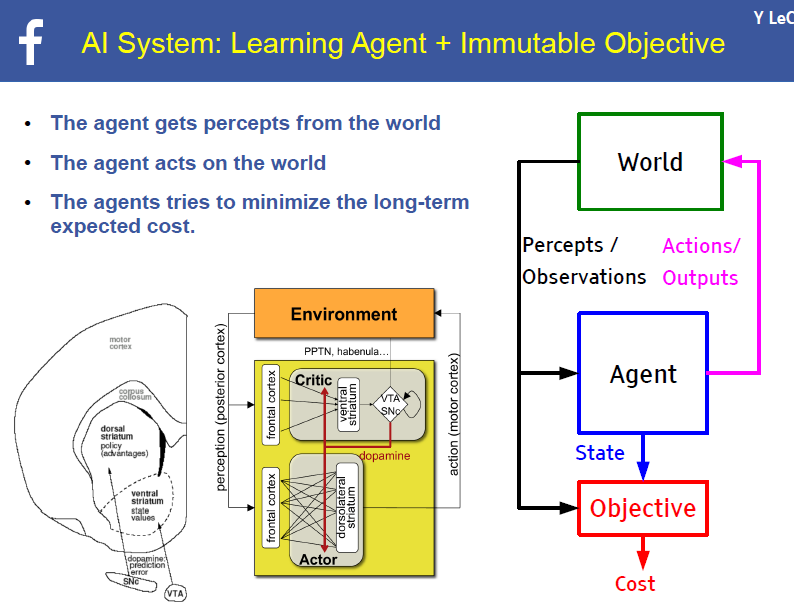
这里的关键词是模拟世界和目标函数(objective function)。因此,你要懂它们的意思。
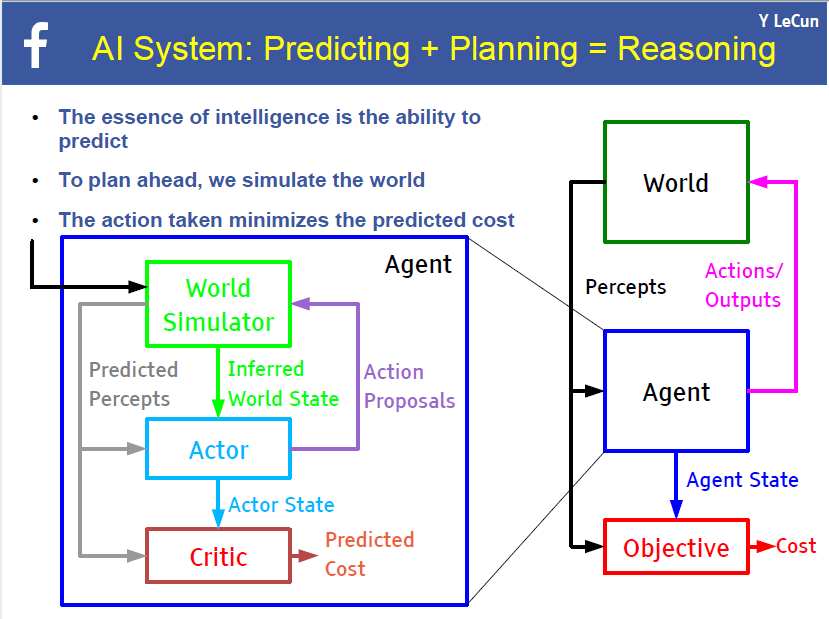
学习关于世界的预测性正演模型
Yann 介绍了一个预测落体轨迹的模型,其使用了非真实的游戏引擎,它与真实世界的真实物体略微不同,因此,也只是在游戏引擎中有效。后来,他讨论了真实世界中的真实物体的情况。
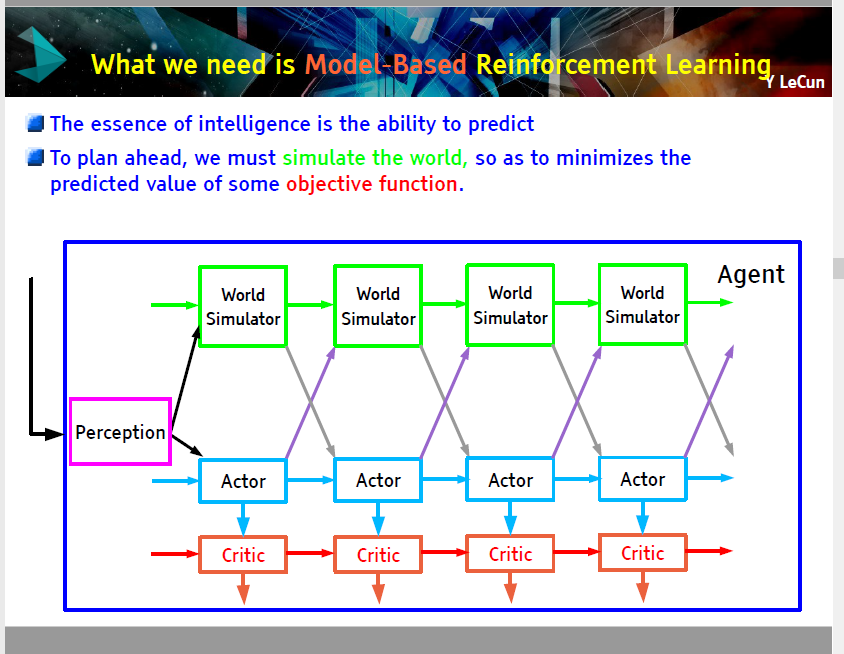

从文本中进行推断:实体 RNN
尽管监督式 ConvNet 已经取得了重大的进展,我们仍需要记忆增强网络赋予机器进行推论的能力。Yann 用 PPT 的形式帮助我们理解记忆/堆栈增强循环网络。
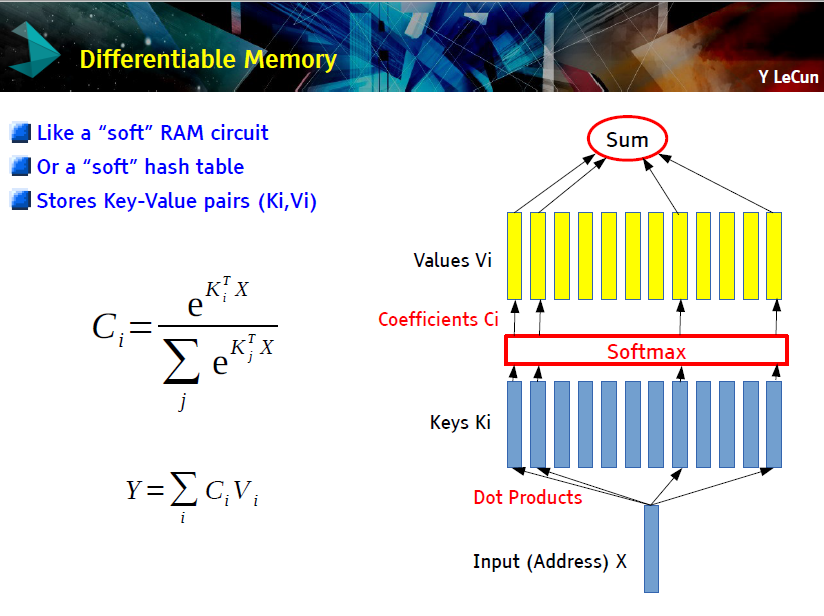
使用记忆模块增强神经网络
-
循环网络不能进行长期记忆
-
皮层记忆只能持续 20 秒
-
神经网络需要一个「海马体」(一个单独的记忆模块)
