深度解读:GAN模型及其在2016年度的进展
雷锋网 (公众号:雷锋网) 注:本文作者杨双,于2016获中国科学院自动化研究所博士学位。现任中国科学院计算技术研究所智能信息处理重点实验室助理教授。主要研究方向包括深度学习、贝叶斯建模与推理、序列建模等。
GAN,全称为Generative Adversarial Nets,直译为生成式对抗网络。它一方面将产生式模型拉回到了一直由判别式模型称霸的AI竞技场,引起了学者甚至大众对产生式模型的研究兴趣,同时也将对抗训练从常规的游戏竞技领域引到了更一般领域,引起了从学术界到工业界的普遍关注。笔者对几大会议等进行了不完全统计,其中:
ICLR-2017提交论文:45篇产生式模型相关,37篇与对抗训练相关;
NIPS-2016:在会议大纲中GAN被提及超过120次;同时,会议专门针对“Adversarial Training”组织了一个workshop,收录了32篇文章,绝大多数与GAN直接相关;此外,正会还收录了17篇产生式模型相关文章,11篇对抗训练相关文章;
Arxiv:在Computer Science分类下约有500篇与对抗网络相关文章,其中绝大多数为2016年的工作;
相信接下来偏重实际应用的CVPR-2017与ICCV-2017也会有一大波视觉上应用和改进GAN的文章来袭......
除了学术圈外,谷歌、Facebook、Twitter、苹果、OPENAI(GAN作者所在公司)等众多工业界AI相关的公司也都在今年发表了数量不一的基于GAN的相关研究成果。
那么问题来了,GAN在2014年就被提出,为什么不是在2014年或2015年火爆?为什么是2016呢?个人觉得GAN的对抗训练理论和它利用这一点来构建产生式模型的概念一直都很吸引人,但它刚提出之时对模型的实际训练中所遇到的许多问题都还没有得到很好的解决(当然,现在也仍然有许多问题),但经过2014和2015大半年的酝酿,到15年下半年和16年初就逐渐开始出现许多GAN的训练技巧总结分享以及对模型本身进行改进的文章,这些都极大地带动了后续的发展,特别是在数据生成等相关问题中的应用,造就了2016年对于产生式模型以及对抗训练的研究热潮。
解读GAN
一、基本的GAN模型
1、基本框架

原始GAN模型的基本框架如上图所示,其主要目的是要由判别器D辅助生成器G产生出与真实数据分布一致的伪数据。模型的输入为随机噪声信号z;该噪声信号经由生成器G映射到某个新的数据空间,得到生成的数据G(z);接下来,由判别器D根据真实数据x与生成数据G(z)的输入来分别输出一个概率值或者说一个标量值,表示D对于输入是真实数据还是生成数据的置信度,以此判断G的产生数据的性能好坏;当最终D不能区分真实数据x和生成数据G(z)时,就认为生成器G达到了最优。
D为了能够区分开两者,其目标是使D(x)与D(G(z))尽量往相反的方向跑,增加两者的差异,比如使D(x)尽量大而同时使D(G(z))尽量小;而G的目标是使自己产生的数据在D上的表现D(G(z))尽量与真实数据的表现D(x)一致,让D不能区分生成数据与真实数据。因此,这两个模块的优化过程是一个相互竞争相互对抗的过程,两者的性能在迭代过程中不断提高,直到最终D(G(z))与真实数据的表现D(x)一致,此时G和D都不能再进一步优化。
我们若对这个过程直接建模,应当是如下的minimax问题(我将其称为朴素minimax问题):
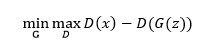
但是,原文中的目标函数却为如下形式:
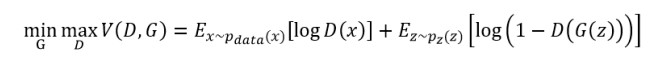
可以看到,GAN的目标函数与朴素minimax问题相比,主要多了三个变化:
-
(1) 加入了求对数操作:求对数的操作在理论上并不会影响最终收敛到的最优值,但对数算子的变换可以缓解数据分布偏差问题,比如减少数据分布的单边效应的影响,减少数据分布形式上的波动等,同时在实际的程序实现中,对数算子也可以避免许多数值问题,因此成为统计学中的常用做法,比如在许多问题中我们并不直接求最大似然,而是去求最大对数似然也是类似的原因;
