关于 TiDB 2016 技术上的总结和对 2017 年的一些想法
最
近 TiDB 又一次被国际友人顶上了 HackerNews 首页前十,大家讨论得热火朝天的。
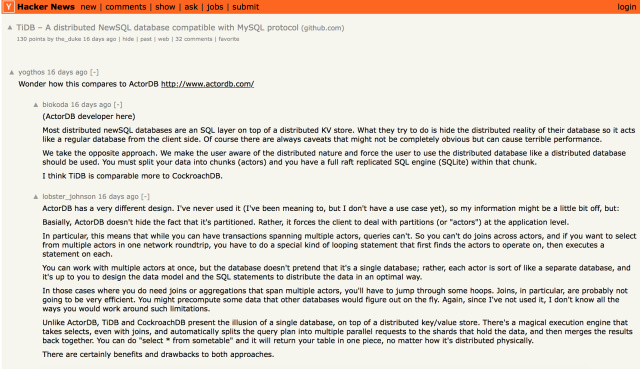
随即,TiDB RC1 发布的消息被德国最热的 IT geek 新闻网站 heise.de 报道;与此同时 TiDB 在 GitHub 上被推到了 Go Trending 的头条。
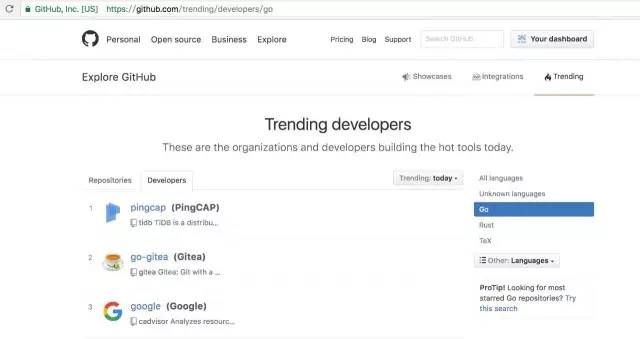
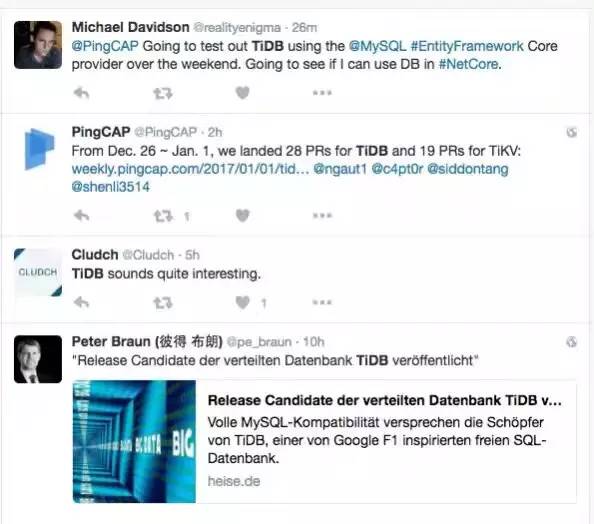
作为一个中国的数据库开源项目,这个趋势很让我们自豪。本文为 InfoQ 对黄东旭的约稿,复盘 TiDB 并回顾 2016 年的几个很重要的设计决定和 17 年想要做的方向。
TiDB 的 2016
TiDB 是一个大概开始了两年的项目,从最早的 3 个人到现在背后目前大约 30 多个活跃开发者,包括周边的工具和 CI ,可以说是一个凝结了我们大量心血的一个项目。这个项目的开始的起点是很高的,当时的想法是要么别做,要么就做到最好,当时(即使到了现在)全球社区内都没有一个令人满意的面向 OLTP 的分布式数据库,所以为什么不做?首先尽量能彻底的解决 MySQL 的扩展性问题,并发展出一个面向云时代的分布式关系型数据库的标准。
整个 TiDB 项目群从分布式存储到 SQL 优化器,除了底层的 RocksDB 外,其他都是以大规模的 Scale-out 为前提重新设计和实现,由于历史包袱比较小加上早期设计上的一些比较正确的决定,当然最主要也得力于非常强悍的各位 Committers,整个项目以非常惊人的迭代速度演进,2016 年 12 月底,正式发布了 RC1,此时已经达到了相当高的成熟度,也有不少用户已经将 TiDB 使用在了生产环境,也算是完成了对社区的承诺。回顾过去,最重要的设计决定我之前在我的朋友圈里也提到过,这里还是在赘述一下:

MySQL 语法和网络协议的兼容,这让我们得以吸收 MySQL 社区大量的测试用例,以保证高速迭代过程中的软件质量不至于失控,当然这个决定对于用户的推广也是很重要的。