-
LSTM [Hochreiter 1997],暂存器
-
Memory networksWeston et 2014,联合存储器
-
堆栈增强循环神经网络 Joulin & Mikolov 2014
-
神经图灵机 [Graves 2014]
-
可微分神经计算机 [Graves 2016]
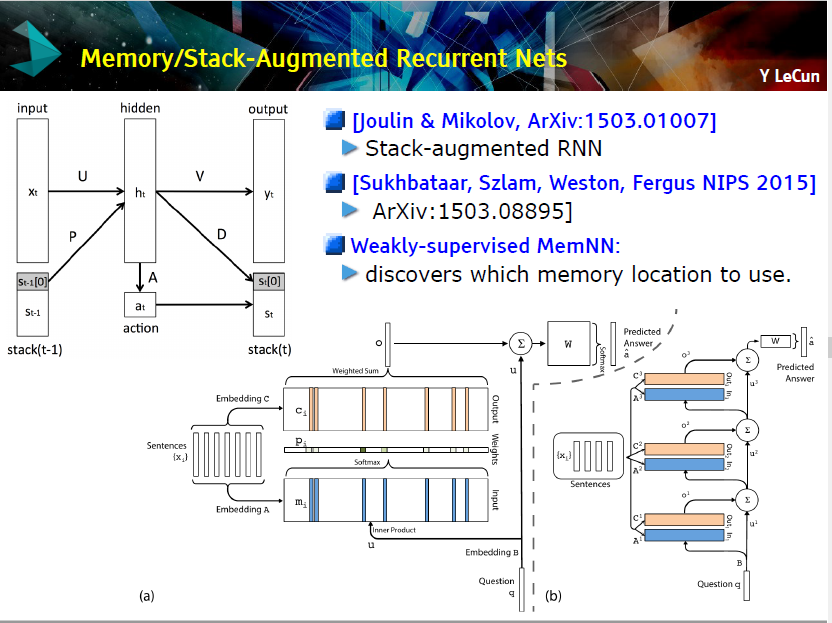
此外,他也给出了一个例子演示 MemNN 的结果。


EntNet 是第一个解决所有 20 个 bAbi 任务的模型。
无监督学习
基于能量的无监督学习
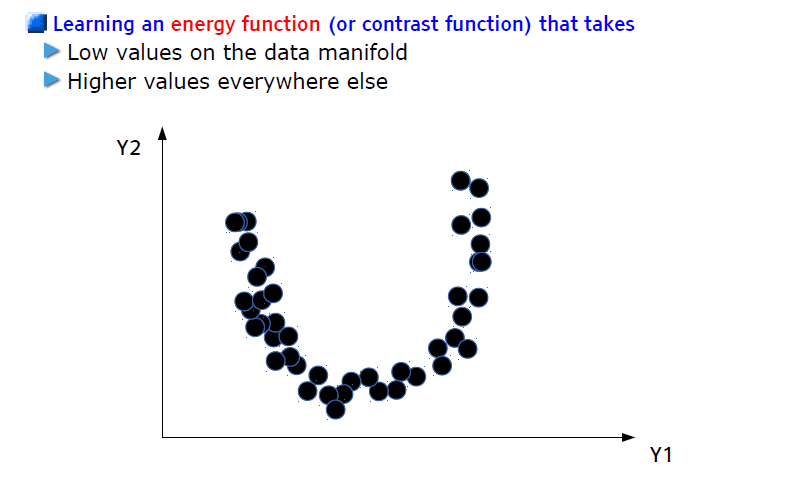
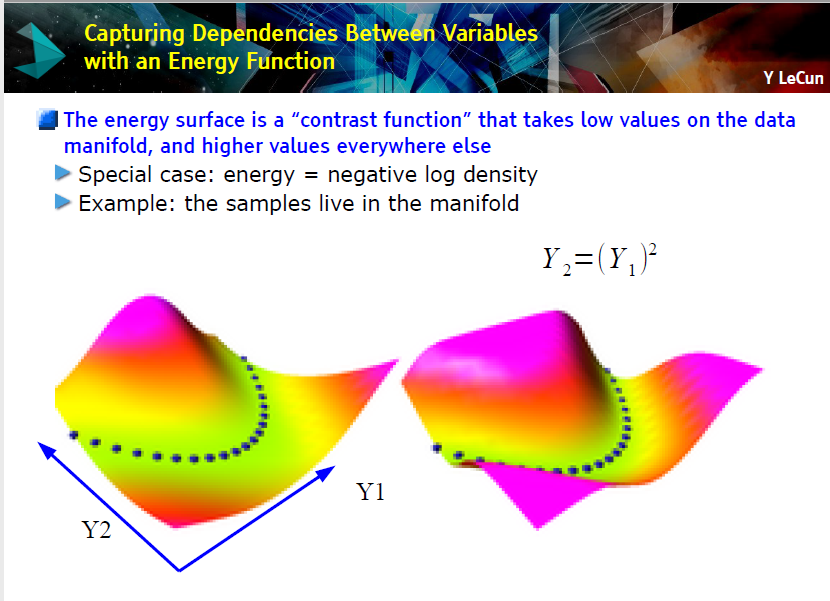

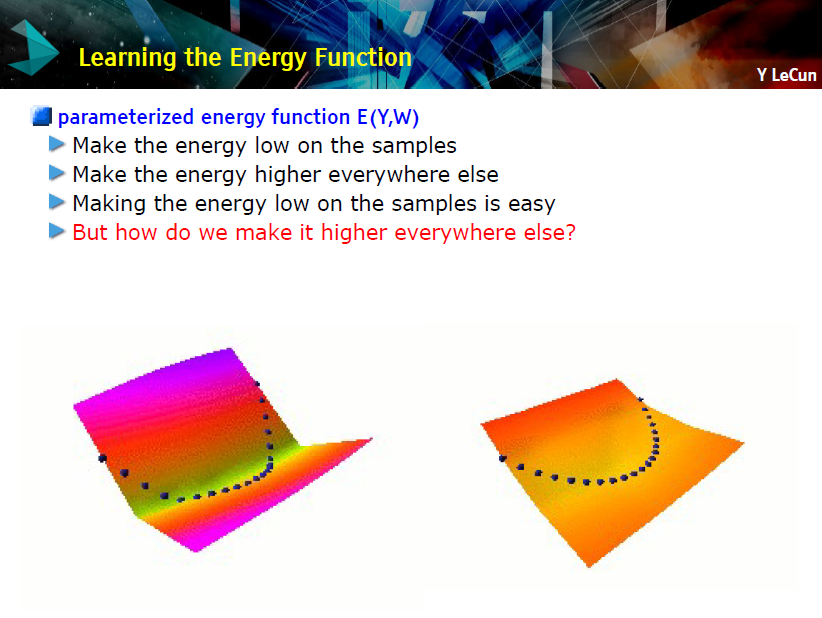
塑造能量函数的 7 种策略
1.建立低能量体量(the volume of low energy stuff)不变的机器
-
PCA、K-means、GMM、square ICA