-
(2) 加入求期望的操作:这一点是由于我们的最终目的是希望生成数据的分布Pg(G(z))能够与真实数据的分布Pdata(x)一致,换句话说,相当于在数据量无限的条件下,通过拟合G(z)得到的分布与通过拟合x得到的分布尽量一致,这一点不同于要求各个G(z)本身和各个真实数据x本身相同,这样才能保证G产生出的数据既与真实数据有一定相似性,同时又不同于真实数据;
-
(3) -D(G(z))变成了1-D(G(z)):直观上来说,加了对数操作以后,要求logf的f必须是正数,所以不能直接用-D(G(z)),这一点并不影响最终的最优解。
2、理论保证
GAN除了提供了一种对抗训练的框架外,另一个重要贡献是其收敛性的理论证明。
作者通过将GAN的优化过程进行分解,从数学推导上严格证明了:在假设G和D都有足够的capacity的条件下,如果在迭代过程中的每一步,D都可以达到当下在给定G时的最优值,并在这之后再更新G,那么最终Pg就一定会收敛于Pdata。也正是基于上述的理论,原始文章中是每次迭代中优先保证D在给定当前G下达到最优,然后再去更新G到最优,如此循环迭代完成训练。这一证明为GAN的后续发展奠定了坚实基础,使其没有像许多其它深度模型一样只是被应用而没有广而深的改进。
3、改进方向
原文只针对框架本身进行了理论证明和实验验证,表明了GAN的理论基础及其有效性,而对于其中的许多细节并没深究(相当于开采了一个大坑等人来填),比如文章中的输入信号只是随机噪声,比如原文中的G和D都只是以最简单的MLP来建模;另外,作者在文章结尾还列出了该模型可以改进的5个参考方向,进一步为后来逐渐广泛的研究做了铺垫。作者给出的参考方向主要包括:
-
(1) 将GAN改进为条件产生式模型:这一点最早在GAN公开后的半年就得到了部分解决,即conditional GAN(ARXIV-2014)的工作,该模型实现了给定条件的数据生成,但现在在各个领域特别是图像和视频相关的生成工作中,也依然有许多对于给定条件生成数据的任务的相关改进与研究;
-
(2) 改进输入z:不直接用随机噪声信号,而是可以用其它网络根据真实数据x学习一个z,然后再输入G,相当于是对数据x做了一个编码;这一点目前基本上在多数基于GAN的应用中都被采纳;
-
(3) 对条件分布建模,由已有数据预测未出现的数据:往这个方向改进的相关工作相对出现较晚,直到2016年才逐步开始有相关工作出现;
-
(4) 半监督学习:在2015年年底出现了将GAN用于半监督问题的工作;另外,现有的许多GAN工作也都表明通过加入少量类别标签,引入有标签数据的类别损失度量,不仅功能上实现了半监督学习,同时也有助于GAN的稳定训练;
-
(5) 提升GAN的训练效率:目前比GAN的训练效率更加要紧的训练稳定性问题还没有得到很好的解决,因此相对来说,目前这一点的研究并不广泛,而且相比较其它的产生式模型而言,GAN的速度也不算是一个非常“拖后腿”的点。
除了作者给出的以上几个参考方向外,目前GAN在计算机视觉中的超分辨率图像生成、视频帧的生成、艺术风格迁移等问题中都得到了广泛关注。
二、GAN相关工作对比
我们这里主要对比两类工作,一类是像GAN一样将产生器与判别器联合学习的工作,另一类是深度学习领域中当前应用比较多的深度产生式模型:
对比1:产生器与判别器联合学习的相关工作
在传统的机器学习领域,很早就引入了将判别式模型与产生式模型进行联合学习的想法,比如Tony Jebara早在2001年的毕业论文中就以最大熵的形式将判别式模型与产生式模型结合起来联合学习;2007年UC的Zhuowen Tu也提出将基于boosting分类器的判别器与基于采样的产生式模型相结合,来产生出服从真实分布的样本;2012年清华的Jun Zhu老师发表在JMLR上的工作,则是将最大间隔机制与贝叶斯模型相结合进行产生式模型的学习。与这些模型相比,GAN更加迎合了当下大数据的需求和深度学习的热潮,并且更重要的是它给出了一个大的框架而不是一个具体的模型;
