UC Berkeley最新研究:残差神经网络的可视化

摘要
当前 ImageNet 计算机视觉识别挑战的最前沿的技术是残差神经网络(residual network)。如利用快捷连接(shortcut connection)的研究方法已经在残差网络和 highway network 的衍生模型中得到大量应用。这些研究潜在地挑战了我们对 CNN 学习浅层(layer)的局部特征(local feature)与深层越来越多的全局特征(global feature)的认识。通过定性可视化和经验性分析(empirical analysis),我们探索了残差跳跃连接(residual skip connection)的意义。正如预期判断,我们的评估显示残差快捷连接能够强制图层来精炼(refine)特征。我们还提供了另一种可视化表达方式,进一步证明了残差网络大体上能学习已知的 CNN 所具有的直观功能。
1.导语
2015 年,深度残差网络在 ILSVRC 分类比赛中获得了第一名。我们尝试理解启发何恺明等人使用快捷连接和恒等映射(identity mapping)的网络架构的定性特征。为此,我们可视化了 2 幅残差构造块(residual building block)之后的特征图:一幅是最大化地激活了给定通道中的单元(unit)的前 9 个图像组,另一幅是对应的激活单元所用的有导向的反向传播(guided backpropagation)的可视化。
从这些可视化可以直观地证明何恺明等人的判断,即从预处理层(preconditioning layer)到恒等映射是有帮助的,并且与恒等映射相关函数更容易学习得到。特别的是,我们观察到相同维度的残差层学习得到的特征更加精炼和锐化。
1.1 相关研究
Zeiler 等人在 AlexNet 特征上进行了相似的可视化,他们的研究引入了去卷积变换(deconvolutional transformation),其中包括了采取激活期望的单位进行可视化并通过一系列去卷积步骤向后反向移动。与从像素空间(pixel space)映射到特征空间(feature space)不同,去卷积变换是从特征空间映射到像素空间。为了通过最大池化(max-pooling)向后反向移动,进行了一个反池化(unpooling)步骤,其中被选择的单元作为正向传递 (forward pass) 中的最大单元被分配了反向传播的值。为了进行去卷积计算,使用与卷积层学习得到的相同的参数来进行转置卷积 (transposed convolution)(也称为分数跨度卷积/fractionally strided convolution)。最后,通过整流(rectification)反向移动,并做反向输入数据的整流。这种方法在像素空间中构建了对给定激活单元的贡献最大的图像部分的可视化。
建立在去卷积方法的基础上,Springenberg 等人开发了有导向的反向传播。有导向的反向传播是去卷积方法的改进,在向前路径中被整流为零的单位(因为它们具有负值)在去卷积通道中也被设置为零。这被证明在视觉上 Springenberg 等人的网络优于基于去卷积的可视化。
最后,Yosinski 等人使用各种方法将 AlexNet 可视化,包括以前的方法和优化来综合地生成最大激活图像
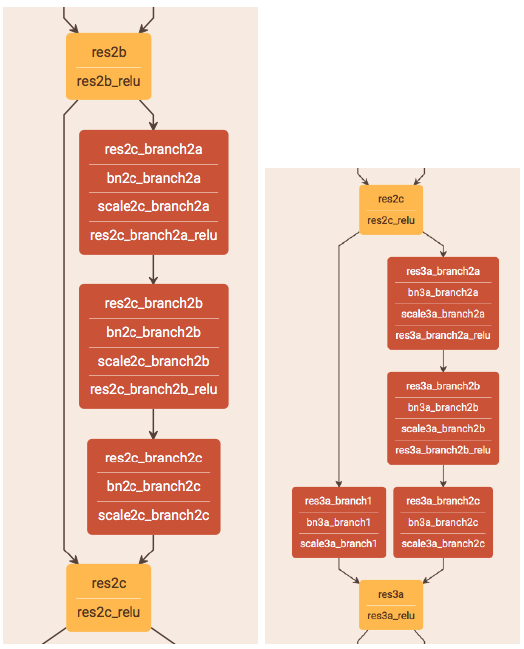
图 1:左侧:基本的 shortcut 模块。右侧:投影的 shortcut 模块
2 实验和架构
我们使用的 CNN 架构是预训练的 50 层残差网络。可以在线查看架构的可视化:
这种残差架构由单个卷积层(conv1)、一个最大池化层、一系列残差的快捷构建模块组成。如图 1 所示,有两种残差快捷模块。第一种由 1x1、3x3 和 1x1 的卷积层组成,一个快捷连接将每个输入数据添加到 1x1 卷积以及将输出添加到最终的 1x1 卷积。这决定了堆叠的 3 层网络向特性映射的转变。
第二种称为投影的快捷模块。它由相同的卷积层堆叠组成,现在除了 shortcut 还包含单个 1x1 卷积。
50 层残差架构由初始预投影块(2a)、两个基本块(2b,2c)组成。下面还含有一个投影块(3a)和一系列基本块(3b,3c)。该架构方式重复两次或更多次(4a,4b,4c,4d,4e,4f。以及:5a,5b,5c)。
另外两个差异与投影的快捷模块相关:由于步长(stride)为 2 同时信道(channel)数量增加,空间维度有所减小。这意味着以相同编号命名的构件块(building block)(例如 2a,2b 和 2c)包含相同数量的输出信道。
对于我们的可视化,我们使用 Yosinski 等人的代码,并分别针对残差网络和有导向的反向传播修改编程代码,使它应用于有导向的反向传播而不是反卷积。
为了获得每个最大激活单元的前 9 个图像,我们使用 ImageNet 的验证集。在所有空间维度以及数据集的所有图像中,具有最高激活值的单位才能被可视化。这意味着给定过滤器的可视化是特定空间单位的可视化(例如,在信道的特征图中的位置)。