2.数据点能量的下推(push down),其他位置能量都提高(push up)
-
最大似然(需要易操作的配分函数)
3.数据点能量的下推(push down),在选择出的点上进行提高
-
contrastive divergence、Ratio Matching、Noise Contrastive Estimation、Minimum Probability Flow
4.围绕数据点最小化梯度,最大化曲率(curvature)
-
score matching
5.训练一个动态系统,以便于动态进入 manifold
-
降噪自编码器
6.使用正则化进行限制有低能量的空间体量
-
Sparse coding、sparse auto-encoder、PSD
7.如果 E(Y) = ||Y - G(Y)||^2, 尽可能的使得 G(Y) 不变
-
Contracting auto-encoder, saturating auto-encoder
对抗训练
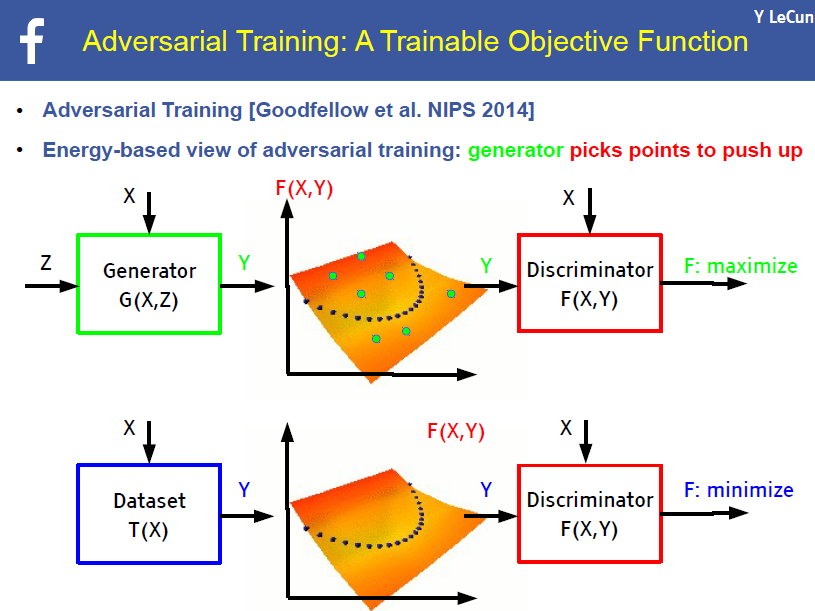