对比2:其它同类深度产生式模型工作
-
GAN与VAE:VAE中模型性能的好坏直接依赖于其假设的近似分布q的好坏,对于q的选择需要一定的经验信息;并且受变分方法本身的限制,其最终模拟出的概率分布一定会存在有偏置,而GAN本身则不存在这个问题,且其原则上可以渐进的逼近任意概率分布,可以认为是一种非参数的产生式建模方法;
-
GAN与Pixel RNN/CNN:pixel RNN中是将图像的生成问题转化为像素序列的预测和生成问题,因此需要对每个像素逐个操作,而GAN是直接对整幅图像进行衡量、评价和生成,因此相对来说考虑了整体信息且速度相对较快。
这里主要是从GAN的优点的角度来进行对比的,但GAN模型也存在有不如其它模型的地方,比如目前的最大缺陷是其训练过程中的稳定性和收敛性难以保证,在2016年有许多相关工作都在尝试解决其训练稳定性问题。
GAN在2016年的部分进展
GAN在2016年得到了几乎全方位的研究,包括其训练技巧与模型架构改进,理论扩展与实际应用问题等多个角度,都有大量成果出现,难以全部一一列出。下面仅选取其中较为突出的或者被广泛关注和研究的部分工作进行介绍。
一、理论框架层面扩展与改进
对GAN模型的理论框架层面的改进工作主要可以归纳为两类:一类是从第三方的角度,而不是从GAN模型本身,来看待GAN并进行改进和扩展的方法;第二类是从GAN模型框架的稳定性、实用性等角度出发对模型本身进行改进的工作。
1、以第三方角度看待GAN的两个典型工作:
f-GAN与EBGAN,一个从距离度量的角度出发,一个从能量模型的角度出发,分别对GAN进行阐释和改进,非常有助于我们对GAN做出新的理解:
-
(1) f-GAN (NIPS-2016):该文提出了一种f-divergence,并证明了GAN只是在f-divergence取某种特定度量时的特殊情况。这个f-divergence包括了常见的多种概率分布的距离度量,比如KL散度、Pearson散度等。具体来说,作者将GAN的优化问题求解中的步骤进行分解,将真实数据分布的估计问题转化为某种divergence的最小化问题,而这个divergence就正是作者定义的f-divergence的一种特例。最后,作者利用GAN模型框架结合不同度量条件,即不同divergence进行图像生成。其中,在选择KL散度的度量方式时,对比结果如下图所示,可以看出两者的效果其实相差不大。

-
(2) EBGAN (ICLR-2017,submitted) : EBGAN [6]是Yann LeCun课题组提交到ICLR2017的一个工作,从能量模型的角度对GAN进行了扩展。EBGAN将判别器看做是一个能量函数,这个能量函数在真实数据域附近的区域中能量值会比较小,而在其他区域(即非真实数据域区域)都拥有较高能量值。因此,EBGAN中给予GAN一种能量模型的解释,即生成器是以产生能量最小的样本为目的,而判别器则以对这些产生的样本赋予较高的能量为目的。
从能量模型的角度来看待判别器和GAN的好处是,我们可以用更多更宽泛的结构和损失函数来训练GAN结构,比如文中就用自编码器(AE) 的结构来作为判别器实现整体的GAN框架,如下图所示:
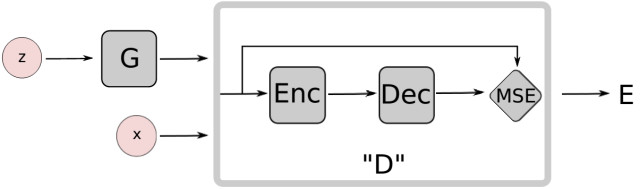
在训练过程中,EBGAN比GAN展示出了更稳定的性能,也产生出了更加清晰的图像,如下图所示。

2、Info GAN模型
接下来,从GAN网络本身出发而对GAN进行改进并且取得了良好效果的一个重要工作,就是大名鼎鼎的Info GAN模型。它以成功习得数据的disentangled的表示和拥有稳定的训练效果而受到广泛关注:
