羽毛也疯狂,盘点 Apache 最新毕业的11个顶级项目
自1999年成立至今,Apache 软件基金会已成功建立起自己强大的生态圈。其社区涌现了非常多优秀的开源项目,同时有越来越多国内外项目走向这个国际开源社区进行孵化。据悉,目前所有的 Apache 项目都需要经过孵化器孵化,满足一系列质量要求之后才可毕业。从孵化器里毕业的项目,要么独立成为顶级项目,要么成为其他顶级项目的子项目。
为便于大家了解 Apache 孵化的标准,本文盘点了 Apache 从2016年1月1日至2017年1月19日所有孵化成功并独立管理的顶级项目,共有11个。同时,欢迎大家在评论区留言互动,聊聊对 Apache 的看法,分享曾经使用过的感受……

1、Apache Beam
Apache Beam 是 Google 在2016年2月1日贡献给 Apache 基金会的孵化项目,于 2017年1月10日正式宣布 毕业,升级为 Apache 顶级项目。
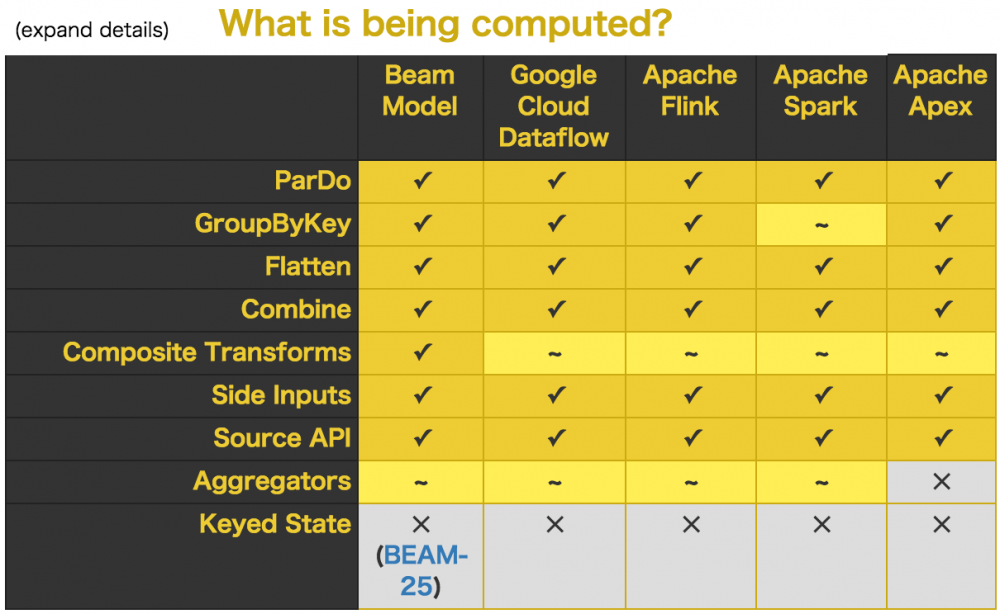
Apache Beam 的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。项目重点在于数据处理的编程范式和接口定义,并不涉及具体执行引擎的实现。Apache Beam 希望基于 Beam 开发的数据处理程序可以执行在任意的分布式计算引擎上。
2、Apache Eagle
Apache Eagle 起源于 eBay,最早用于解决大规模 Hadoop 集群的监控问题,2015年10月26日提交给 Apache 进行孵化,于 2017年1月10日正式宣布 毕业成为 Apache 顶级项目。
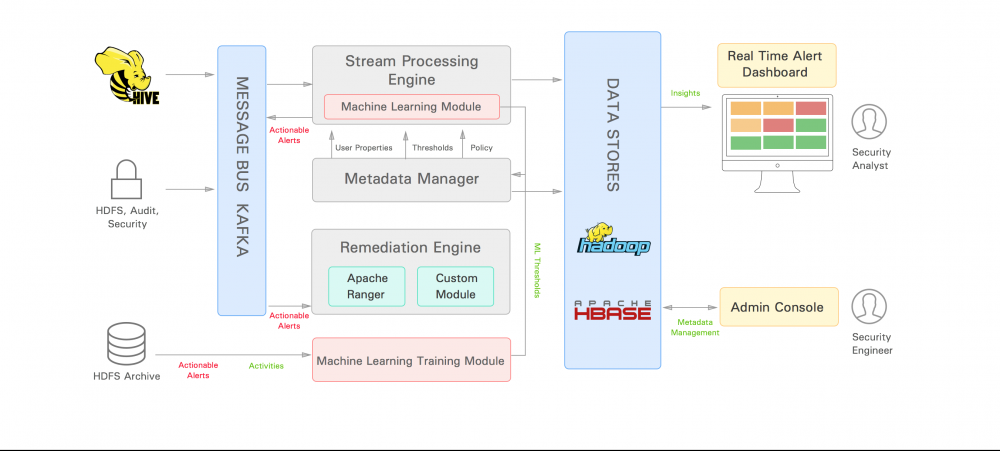
Apache Eagle 是一个开源监视和警报解决方案,用于智能实时地识别大数据平台上的安全和性能问题,例如 Apache Hadoop、Apache Spark 等。Apache Eagle 主要包括:高可扩展、高可伸缩、低延时、动态协同等特点,支持数据行为实时监控,能立即监测出对敏感数据的访问或恶意的操作,并立即采取应对的措施。
3、Apache Geode