高度模块化,这点可能就是和友商 CockroachDB 非常不一样的,我其实比较反感各种 P2P 模型,从 Codis 的设计与 Redis Cluster 差异就能看出来,去中心化也不一定就只有 P2P,从更宏观的抽象上来看,总是可以分层的,而且 P2P 模型带来的复杂度其实非常难以控制,虽然好处也是比较明显,就是部署的组件少了点,但是呢,比起后续的升级维护成本,牺牲掉的开发迭代速度来说,这个好处基本不值一提,更何况部署的问题有无数种方法可以解决,比如 TiDB 就有一键部署的方案。TiDB 的存储层每层接口抽象非常薄且清晰,不允许出现跨越层次的调用的情况,主要是为了控制复杂度和提高开发者的并发度。
编程语言的选择,Go 和 Rust,事后看来是对于我们这个团队来说最好的选择,虽然当时做这个决定也很艰难,回头看看确实也很大胆,但是我觉得我们还是基本做到了不带有任何个人感情色彩,一切通过数据和试验做出的判断。
极端严格的 Code Review、自动化测试、CI 流程,这个就不提了,在很多会议上提到过,之前刘奇也发了 3 篇文章说这个事情。(原文链接请点击: 分布式系统测试那些事儿——理念 ; 分布式系统测试那些事儿——错误注入 ; 分布式系统测试那些事儿——信心的毁灭与重建 )
接下来的目标
过去就不废话太多了,今天主要想聊的是未来,前段时间和褚霸聊天提到做数据库不易,特别对于公有云来说只要开了口子,无数用户就能玩出花来,大量的精力需要花在周边的各种旁路系统。对于创业的团队来说,做的又是一个关系型数据库这样的东西,能做的或者需要做的东西实在太多,如何控制住自己的欲望,专注在最重要的事情上面我认为是最重要的,这个看起来容易,但是做起来难,比如:
你的团队都是一些非常聪明的小朋友(老朋友),对于一个技术问题,总能发散出很多想法和特别聪明的解决办法,有的确实很惊艳,但是大多数时候,这样的方案并非最简洁同时最容易正确实现的,这时候就需要站出来狠狠拍掉,记住 make it right before making it faster,复杂性才是你最大的敌人。
你的一个客户说,实现 xx 功能或者接入 xx 系统,可能这个几百万的单就拿下了,你做还是不做?