然后,他谈到了 2014 年由 Ian Goodfellow 提出的对抗训练(GAN),这是改进机器预测能力的一种方式。GAN 包括一个生成器、一个判别器,它们同时进行学习。你可以通过阅读引用 [5],、[6] 了解更多。
下面是在现实世界进行预测的一个例子。比如图中演示,当你松手时笔倒下可能指向不同的方向。我们如何准确的预测笔的指向?这是一个难题,与学物理的学生多交流会有帮助。
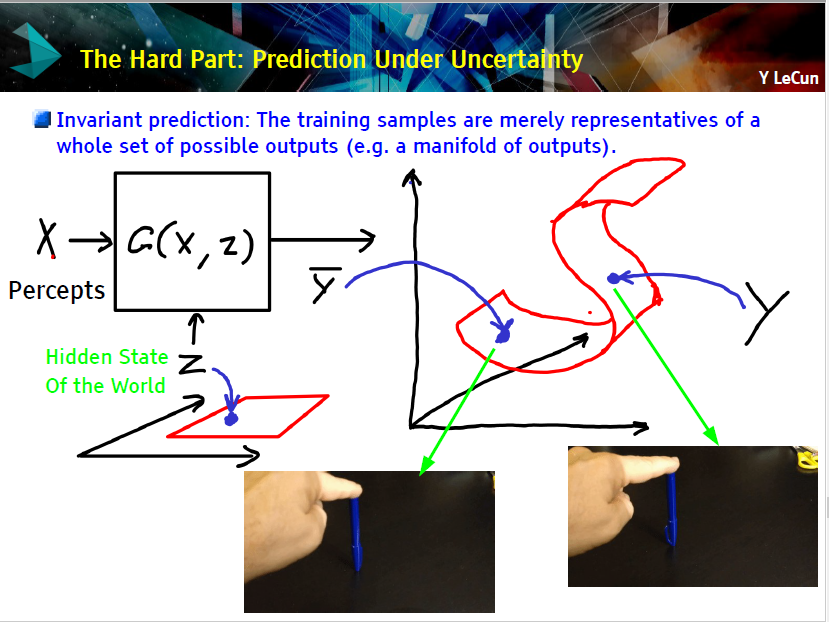
然后,Yann 给出了一个解决方案,基于能量的无监督学习:

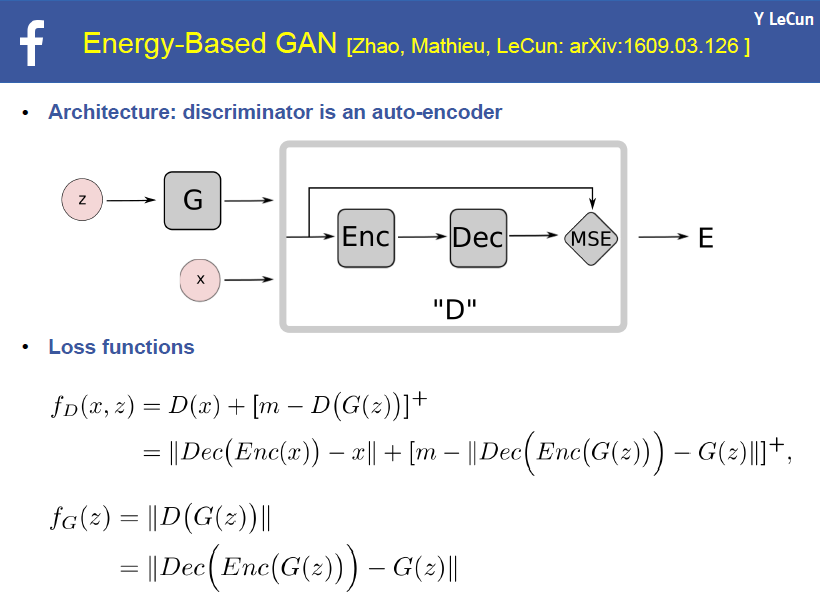
下面我附上了 PPT,有一些关于基于能量的 GAN 的函数:

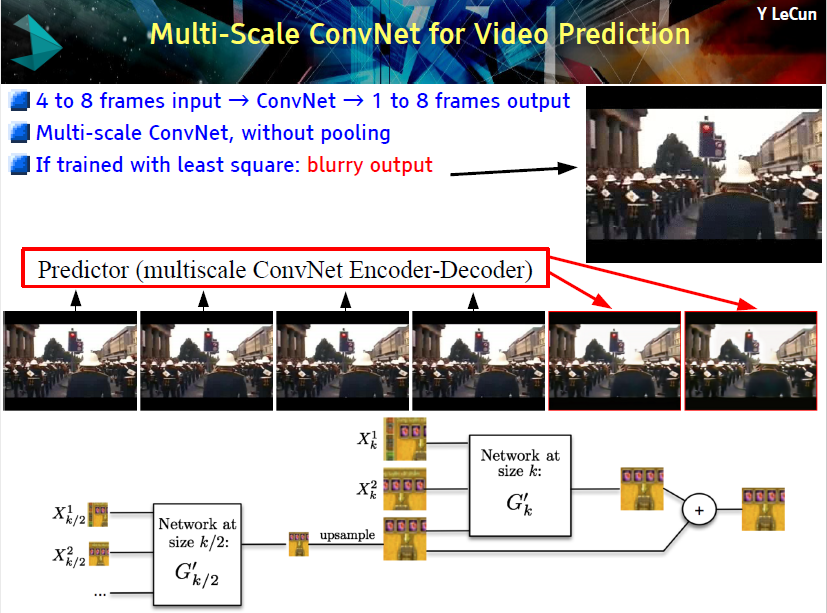
视频预测
最终,Yann 向我们演示了关于视频预测的有趣例子,使用不带有池化(pooling) 的多尺度 ConvNet。Yann 说他也不知道为什么这里的池化不起作用。
-
我们的大脑是一台「预测机器」。
-
