京东分布式服务跟踪系统-CallGraph
一、CallGraph的产生背景
随着京东业务的高速增长,京东研发体系陆续实施了SOA化和微服务战略,以应对日益复杂的业务和急剧增加的应用种类。这些分布式应用彼此依赖,共同协作来完成所有京东的业务场景,其动态变化的复杂性和数量已超出想象,对其进行监控并试图掌控全局已非人力所及,迫切需要一种软件工具来帮助相关人员理解系统行为,从而为诸如流程优化、架构优化、程序优化、以及扩容、限流、降级等运维行为提供科学的客观依据。

CallGraph根据Google为其基于日志的分布式跟踪系统Dapper发表的论文,由京东商城基础平台部自主研发,目前已经上线。业界亦有类似系统,比如淘宝鹰眼、新浪WatchMan等等,但是CallGraph除了提供与这些系统类似的功能外,还有其自身的特色,下文将详细讲解。
二、CallGraph的核心概念
“调用链”是CallGraph最重要的概念,一条调用链包含了从源头请求(比如前端网页请求、无线客户端请求等)到最后底层系统(比如数据库、分布式缓存等)的所有中间环节,如下图所示。
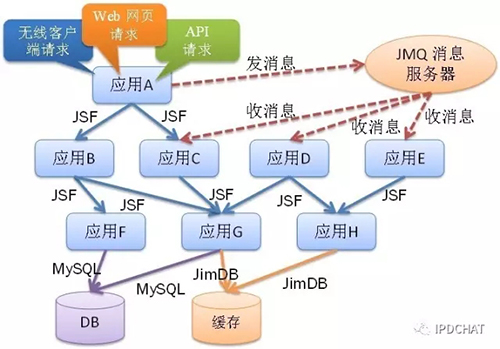
每次调用,都会在源头请求中产生一个全局唯一的ID(称为“TraceId”),通过网络依次将TraceId传到下一个环节,该过程被称为“透明数据传输”(简称“透传”),图中的每一个环节都会生成包含TraceId在内的日志信息,通过TraceId将散落在调用链中不同系统上的“孤立”日志联系在一起,然后通过日志分析,重组还原出更多有价值的信息。
三、CallGraph的特性及使用场景
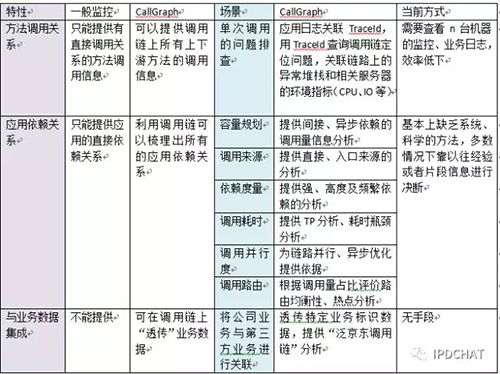
CallGraph本质上是一种监控系统,但它提供了一般监控系统所没有的特性,每种特性都有其典型使用场景,为相关人员提供了强大的问题排查手段和决策依据,现总结如下:
四、CallGraph的设计目标
针对CallGraph这样的监控系统,特制定了如下设计目标:
1. 低侵入性
作为非业务系统,应当尽可能少侵入或者不侵入其他业务系统,保持对使用方的透明性,这样可以大大减少开发人员的负担和接入门槛。
2. 低性能影响
CallGraph通过对各中间件jar包进行改造,完成日志数据的产生和收集,我们称这种改造为“埋点”。由于埋点都发生在业务核心流程上,所以应该尽最大努力降低对业务系统造成的性能影响。
3. 灵活的应用策略
为了消除业务方因使用CallGraph会对其自身产生影响的担忧,应该提供灵活的配置策略,以让业务方决定是否开启跟踪,以及收集数据的范围和粒度,并提供技术手段保障配置必须生效。
4. 时效性(time-efficient)
从数据的产生和收集,到数据计算/处理,再到展现,都要求尽可能快速。
五、CallGraph的实现架构

1. CallGraph核心包
Callgraph-核心包被各中间件jar包引用,核心包里完成了具体的埋点逻辑,各中间件在合适的地方调用核心包提供的API来完成埋点;核心包产生的日志被存放在内存磁盘上,由日志收集Agent发送到JMQ里。
