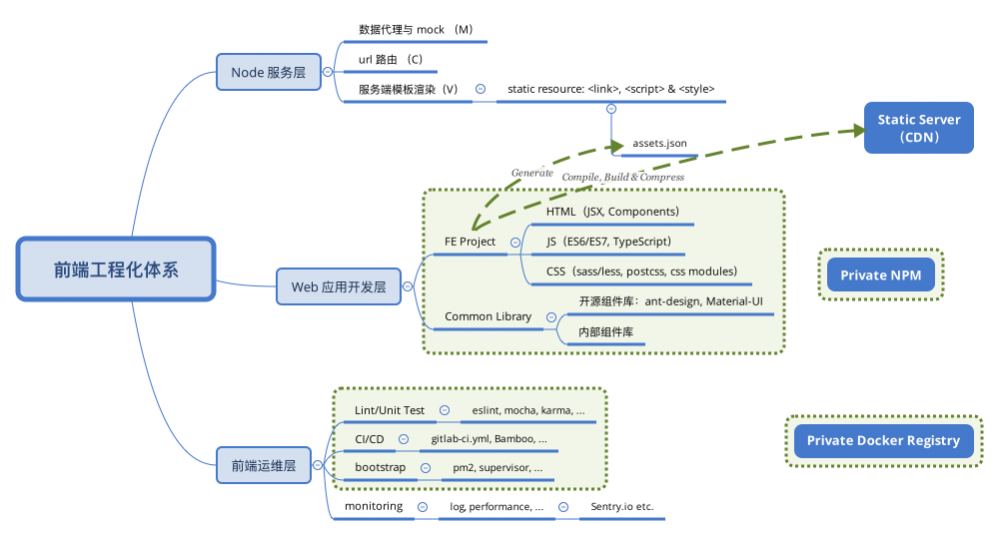
前端工程化体系
何谓前端工程化?即根据业务特点,将前端开发流程规范化、标准化。它主要包含不同业务场景的技术选型、代码规范、构建发布方案等。主要目地是为了提升前端开发工程师的开发效率与代码质量,降低前后端联调的沟通成本,使得前后端工程师更加专注于自身擅长领域。
根据自身从业这些年的一些产品和项目经验,对前端工程体系的设计有一些自己的见解:
- 前端开发应该是“自成体系”的,包括运维布署、日志监控等
- 针对不同的场景有不同的解决方案,并不是一套大而全的框架体系。比如针对以产品宣传展示为主的网页(Site),采用多页模式和响应式设计开发;以用户交互为主的且无强烈 SEO 要求的应用(Application),采用单页模式开发
- 产品组件化,为提高复用性尽量将组件的颗粒度分细一些,且低耦合高内聚
- 避免重复造轮子,引入一些优秀的开源资源,取长补短
根据以上思考,大致将自己理解的前端工程体系分为三大块:
- Node 服务层:主要做数据的代理和 Mock,url 的路由分发,还有模板渲染
- Web 应用开发层:主要专注 Web 交互体验
- 前端运维层:构建布署、日志监控等
Node 服务层
数据代理
一般在 web 应用中,数据的来源分为两类:
- 用户交互产生的 ajax 请求(客户端发起)
- 服务端模板渲染所需初始数据
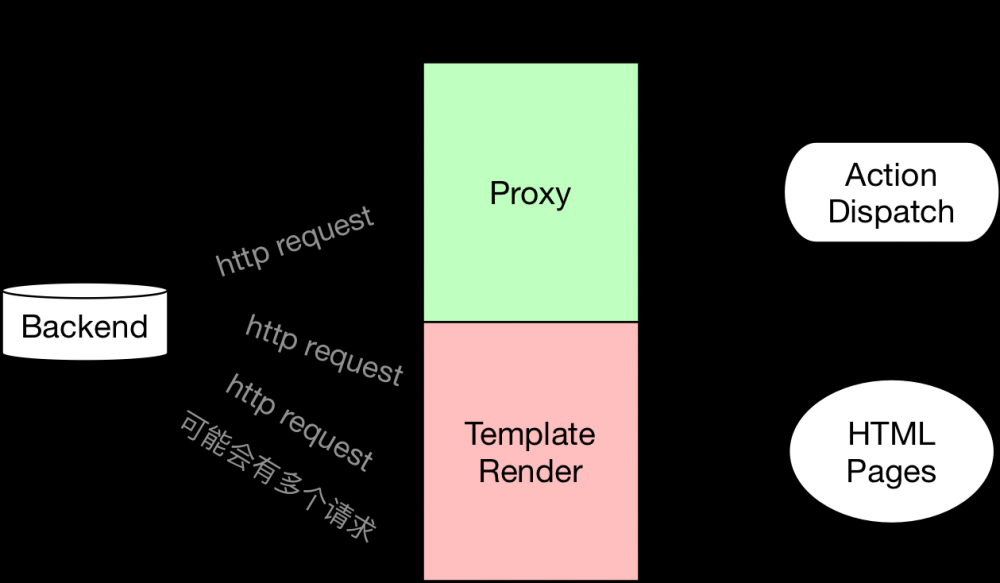