我自认为,过去的一年多,在禁欲方面 TiDB 做得还是蛮不错的,目前 TiDB 已经在 469 个实例规模的集群上高压力稳定的运行,这个社区的友商们应该还没有能做到的,我们能承诺用户可以在生产环境安心使用,这个也是领先友商的,2017 年也要会保持,RC1 的发布标志着接口和功能的稳定,至少今年技术上的主要目标是进一步的性能优化,更高的兼容性以及更好的用户部署和使用体验,新功能开发和大规模的重构应该是不会发生的。
在性能优化上的一些想法,其实分两个比较大的方面,一个是 SQL 优化器方面,另一个是 KV 层的吞吐。
先说 SQL 优化器方面,其实在分布式 SQL 优化器方面,现在 TiDB 的优化器框架已经完成了几次大的重构,基于代价的优化器(CBO)框架已经有了,而且因为没什么历史包袱,所以 SMP 方面采用了很多比较新的优化技巧(可以参考 TiDB 的子查询优化,聚合下推等技巧),就目前线上用户的 case 来看,已经能解决我们目前见到的大部分问题,而且简单评估了一下现有的分布式数据库,优化器这边 TiDB 在 SQL 上的表现应该是属于最优秀的集团中。
2017 年的目标仍然是提高在 SMP 方面的能力,一方面尝试下推更多的算子,另一方面尝试分布式的 CBO,可能更好的解决索引选择和 join reordering 的问题,当然 CBO 这边还有很多理论上的问题需要解决,比如传统的直方图在分布式场景下就会有一些问题,我们也有一些改进的方法;另一方面在执行器方面,其实 TiDB 的潜力很大,目前在 OLAP 里面常用的 vectorized 和 codegen 等技巧,其实在 TiDB 里面还没有,这部分如果完成,对于大部分扫描,聚合的性能应该还能有若干倍的提升空间。
另一方面,TiDB 在 MPP 方面还比较谨慎,虽然这个是必经之路,但是我觉得目前还没有见到非 MPP 不可的场景,另外纯粹的 OLAP 场景也不是 TiDB 的目标,就像我一再强调的: TiDB 是一个 100% OLTP + 80% OLAP 的 Hybrid 的数据库,这 20% 的非得 MPP 解决的问题,我们会尝试接入 Spark SQL,并非简单的实现一个 connector, 而是在 TiKV 层面上去实现 Spark SQL 的算子,能让 Spark 高效的从 TiKV 按需加载数据和下推算子。这步完成后,应该能做到:一份存储,多个可插拔查询引擎(TiDB / Spark SQL),这部分完成后相信大部分 Hybrid 场景 TiDB 都能高效的解决,而且和 Spark 的对接能够让我们更加顺利的融入 OLAP 生态,这个应该会在 2017 年做。
另一方面,KV 层的吞吐提升也包含几个方面:
▲ Raft 状态机本身的优化,这个其实我们和 etcd 这边一直在合作,比如异步 log apply 等,目前已经在 2017 年初合并到 TiKV 主干,这个做完后,TiKV 的 raft store 的吞吐大概能有 30% 左右的提升。
▲ 事务模型,其实虽然理论上只有 2PC 一种搞法,而且目前来看 Percolator 的模型也没啥问题,但是针对不同的 Workload 其实还是有优化的空间,对于高并发底冲突的小事务和冲突率比较高的大事务,其实是有不同的优化策略在保证安全的情况下提升吞吐的,在这方面我有一些新的想法,以后有机会单独写一下。
▲ RocksDB,选择 RocksDB 简直太正确了,RocksDB 5.0 的优化很多都能对 TiKV 的用户直接受益,但是唯一有点不爽的是 RockDB 的 C API 的更新速度并没有 C++ 的 API 更新速度快,不过这个问题也不大,TiKV 这边会加一层 wrapper 来保证能够使用最新的 C++ API,另外一方面 rust 官方也正在对 C++ library 做更好的兼容。
▲ 硬件,这个是 2017 年我们一个很重要的尝试,我也会投很多精力在这个方面,软件层面的优化其实是比较有限的而且是有天花板的,可能费很大的精力换来 10% 的提升就很了不起了,但是现在我们正处于一个硬件快速变革的时间点,SSD、NVMe 、PCIe FPGA 已经进入大家的视野之中,可能硬件上的进步会能带来数量级的性能提升,这个是纯软件很难做到的。
最近看了一篇论文提到一个新的名词:In-Stroage Computing,我隐约觉得专有硬件加速可能也是基础软件未来的一个重要的趋势,虽然分布式系统一定是未来,但是性能这种东西是越高越好,也许原来 10 个节点的业务,现在通过硬件上的改进,结果只需要 3 节点就搞定了,也是一个可观的进步。今年我们会尝试将一些数据库逻辑在 FPGA 上实现,通过 PCIe 接口的板子提供针对数据库的硬件加速,另外我们也在和 Intel 合作,比如针对 Intel 的一些新型号的 CPU 的旁路 FPGA 芯片看看能否有什么优化的地方。

分布式 NewSQL 数据库
www.pingcap.com
 微信ID:pingcap2015
微信ID:pingcap2015
 长按左侧二维码关注
长按左侧二维码关注
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