(1)JMQ
JMQ是京东的分布式消息队列,利用其强劲的性能,充当日志数据管道,Storm将不断地消费里面的日志数据。
(2)Storm
利用Storm进行流式计算,对日志数据并行进行整理和各种计算,并将结果分别存放到实时数据存储和离线数据存储中。
(3)存储
包括实时数据和离线数据两部分存储。实时数据部分包括了Jimdb、Hbase和ES,Jimdb是京东自己的分布式缓存系统,里存放了调用量、TP等实时指标数据;利用Hbase的SchemaLess特性,存放了固化后的链路数据,因为不同的链路包含的中间环节数量不一样,无法用像Mysql这样的强Schema特性的存储,利用TraceId就可以从Hbase里查询到某一次调用的所有中间环节的信息。离线数据部分包括HDFS和Spark,用于海量历史数据分析,并且还会把一些结果存放到Mysql中。
(4)CallGraph-UI
这是CallGraph提供给用户的交互界面,在这里面用户可以查看属于自己的所有系统以及各系统内的应用的调用链路的详细情况,包括应用间的相互依赖关系图,某种服务方法的来源分析、入口分析、路径分析,以及某次具体的调用链路的详情等等,还可以对应用进行诸如“采样率”等配置的设置。
(5)UCC
UCC是京东自己的分布式配置系统,CallGraph用它来存放所有的配置信息,并且同步到应用服务器本地的配置文件中。核心包将定期检查这些配置文件,以使配置生效。当UCC故障后,也可以通过直接操纵本地配置文件,使配置生效。
(6)管理元数据
存放CallGraph的管理元数据,比如链路签名与应用的映射关系、链路签名与服务方法的映射关系等等;
2. CallGraph的技术实现
(1)埋点和调用上下文透传
该部分属于架构图中的CallGraph-核心包的重点部分,也是难点部分。CallGraph-核心包完成埋点逻辑,如下图所示:
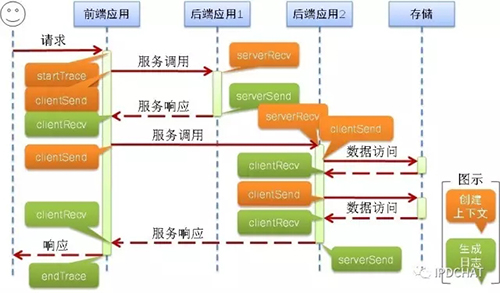
前端应用和各中间件jar包引入CallGraph核心包,前端应用利用Web容器的Filter机制调用核心包的startTrace开启跟踪,收到响应后调用endTrace结束此次跟踪,各中间件在合适的地方调用核心包提供的clientSend、serverRecv、serverSend和clientRecv等原语API,其中,橙色的完成“创建上下文”,绿色的完成“生成日志”。
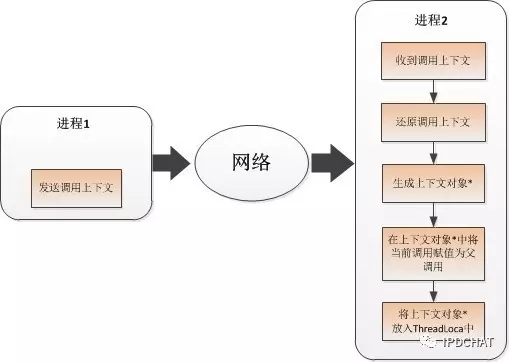
对于进程间的上下文透传,调用上下文放在本地ThreadLocal,对业务透明,调用上下文在中间件的网络请求中传递,并在对端收到后进行重组还原出调用上下文,过程如下图所示:
对于异步调用,将涉及到线程间上下文透传,通过java字节码增强的方式在CallGraph核心包载入期织入增强逻辑,以透明的方式完成线程间上下文的透传。这里又可分为两种类型,一种是直接创建新线程的方式,如下图所示,