我们能否训练机器来预测未来?
-
一些使用「对抗训练」获得的成功。
-
但我们离完全的成功还很远。
总结
总而言之,Yann 在演讲中总结了去年人工智能领域的进展,并介绍了监督学习的一些知识点。然后,Yann 聚焦于无监督学习。他认为无监督学习会成为未来的主流,能解决我们的学习系统难以处理的众多问题。我们如今正在面临无监督和预测性前向模型(predictive forward model)的建立,这也可能会是接下来几年的挑战。此外,对抗训练在未来可能会逐渐扮演更重要的角色,而如今的难题是让机器学习「常识」。
我个人看来,我也从 Yann 身上获得了一些特别的东西。他非常友好、乐于助人。现场有一个学生问了一个非常耗时间的 问题,他同样给出了解答,这超乎了我的想象。此外,他告诫我们多与其他领域的人交流,比如物理学,这可能帮助我们解决上面提到的预测笔倒下之后指向的问题。最后,我们来了一个合照。
References
[1] Goodfellow, Ian, et al. "Generative adversarial nets." Advances in Neural Information Processing Systems . 2014.
[2] Athans, Michael, and Peter L. Falb. Optimal control: an introduction to the theory and its applications . Courier Corporation, 2013.
[3] https://research.fb.com/projects/babi/
[5] https://arxiv.org/pdf/1511.06434v2.pdf
[6] https://tryolabs.com/blog/2016/12/06/major-advancements-deep-learning-2016/
[7] http://datascience.inf.ed.ac.uk/events/data-science-distinguished-lecture
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