Info GAN (NIPS-2016)是OPENAI对GAN的一个重要扩展,被认为是OPENAI去年的五大突破之一。原始的GAN模型通过对抗学习最终可以得到一个能够与真实数据分布一致的模型分布,此时虽然模型相当于已经学到了数据的有效语义特征,但输入信号z中的具体维度与数据的语义特征之间的对应关系并不清楚,比如z中的哪些维度对应于光照变化或哪些维度对应于pose变化是不明确的。而infoGAN不仅能对这些对应关系建模,同时可以通过控制相应维度的变量来达到相应的变化,比如光照的变化或pose的变化。
其思想是把输入噪声z分成两个部分:不可压缩的噪声信号z和可解释的有隐含意义的c。比如对于mnist手写数字来说,c可以对应于笔画粗细、图像光照、字体倾斜度等,用C1,C2,…,CL表示,我们称之为latent code,而z则可以认为是剩下的不知道怎么描述的或者说不能明确描述的信息。此时生成器的输出就从原来的G(z)变成了G(z,c);在学习过程中,为了避免学到一些trivial的latent code而忽略了重要的code,文章对原始的GAN目标函数加了一个约束,即约束latent code c和生成器的输出G(z,c)之间的互信息I(c;G(z,c))越高越好,以此希望能学到比较重要的有意义的codes c,从而此时的目标函数即为:
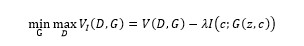
在具体的优化过程中,作者采用变分推断的思想,引入变分分布来逼近真实分布,并与最优互信息下界的步骤轮流迭代进行,实现最终的求解。
在实验中,作者通过只改变latent code c中的某一个维度,来观察生成数据的变化。其实验确实证明:latent code确实学到了一些维度,如对应于图像的角度或光照的因素,也即说明InfoGAN确实学习到了数据中的disentangled的可解释部分的表示。其效果参考下图。
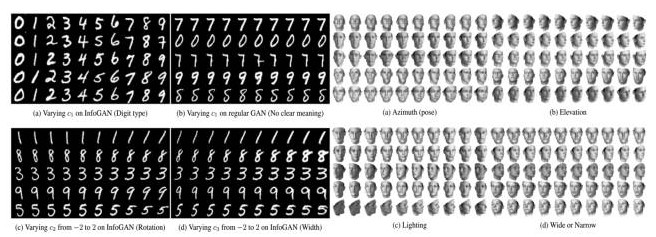
3、改进方向
-
另外一种从GAN模型本身出发进行改进的工作是将GAN与其它模型结合,综合利用GAN模型与其它模型的优点来完成数据生成任务。
比如ARXIV-2016上将GAN与RNN进行结合,ICML-2016上的提出的将GAN与VAE的思想相结合的工作等,这里以GAN+VAE (ICML-2016) 为例进行介绍:
虽然在第一个部分我们强调了GAN与VAE的不同,但这两者并不是完全冲突的,工作从另一个角度将两者结合到了一起。主要是作者利用GAN中的判别器学习到的特征来构建VAE的重构误差,而不采用常规的VAE中的像素级的误差,其结构如下图所示。
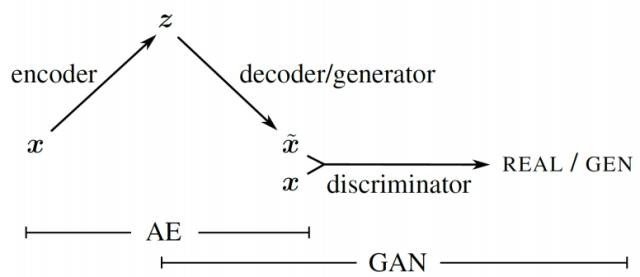
在上面的框架中,我们可以把前两个部分 (encoder + decoder/generator) 看做一个产生式模型的整体,从而和最后一个部分 (discriminator) 构成了扩展的GAN模型;也可以将最后两个部分 (decoder + discriminator) 看做是一个整体,其中discriminator的存在看做是用于替换原来的element-wise的重构误差的计算,相当于对decoder的一个辅助,从而此时整个模型架构可以看做是一个自编码器。因此整体上来说,该模型综合了VAE与GAN两种模型的优点,属于将GAN与其他方法结合的一个代表性工作。
-
最后一种改进,是从GAN本源出发,对GAN进行半监督形式的扩展,这类工作目前的做法都大同小异,通过引入类别损失来进行GAN的学习。
这里以CatGAN (ICLR-2016) 为例进行说明:通常无监督的分类方法会被转化为一个聚类问题,在判别式的聚类方法中通常是以某种距离作为度量准则,从而将数据划分为多个类别,而本文则是采用数据的熵来作为衡量标准构建来CatGAN (ICLR-2016) 。具体来说,对于真实的数据,模型希望判别器不仅能具有较大的确信度将其划分为真实样本,同时还有较大的确信度将数据划分到某一个现有的类别中去;而对于生成数据却不是十分确定要将其划分到哪一个现有的类别,也就是这个不确信度比较大,从而生成器的目标即为产生出那些“将其划分到某一类别中去”的确信度较高的样本,尝试骗过判别器。接下来,为了衡量这个确信程度,作者用熵来表示,熵值越大,即为越不确定;而熵值越小,则表示越确定。然后,将该确信度目标与原始GAN的真伪鉴别的优化目标结合,即得到了CatGAN的最终优化目标。