前者来说,传统的做法是后端直接提供 api 以供客户端调用,但面临微服务化逐渐成为主流的今天,后端系统也趋于拆分为众多后端服务,提供不同的 api,直接调用面临请求认证和跨域等众多问题,Node 做为中转站利用 http-proxy 将 http 请求和响应传输于前后两端,起到桥梁作用。
有人说直接请求后端 api 岂不是性能更佳?跨域问题直接用 CORS(Cross-origin resource sharing)不是也能解决?
我们先来看跨域问题:首页 CORS 当前还是有兼容性问题(不支持 IE10 及以下),其次它有一些限制或者说是自身局限:
需要注意的是,如果要发送Cookie,Access-Control-Allow-Origin就不能设为星号,必须指定明确的、与请求网页一致的域名。同时,Cookie依然遵循同源政策,只有用服务器域名设置的Cookie才会上传,其他域名的Cookie并不会上传,且(跨源)原网页代码中的document.cookie也无法读取服务器域名下的Cookie。
针对性能问题我则拿了公司项目的 api 随机的几个接口来做了些测试,不是非常精确,但也能看个大概。分别在 No throtting 和 Regular 4G 的模式下,用 proxy(http-proxy 代理请求),direct(直接请求后端地址)和 node(利用 request 模块发起请求)模式,做了 GET 和 POST 请求的延迟比对。在比对之前心里也大概有数,肯定是直接请求后端地址的延迟最低,毕竟加了 Node 一层,性能会由损耗。以下是测试结果:
No throtting GET: 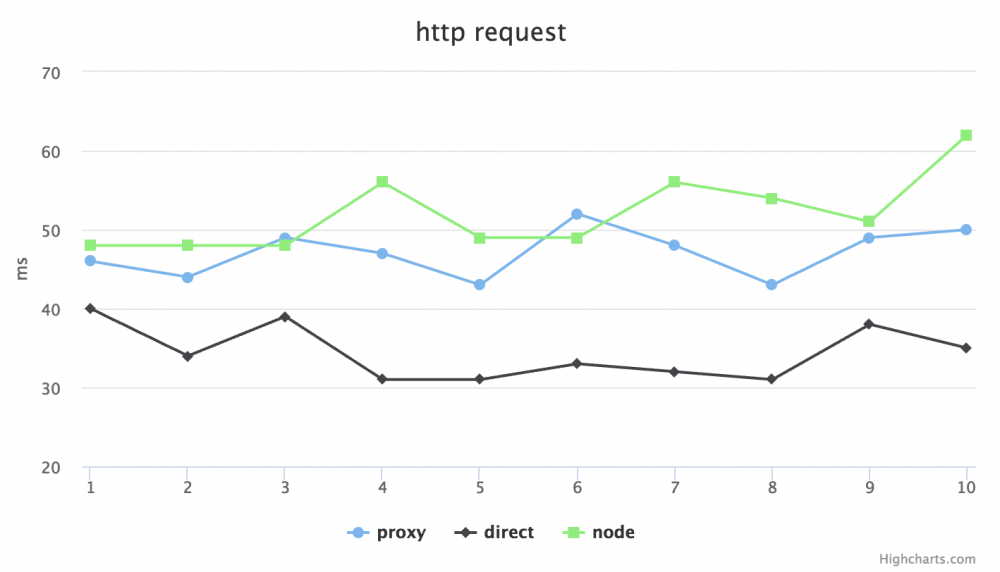
No throtting POST: 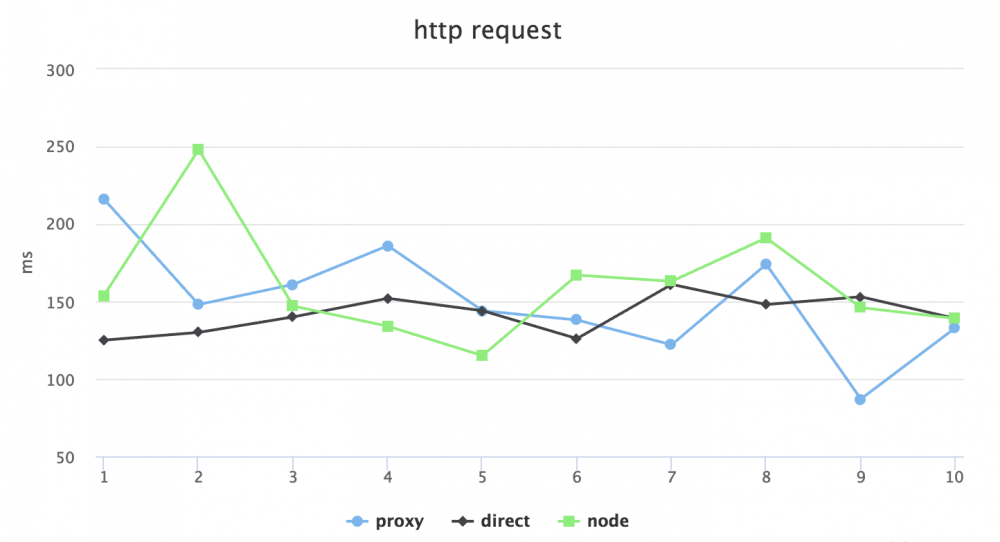