Apache Geode 最初是由 Gemstone Systems 公司作为商业产品开发,初期被广泛应用在金融领域,作为事务性、 低延时的数据引擎用于华尔街交易平台。2015年4月27日将代码提交给 Apache 孵化器,于2016年11月21日毕业成为 Apache 顶级项目。
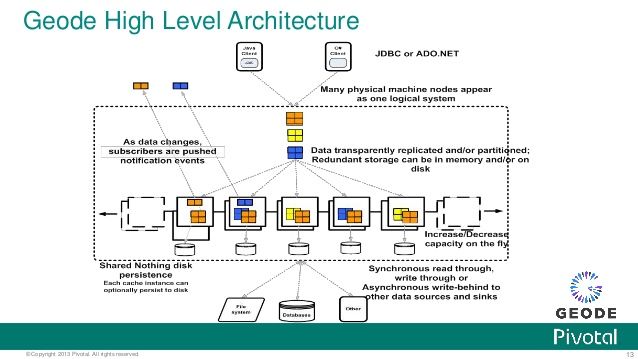
Apache Geode 是一个数据管理平台,提供实时的、一致的、贯穿整个云架构地访问数据关键型应用。它使用了动态数据复制和分区技术来实现高可用、高性能、高可扩展性、和容错。另外,对于一个分布式数据容器,Apache Geode 是一个基于内存的数据管理系统,提供了可靠的异步事件通知和可靠的消息投递。
4、Apache Twill
Apache Twill 于2013年11月14日将代码提交给 Apache 孵化器,2016年7月27日宣布毕业成为 Apache 顶级项目。
Apache Twill 为常见的分布式应用程序提供了丰富的内置功能,用于开发、部署和管理,大大简化了 Hadoop 集群操作和管理。目前已经成为 Cask 数据应用平台(CDAP)背后的关键组件,使用 YARN 容器和 Java 线程作为抽象化处理。CDAP 是一个开源集成和应用平台,使开发人员和组织能够轻松构建,在 Hadoop 和 Spark 上部署和管理数据应用。

5、Apache Kudu
Apache Kudu 是 Cloudera 主导开发的数据存储系统,2015年12月3日成为 Apache 孵化项目,2016年7月25日正式宣布毕业,升级为 Apache 顶级项目。
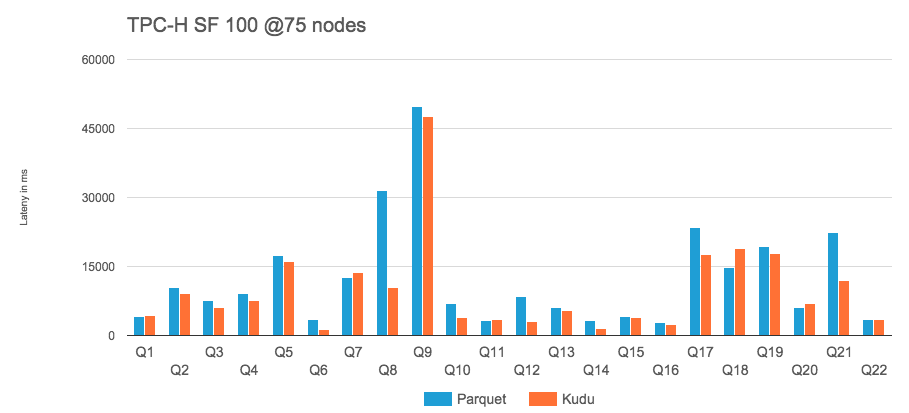
Apache Kudu 是为 Hadoop 生态系统构建的开源列式存储引擎,旨在实现灵活的高性能分析管道。它支持在传统数据库中提供许多操作,包括实时插入、更新和删除等。目前在许多行业的不同公司和组织中使用,包括零售、在线服务交付、风险管理和数字广告等等行业,还有大家较为熟悉的有小米公司。
6、Apache Bahir
Apache Bahir 的代码最初是从Apache Spark 项目中提取的,后作为一个独立的项目提供,并于2016年6月29日宣布成为 Apache 顶级项目。