图 2:Res2a 特征的可视化(随机选择)。从左到右,从上到下:信道分别为 12、79、150 和 210。对于每个信道,左边的图是前 9 个图像块。右边的图是相应的有导向的反向传播的可视化。大的灰色边界是由于不同的接受区域(receptive field)大小(根据边距/padding)

图 3:res2b 和 res2c 特征的可视化。与图 2 有相同的过滤器
为了可视化该最大激活单元,我们将图像传送到该单元所在的层,同时将该层中的所有其它激活单元归零,然后使用有导向的反向传播向后传递该层。当可视化前 9 个图像时,我们选择单元的接受区域对应的图像块(patch)。
3 结果及分析
在图 2 及图 3 中,我们对 2a、2b、2c 的构建模块(res2a、res2b、res2c)的通道进行了可视化。滤镜 12 看起来能够识别复杂的线性模型,在 res2b 中的判别力有所提升,在 res2c 中的判别力进一步有轻微增加。滤镜 79 看起来并不能带来相当程度的改变,这与残差模块是特征映射预条件产物的直觉相符。滤镜 150 表现出了优化:在 res2a 中,它能够识别出轻微弯曲的黑色线条,不过在 res2b 及 res2c 中它开始识别环形及更为弯曲的线条。滤镜 120 似乎并不能在 res2a 中识别任何东西,但是突然就能在 res2b 及 res2c 中识别平行的线条。
在图 4 中,我们展示了一个对于特征优化的有趣的案例。在 res3a 中,它识别出了一个单独的光点。在 res3b 中,它识别出了在周边景物下的光点。res3c 中则更进一步。