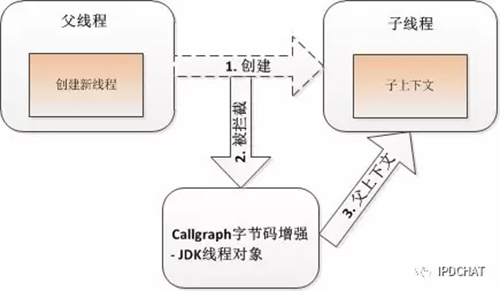
这种方式通过对JDK线程对象(Thread)进行增强完成,子线程将把父线程的上下文作为自己的上下文(图中的“子上下文”);对于使用Java线程池来提交异步任务来说,就不存在“父子”线程关系了,这时通过对各种JDK线程池的增强,实现了上下文透传,如下图所示:
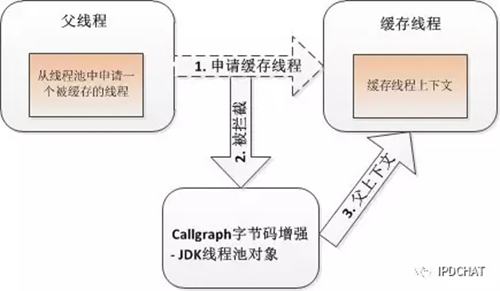
上述过程对开发人员完全透明,对运维人员来说也很方便,做到了“低侵入性”。
六、日志格式设计
CallGraph的日志格式需要满足不同中间件的特定要求,同时还要保证版本的兼容性。总体上说,CallGraph的日志格式分成固定部分和可变部分,其中固定部分由如下组成:
- TraceId,RpcId,开始时间,调用类型,对端IP
- 调用耗时
- 调用结果
- 与中间件相关的数据:比如rpc调用的接口、方法,mq的topic名称等
- 通信负载量
- 请求字节数/响应字节数
可变部分最重要的就是“自定义数据”,用户可以使用CallGraph-核心包API增加自己的特殊字段,以用于特殊目的。通过抽象设计,不同场景的日志格式都有专门的encoder类,在输出日志时配套使用。
1. 高性能的链路日志输出
为了彻底避免和业务竞争I/O资源,CallGraph专门在应用服务器上开辟专门的内存区域,并虚拟成磁盘设备,核心包产生的日志存放在这样的内存磁盘上,完全不占用磁盘I/O,并且速度极快。同时开发专门的日志模块,日志输出采取批量、异步方式写入内存磁盘,并在日志量过大时采取“丢弃日志”的方式最大程度地降低对业务的影响,如下图所示:
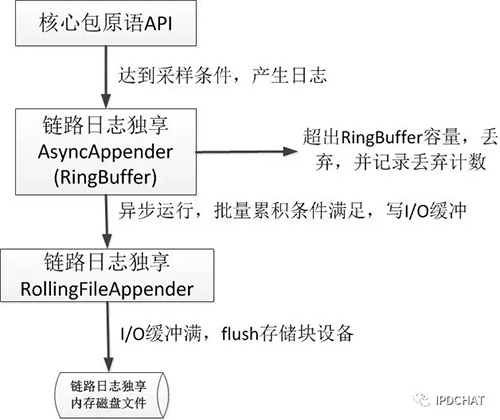
2. TP日志和链路日志分离
为了最大程度减少对业务性能的影响,在实践中,多数情况下会开启“采样率”机制,比如1000次调用,只收集1次调用的信息,这样可以极大地降低日志产生量。但是对于TP指标来说,必须记录每次调用的TP值,否则提供的TP50、TP99、TP999指标将不准确,从而变得无意义。从本质上说,链路信息和TP性能指标是两种不同属性的数据,因此在核心包里分别对这两种数据进行独立处理,彼此互不影响,采用各自的日志收集及输出策略,TP指标的处理如下图所示:
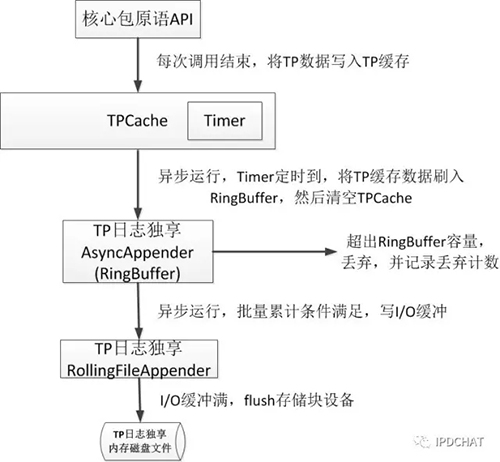
3. 实时配置
当双11或者618大促时,各业务系统为了确保业务正常,基本上都会对非业务系统采取降级的手段。CallGraph为满足业务方的这种需求,提供了丰富的配置和降级手段。CallGraph提供了基于应用、应用分组、应用服务器IP等多维度的配置方式,每个维度上都提供了“是否开启链路跟踪”、“链路采样率”、“是否开启TP跟踪”、“TP颗粒度”等配置项,来供业务方根据情况来使用。