Apache Bahir 通过提供多样化的流连接器(streaming connectors)和 SQL 数据源扩展分析平台的覆盖面,最初只是为Apache Spark 提供拓展,目前也为 Apache Flink提供,后续还可能为 Apache Beam和更多平台提供拓展服务。

7、Apache Zeppelin
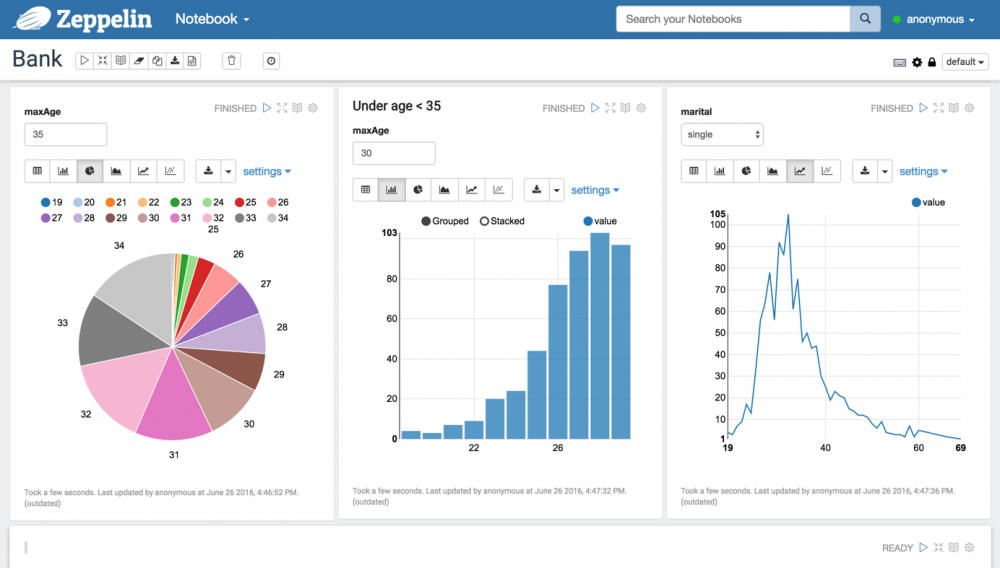
Apache Zeppelin 是一个支持交互式数据分析的基于 Web 的 notebook,提供了数据可视化的框架。2013年在 NFLabs 作为商业数据分析产品 Peloton 面世,2014年12月23日进入 Apache 孵化器,2016年5月25日毕业为 Apache 顶级项目。
Apache Zeppelin 帮助开发人员高效处理数据,而不必担心命令行和群集详细信息。支持20多个后端系统,易于部署和使用,允许用户混合不同的语言,在后端之间交换数据,调整布局,也允许自定义可视化和集群资源之间的交互。你可以使用 SQL、Scala 等创建漂亮的数据驱动、交互式和协作文档。
8、Apache TinkerPop
Apache TinkerPop 2009年始于洛斯阿拉莫斯国家实验室,在发布过2个版本后,于2015年1月16日提交给 Apache 孵化器,并于2016年5月23日毕业为 Apache 顶级项目。
Apache TinkerPop 是一个图形计算框架,为开发人员提供在任何应用程序领域构建任何规模的现代图形应用程序所需的工具。它统一了这些高度变化的图形系统模型,加快开发时间,既可用于联机事务处理(OLTP),又可用于联机分析处理系统(OLAP);既可处理单一机器的数据,也可处理分布式环境的庞大数据。

9、Apache Apex
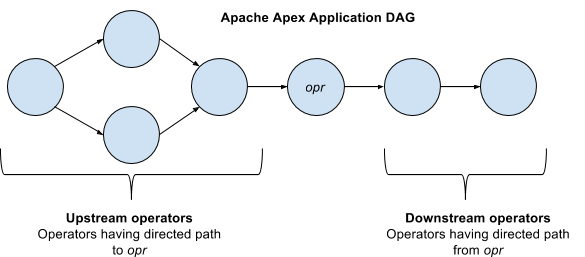
Apache Apex 最初于2012年在 DataTorrent Inc. 创建,2015年8月17日进入 Apache 孵化器,2016年4月25日正式宣布毕业为 Apache 顶级项目。
Apache Apex 是一个企业级的统一流和批处理引擎。提供高度可伸缩、高性能、容错、有状态、安全和分布式的大数据处理,同时操作起来非常简单容易。其目的在于充分利用 Hadoop 的两大组件 YARN 和 Hadoop 分布式文件系统(HDFS)提供的基础设施,通过企业级平台对 Apache Hadoop 进行流式分析。