对于半监督的情况,即当部分数据有标签时,那么对有标签数据计算交叉熵损失,而对其他数据计算上面的基于熵的损失,然后在原来的目标函数的基础上进行叠加即得,当用该半监督方法进行目标识别与分类时,其效果虽然相对较优,但相对当下state-of-the-art的方法并没有比较明显的提升。但其基于熵损失的无监督训练方法却表现较好,其实验效果如下图所示,可以看到,对于如下的典型环形数据,CatGAN可以较好地找到两者的分类面,实现无监督聚类的功能。
二、模型改进(偏应用层面)
1、提到GAN在应用层面的改进,就不得不说perceptual similarity,该度量改变了以往的按照图像的像素级差异来衡量损失的情况,使模型更加鲁棒。在当下的多数图像生成以及视频数据处理等模型中都有将perceptual similarity加入考虑。
(1) Perceptual Similarity Metrics (NIPS-2016)
Perceptual Similarity Metrics 的主要贡献在于提出了一种新的度量,有助于使GAN产生清晰图像。其方法是将通常在原始图像空间的损失度量替换为在特征空间的损失度量。具体来说,在训练GAN时,除了原始GAN中的对抗训练损失,额外加入了两个损失项,共计三个损失项,分别为:
-
特征空间损失Lfeat:文章构建了一个比较器网络C,然后比较真实样本和产生的样本分别作为输入时,网络的特征图(feature map)的差异性,即
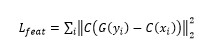
这里的一个问题是网络中间层的特征图的相似性,只能代表高层的相似性,会使产生出的相对低层的像素级数据出现畸形,因此需要加入图像的一些先验信息进行约束。而这个先验信息就通过对抗损失来体现,从而有了下面的对抗损失;
-
对抗损失:这里的对抗损失,即与生成器一起训练一个判别器,其中判别模块的目的是为了区分开产生数据与真实数据,而生成器的目的则是为了尽量的迷惑判别器,其数学形式与原始GAN损失相似,即
判别器D以最小化如下损失为目标:
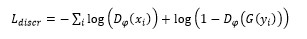
生成器G以最小化如下损失为目标:
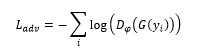
-
图像空间损失:用生成数据与真实数据的L2损失来表示,对像素层面的相似性进行约束,即为
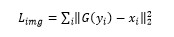
最终的目标函数为三个loss项的加权和。
其实验结果非常值得关注,因其清晰的表明了各个loss的作用,如下图所示。可以看出,如果没有对抗损失Ladv,产生的结果非常差;如果没有特征空间的损失项Lfeat,会使产生的图像只有大概的轮廓信息,但会丢失许多细节信息;如果没有图像空间损失Limg,最终产生的结果跟有Limg差不多,但在训练的时候没有这一项的话会使网络更容易不稳定;而同时利用三项loss的结果则可以相对稳定的产生出较为清晰的图像。目前该度量在许多基于GAN的模型中都得到了应用。

(2) 超分图像生成 (ECCV-2016; ARXIV-2016):
在与上述工作的几乎同时期(相差仅一个月),Li Fei-Fei团队也提出了类似的perceptual loss (ECCV-2016),通过网络中间层的特征图的差异来作为代价函数,利用GAN的框架,进行 风格迁移和超分图像的生成任务;
