深入浅出自动驾驶(二):卷积神经网络(CNN)
如何识别一张图像
如下图片所示,你要如何识别是一只狗呢?

我们可以把眼睛、鼻子、嘴都分开,而后分别识别出来,最后将所有的特征组合起来,就可以看出来是一只狗啦
比如在这幅图中,你就可以分别识别出
1 眼睛
2 鼻子
3 金毛
如下图所示
让我们进一步分析,如何识别眼睛、鼻子和毛发呢?以金毛的鼻子为例,如何才能知道这是一个鼻子呢?我们可以用鼻子上方的弧线和鼻孔来定义一个鼻子
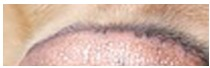 鼻子上方的弧线
鼻子上方的弧线
 鼻孔
鼻孔
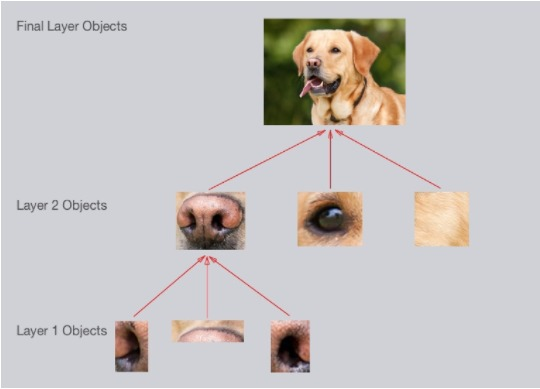
这就是CNN的处理逻辑了,它首先识别简单线条和曲线,而后是形状和区块...最后组合起来,识别这个物体,是狗,还是猫,或是其它物体。
在我们的例子中,可以做入下分解
1 简单的线条,比如曲线、直线等等
2 复杂的物体,比如鼻子、眼睛等等
3 作为狗的整体
最令人兴奋的是我们根本不用去手动分解,CNN网络自己就能够做了,如下图所示
什么是卷积神经网络
假设你有一张照片,如图所示
一张猫的照片可以表示为一个有width,有height以及厚度为3(RGB)的薄饼。然后我们在图片上取出X大小的一个方块,并把它映射成高维空间的深度为K的向量
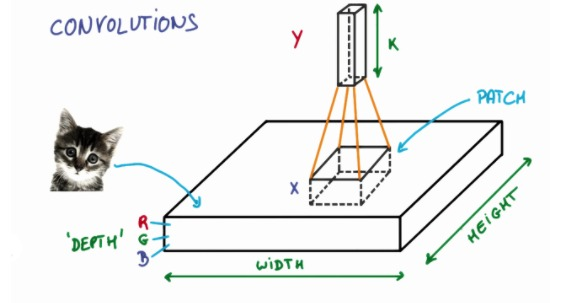
而后我们移动这个方块
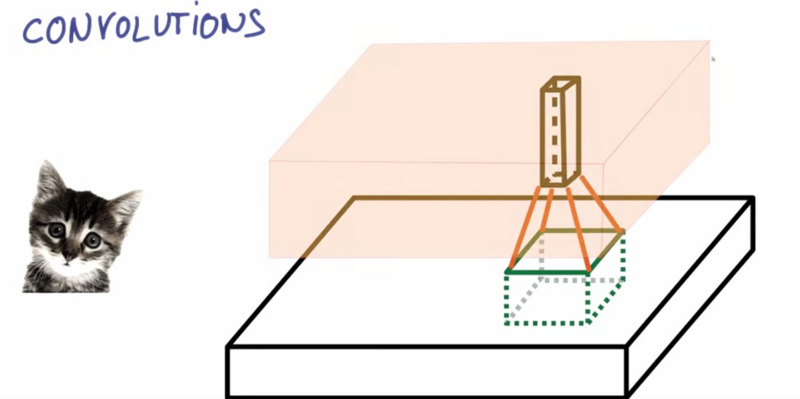
最终得到一个宽度为width,高度微height,深度为k的图像,这就称为卷积了

卷积的思想是将图像的特征逐步的映射到深度中去(图像特征),以此把图像特征全部连接起来,然后就可以判断分类的类型(图像的类型)
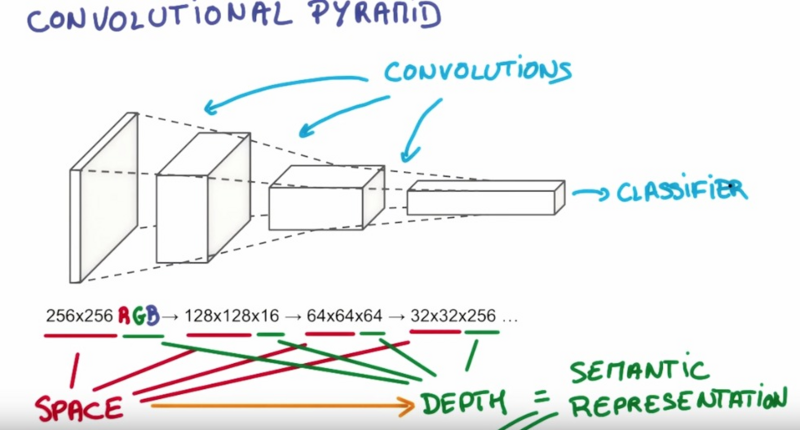
为何要使用卷积神经网络
CNN在图像领域用的比较多,以一张1000*1000像素的图像为例,如果使用单纯的神经网络,加上隐藏层,共需要1000000x1000000 = 10^12个参数,这样就太多了,基本没法使用神经网络训练,所以必须减少参数个数,这是使用卷积神经网络一个非常重要的原因
我们也可以从另一个角度来看:一张图片上不是所有的像素(特征)都有效,只需要取某一个区块内的代表像素就可以了,局部区块的像素关联性较强,其它的关联较弱
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