10、Apache Sentry
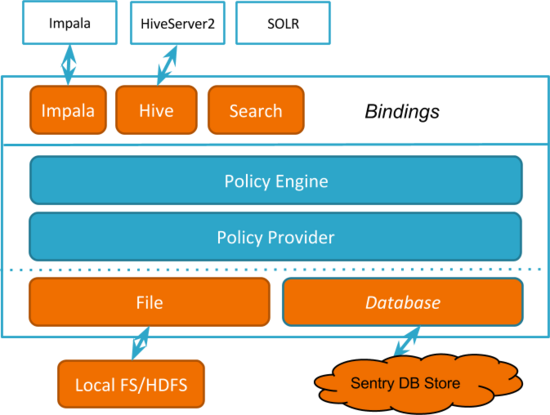
Apache Sentry 为 Hadoop 集群元数据和数据存储提供集中、细粒度的访问控制,2013年8月成为 Apache 孵化项目,2016年3月25日毕业为 Apache 顶级项目。
Apache Sentry 是一个加强的细粒度的基于角色的授权系统,对不同的 Hadoop 组件提供了六类对权限访问策略管理。包括:支持多权限模型,也支持同一个权限控制策略对多哥计算框架和数据目录的访问;支持Apache Solr(搜索项目);支持 SQL 表权限和 HDFS 文件权限同步;支持数据管理的审计日志;支持高可用性(HA);支持不同集群间权限策略的导入和导出等等。
11、Apache Arrow
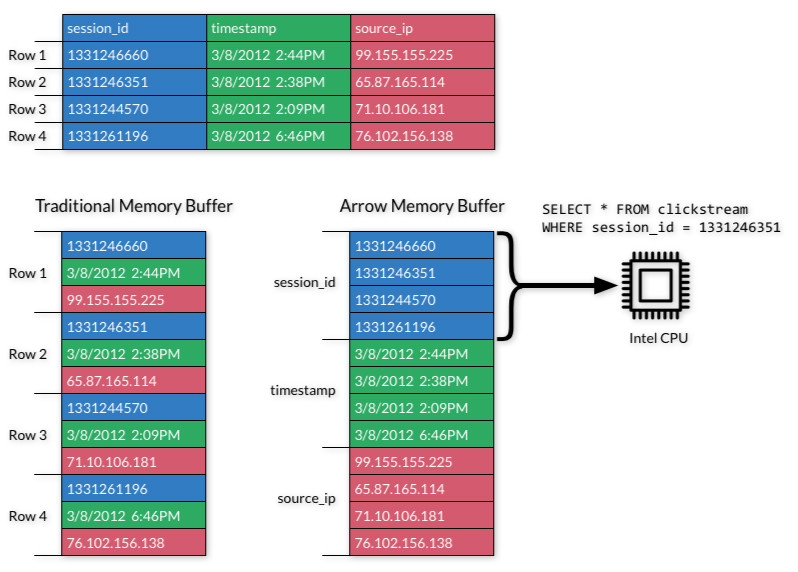
Apache Arrow 最初是基于Apache Drill 项目的代码进行开发的,它是在许多开源协作的基础上构建的,为列式内存存储的处理和交互提供了规范,于2016年2月17日毕业成为 Apache 顶级项目。
Apache Arrow 通过提供高性能的列式内存表示来加速分析处理。许多处理算法从该存储器设计中获益良多。除了传统的关系数据,Arrow 还支持具有动态模式的复杂数据。例如,可以处理通常用于 IoT 工作负载、现代应用和日志文件中的 JSON 数据,也可以允许在大量大数据解决方案之间实现更强的互操作性。
责编:开源中国–王练
转载须在正文中标注并保留原文链接和作者等信息
正文到此结束
- 本文标签: 2015 云 https HDFS 大数据 智能 开源 删除 高可用 质量 集群 开源项目 Apache Hadoop 性能问题 分布式 Hadoop 产品 数据 Apache Drill 开发 http 希望 文件权限 线程 UI CTO 小米 ask 文件系统 web 广告 基金 时间 软件 src MQ apache 数据库 金融 代码 组织 solr IO java sql Google ebay 企业 scala 目录 js 安全 管理 json 同步
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