Regular 4G GET: 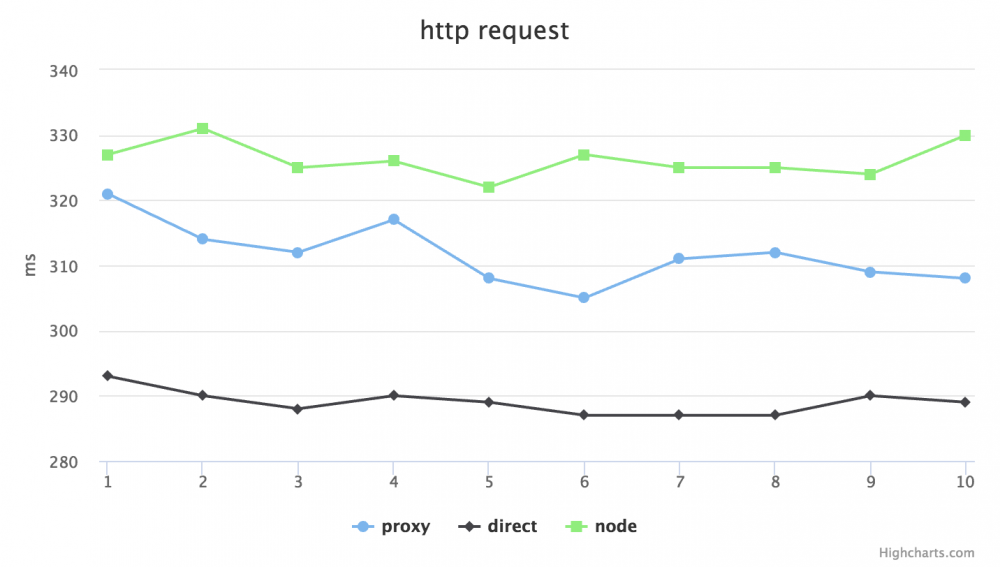
Regular 4G POST: 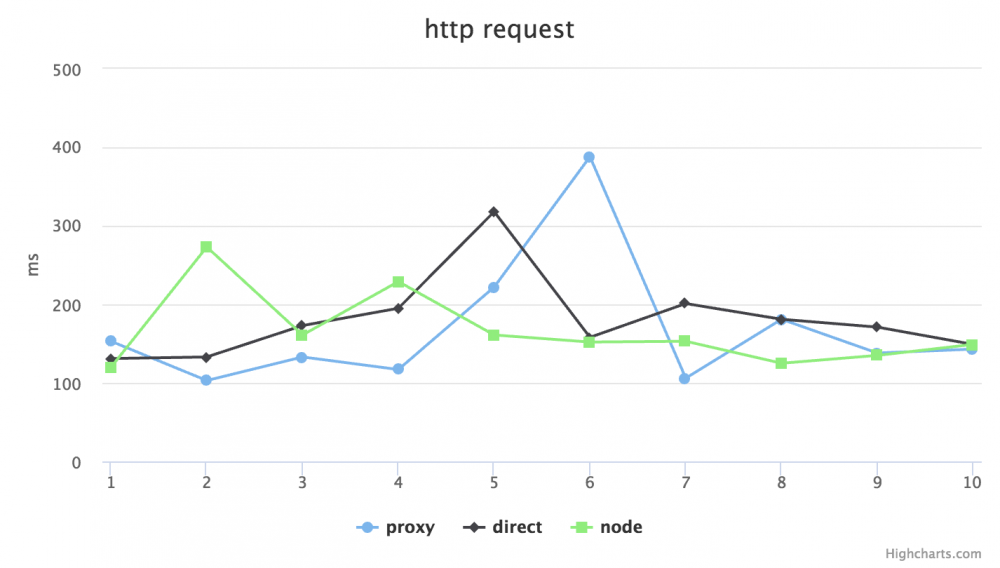
可以看出,GET 请求 direct 是最快的,proxy 次之,node request 垫底,POST 则相差不明显。但延迟差距在 30ms 左右,是否可以接受,就要看自己的系统架构对性能的要求有多高了。对于我司目前的规模体量用户数来说,完全是可以忽略的。
但为什么一定要用 Node 来做 http 请求的代理转发?我的理由:
- 前期前端开发过程中 mock 可与后期后端接口做平滑过渡,客户端做到无感知。甚至还能在 mock 数据和真实数据之间来回切换,十分灵活
- 当后端服务增多时,特别是内部系统,跨域调用很成问题,Node 代理转发从根本上解决跨域问题,不用担心 Cookie 丢失等问题,而且在 Node 层还能做进一步的 http 拦截和根据业务需求定制这些二次加工,适用于更加广泛的场景
我在之前做公司的模拟炒股项目时,大概就是这么地用的:
| 账户系统 | 行情系统 | 交易系统 |
|---|---|---|
| /api/account | /api/stock | /api/trade |
var url = require('url');
// 账户系统 API
app.use('/api/account', proxy(config.api.accout, {
forwardPath: function (req, res) {