时隔约半年后,2016年9月Twitter的SRGAN基于上述损失,提出一种新的损失函数与GAN本身的loss结合,实现了从低分辨率图像到超分辨率图像的生成。SRGAN与上述NIPS-2016工作的主要不同是:(1) 将图像空间的损失替换成了一个对生成图像整体方差的约束项,以保证图像的平滑性;(2) 采用了某种规则化的特征图差异损失,而不是直接累加求和:SRGAN将生成数据和真实数据分别输入VGG-19网络,根据得到的feature map的差异来定义损失项,其形式与NIPS-2016的主要不同在于加入了规则化的处理 (normalization),从而变成:

其中Wij, Hij为feature map的宽和高,ϕ(i,j)表示在VGG-19的网络中第i个max pooling层前的第j个卷积层。最后,结合这三个损失项: 对抗损失、图像平滑项、特征图差异,送入GAN框架 ,可以生成相对其它方法明显效果好的超分辨率图像,其对比如下图所示:

2、常规的从噪声数据生成图像和给定属性产生图像的任务可以看做是从噪声到图(输入为噪声,输出为图像)和从图到图(输入为图像,输出为图像)的问题,而ICML-2016上的工作另辟蹊径,实现Image Captioning的反任务,即从文本描述生成图像。该文也是第一个提出用GAN的框架来实现从文本生成图像的工作,对于推动GAN以及产生式模型在实际中的进一步应用具有一定意义:
该文实现的任务是产生满足文本描述的图像,相当于是以文本描述为条件来产生图像,因此可以在某种程度上看做是对原始的conditional GAN模型(ARXIV-2014) 的一种扩展和应用。其模型架构如下图所示,将文本进行编码后的特征与随机噪声信息串接输入产生器产生图像;而编码后的文本特征也同时作为监督信号输入判别器以构建目标函数。
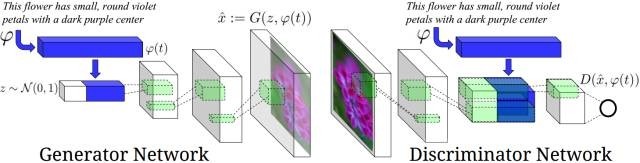
其效果也非常可观,如下图所示,可以看出,大部分时候都能产生出与文本意义相对应的图像。

3、在处理静态图像的生成任务的同时,GAN也逐渐被扩展到了视频处理领域,NIPS-2016上的[14]即为一个代表性工作,该工作可以同时生成和预测下一视频帧:
为了产生出具有时域变化的视频帧,该模型在生成器部分将动态前景部分和静态背景部分分开建模和生成,构建two-stream的样本生成器,然后将产生的前景和背景进行组合得到产生出的video;对于判别器,主要完成两个任务: 区分出产生数据与真实数据,同时要识别出视频帧间进行的行为,从而指导生成器去产生数据。 其结构如下图所示。
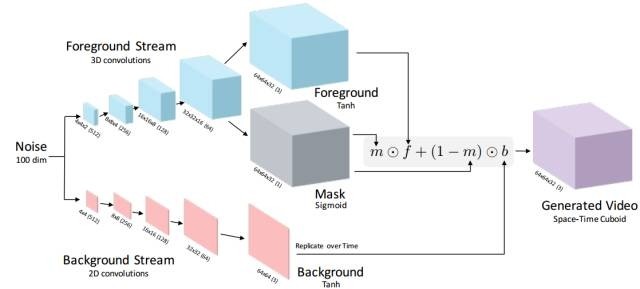
三、训练技巧
由于GAN的模型不稳定性问题比较突出,因而在2016年出现的关于GAN训练技巧的成果有许多,目前被广泛应用的主要包括:DCGAN (ICLR-2016) 和Improved GAN (NIPS-2016 workshop),特别是DCGAN,几乎在各大GAN模型中都能看到它的身影。
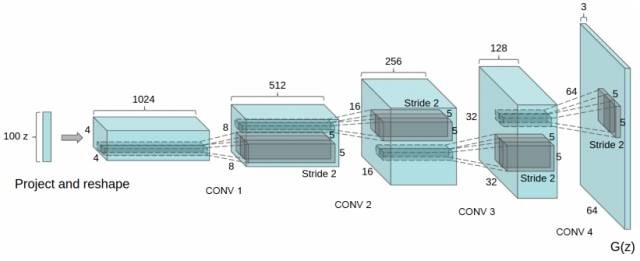
1、DCGAN (ICLR-2016):
DCGAN 的模型结构如上图所示,其输入为100维的噪声向量,经过一系列的strided conv操作,形成64x64的图像,即为G(z),而判别器结构与之类似,只是是由一系列的卷积操作构成 (而非strided conv),最后由average pooling形成判别器的标量输出。在本文中,最主要的是提出了以下三条有助于稳定训练GAN的方法:
-
(1) 去掉max pooling操作:用strided conv代替原来的pooling操作,使网络自动学习合适的采样核函数;
-
(2) 去掉全连接层:用global average pooling代替全连接层;虽然该操作可能会导致收敛速度变慢,但有助于整体训练的稳定性;
-
(3) 加入BN层:之前的LAPGAN (NIPS-2015) 指出如果像常规模型一样对所有层都施加BN,则会引起GAN的模型崩溃,而DCGAN通过对generator的输出层和discriminator的输入层不用BN,而其他层都用BN,则缓解了模型崩溃问题,并且有效避免了模型的振荡和不稳定问题。