图 4: 通道 400,在 res3a、res3b 及 res3c 中进行了可视化(从左到右,从上到下)。并非随机选择。

图 5: res5a 可视化(随机的)。从左到右、从上到下分别是:滤镜 7、149、1068 及 1620。放大以看到去卷积的细节
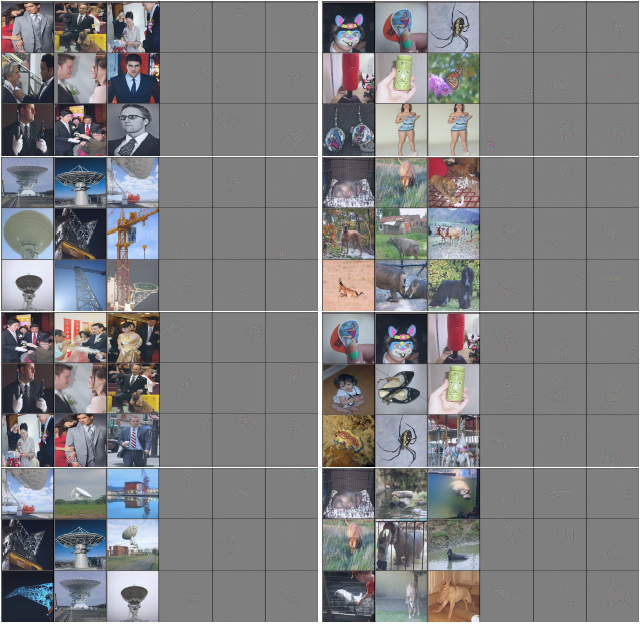
图 6: res5b 及 res5c 的特性。与图 5 中使用了相同的滤镜。放大以看到去卷积的细节
在图 5 及图 6 中我们随机的选择了四个滤镜进行可视化,它们全都表现出了优化的效果。滤镜 7 似乎能够识别穿着西装的人——因为在初始的 top-9 激活中有两个不是穿着西装的人,但是在 res5c 中全都是。在检查去卷积可视化后,我们证实了,这个特征并非必要地专注于识别婚礼场景,而它似乎专注于西服领子。滤镜 149 能够识别一种马赛克花纹,并具有小而明显的改进。滤镜 1069 似乎能够识别桁架结构,在一开始的时候还有香水瓶在它的 top-9 激活中,不过最后被卫星天线接收盘及吊车主导。滤镜 1620 一开始在带角的动物上激活,在 res5c 中这些激活被优化了。
在图 7 中,我们也选择了另一个关于物体识别优化的例子。在 res5a 中,通道 1660 在它的 top-0 激活中有一个双人自行车。在 res5b 中,相同通道被 6 个双人自行车最大化地激活。在 res5c——最后的拥有相同特性大小的残差模块中,所有的 top-9 输入都是双人自行车。我们猜测在分枝中的滤镜(如 res5b_branch2c 及 res5c_branch2c)能专注于特定的、能够改进特征发现的子特性。我们会看到,res5b_branch2c(通道 1660)锁定了有两个座位的自行车,而 res5c_branch2c 则在条幅上被激活。

图 7: 通道 1660 的在 res5a、res5b 及 res5c 的 top-9 激活图像(与中间层 res5b_branch2c 及 res5c_branch2c 一起)。在双人自行车上的激活(程度)成功提高。
4 额外成果
为了分析 ResNet 带来的好处,我们简单地研究了 AlexNet。AlexNet 并没有那些特征映射,所以我们通过比较最上的 9 个从 AlexNet 的 conv4 到 conv5 激活输入,来发掘在不同层的单元。与超过 1 个输入相匹配的单元很少,并且只有很少像残差网络一样清晰的优化样本。
在图 8 中我们也直接对 conv1 中的 kernel 进行了可视化,并发现它们与 AlexNet 十分相像。

图 8: conv1 kenerl 值的像素图
5 后续工作
在项目的进行过程中,我们一些想法因为时间及计算能力的限制而未能实现。但这些思路为之后的探究指明了方向
1. 在每个残差模块(例如在 res2a)内,我们并没有测试 1×1、3×3 加 1×1 的卷积(模式)。这是个特别有趣的尝试,因为首个 1×1 的卷积实际上对通道(内信息)进行了降采样,接着 3×3 的卷积保持了通道的维度,而最后的 1×1 又的通道进行了升采样(如:1024 道 → 256 道 → 256 道 → 1024 道)。对这种情况下的分支的、附加的特性进行可视化应该是有一定价值的。
2. 在跨越 res边界的过程中(如从 res3c → res4c),通道的数目翻倍,并且我们使用了一个映射创建模块(projection building block)(如 res4a)。因为在滤镜之间没有明显的对应关系,我们并没有对这些边界的情况进行可视化。也就是说,在 res4f 中的通道 60 并非映射到 res5a 中的通道 60。对高级概念的演化进行可视化、在其中发现对应(关系)也许是个有趣的过程。在一些初步的探索中我们发现,在前序层(如 res4f)中发现的属性,常常会在下一层中(如 res5f)有不止一个的对应特性(共享多重 top-9 激活模块),并且这些对饮的特性会随后分化。
3. 在过去的几个月里,何恺明等人对残差网络的架构进行了多项改进 [4]。我们能够量化地来评价这些改进。
4. 在见识了这些基于残差捷径的改进效果之后,我们也可以尝试使用这种属性来拓展现有的网络(架构)。我们估计,也许可以使用一个预训练过的 7 层 AlexNet 架构,在训练层前面及后面,插入具有相同通道维度的 0-初始化残差模块然后继续训练。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