业务方通过CallGraph-UI管理端自助设置业务的各配置项。全部配置信息存放在UCC(京东的分布式配置系统)上,同时也会同步到应用服务器的本地配置文件中。CallGraph-核心包有专门的Daemon线程定期访问本地的这些配置文件,以使配置生效;当UCC出现故障,不能被正常访问时,也可以直接操纵这些本地配置文件,确保配置立即生效。
4. storm流式计算
所有日志,不管是链路日志还是TP日志,最后都必须经过storm进行计算产生结果数据,并分别存储到实时数据存储和离线数据存储中,如下图所示:
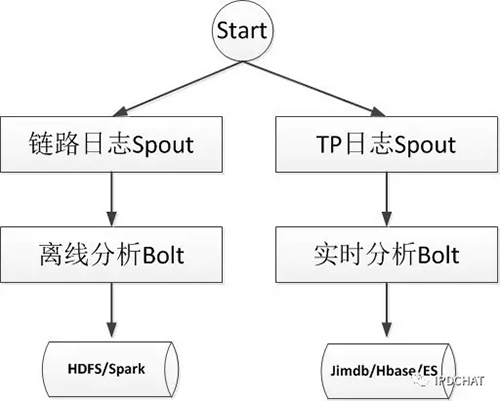
离线分析Bolt由一系列Bolt组成,它们分析链路日志信息,负责产生符合离线数据模型的结果数据,后续将由大数据技术比如spark/flume等进行计算,得到大时间尺度下的固定后的链路的一些特征指标,比如调用次数、平均耗时、错误率等等。
实时分析Bolt分析TP日志信息,负责生成实时指标数据,并存储在Jimdb中,供CallGraph-UI调用展示。
5. 实时数据分析-秒级监控
这是CallGraph区别与其他类似系统的一大功能。其他类似系统只提供链路日志分析,而链路日志的分析需要积累海量数据,然后借助大数据相关技术进行分析,其实时性较低。针对业务方对实时分析的需求,CallGraph采用分布式缓存系统Jimdb来存放实时数据,针对来源分析、入口分析、链路分析等可以提供1小时内的实时分析结果(Jimdb中的数据设置过期时间,自动过期),其中涉及到调用量、调用量占比、TP性能指标等的展示,该功能被内部称为“秒级监控”。“秒级监控”需要对TP日志进行分析,原理如下图所示:

LogRealTimeBolt将从LogTPSpout中得到TP原始日志,进行整理、分析和计算,并将结果暂时缓存在“本地缓存”中,当达到累积计数条件后,再批量地汇总到Jimdb存储中,这样做的好处是先在本地进行合并计算,另外也减少了Jimdb的I/O次数。
七、CallGraph的未来之路
CallGraph在京东的历史还很短,将来还有很长的路要走。为了进一步满足业务方对CallGraph的需求,未来CallGraph将陆续完善和提供如下功能:
- 进一步优化实时数据的处理机制,使得时延更低,达到真正的“实时”;目前该功能由于需要经过日志收集、JMQ以及storm等过程,所以存在十几秒到几十秒钟的时延,属于“准实时”的范畴;
- 完善实时的错误发现及报警机制,进一步提高发现问题的及时性;
- 接入更多的中间件,进一步丰富调用链内容,使调用链更长更完整;
- 提供完整的API接口,将调用链数据共享给兄弟团队,方便他们构建自己的调用链分析系统;
- 借助深度学习算法,进一步挖掘调用链历史数据的价值,力争在更多维度上提供出有价值的分析数据。
【本文来自51CTO专栏作者张开涛的微信公众号(开涛的博客),公众号id: kaitao-1234567】
戳这里,看该作者更多好文
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