-
(4) 激活函数的选择:在generator中除了输出层用tanh外,其余都用RELU函数;而在discriminator中采用leaky ReLU函数。
目前前三点已几乎成为当下诸多GAN模型实现的标配;而许多基于GAN模型的实验设计也都是基于DCGAN的结构或总结的上述原则而进行的,包括前面OpenAI的Info-GAN、NIPS-2016的视频生成模型、Twitter的超分辨率的图像生成模型等等。
2、Improved GAN (NIPS-2016 workshop):
该工作主要给出了5条有助于GAN稳定训练的经验:
-
(1) 特征匹配:让生成器产生的样本与真实样本在判别器中间层的响应一致,即使判别器从真实数据和生成数据中提取的特征一致,而不是在判别器网络的最后一层才做判断,有助于提高模型的稳定性;其实验也表明在一些常规方法训练GAN不稳定的情况中,若用特征匹配则可以有效避免这种不稳定;
-
(2) Minibatch Discrimination:在判别器中,不再每次对每一个生成数据与真实数据的差异性进行比较,而是一次比较一批生成数据与真实数据的差异性。这种做法提高了模型的鲁棒性,可以缓解生成器输出全部相似或相同的问题;
-
(3) Historical Averaging:受fictitious play的游戏算法启发,作者提出在生成器和判别器的目标函数中各加一个对参数的约束项
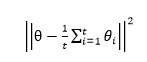
其中θ[i]表示在时刻i的模型参数,该操作可以在一些情况下帮助模型达到模型的平衡点;
-
(4) 单边标签平滑 (One-sided Label Smoothing):当向GAN中引入标签数据时,最好是将常规的0、1取值的二值标签替换为如0.1,0.9之类的平滑标签,可以增加网络的抗干扰能力;但这里之所以说单边平滑,是因为假设生成数据为0.1而非0的话会使判别器的最优判别函数的形状发生变化,会使生成器偏向于产生相似的输出,因此对于取值0的标签保持不变,不用0.1一类的小数据替换,即为单边标签平滑;
-
(5) Virtual Batch Normalization:VBN相当于是BN的进阶版,BN是一次对一批数据进行归一化,这样的一个副作用是当“批”的大小不同时,BN操作之后的归一化常量会引起训练过程的波动,甚至超过输入信号z的影响(因z是随机噪声);而VBN通过引入一个参考集合,每次将当下的数据x加入参考集合构建一个新的虚拟的batch,然后在这个虚拟的batch上进行归一化,如此可以缓解原始BN操作所引起的波动问题。
3、Github资源:
针对GAN训练过程的不稳定问题, Soumith等人在github上专门总结了一个 文档 (点击可看),总结了17种可以尝试的方法,可以为多数训练过程提供参考。
总结
本文主要列出了2016年中部分较有代表性或应用较为广泛的工作,而实际上,在过去一年里对于GAN的扩展和改进工作还有许多,包括GAN与其他方法如强化学习的融合、GAN在半监督学习领域的扩展等都值得关注。
GAN提供的不仅仅是单一的某个模型,而是一种框架,从这个角度来说,GAN可以与许多其它方法进行融合,在GAN的框架下进行融合;但目前GAN的训练稳定性问题仍未能很好地解决,甚至Ian J. Goodfellow自己也认为相对于GAN的稳定性问题而言,GAN新架构的开发反而显得关系不大;同时GAN也面临着一个稍许尴尬的问题,即缺乏客观评估,其产生样本的质量好坏仍然依赖人眼去判断。另外,从应用的角度来说,目前多数方法都是在GAN原始框架的基础上稍作修改,比如修改损失函数,或者在条件GAN或LAPGAN的基础上改进,但目前并没有一个具有突破性压倒性的图像生成模型,可能这也和GAN缺乏客观的评估指标有关;综合这些问题,GAN还有很长的路可以走......
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