return url.parse(req.url).path;
}
}));
// 股票行情 API
app.use('/api/stock', proxy(config.api.stock, {
forwardPath: function (req, res) {
return url.parse(req.url).path;
}
}));
// 股票交易 API
app.use('/api/trade', proxy(config.api.trade, {
forwardPath: function (req, res) {
return url.parse(req.url).path;
}
}));
至于服务端渲染,之前一直是用 JSP or PHP 等后端模板来做。现在又多了一种选择,Node 本身就是个服务端,而且模板本身是属于视觉层和数据层的结合品。在前后端分离的比较合理的条件下,让前端工程师来写服务端模板更加适合,因为此时 Node 服务层应该不包含复杂的数据运算(CPU 密集型非 Node 擅长场景),这里的数据来源都是比较直接和清晰的,顶多要做一些数据的拆分或整合处理而已,但对前端人员来说,了解业务逻辑是必备的,也是必需的,我们倡导的。
还有一点是因为下文中将要介绍的 Web 应用开发中,开发构建的工具本身就是基于 Node 的,build 后的静态资源大部分适合需在模板中引入,如何引入还是前端工程师最为清楚。所以虽模板属于服务端范畴,但与前端是结合的更加紧密的。
数据 Mock
一般来说,项目中后端接口实现的任务未完成,前端写好了页面只能等待。此时,如果后端有空可以造一些假数据,让前端可以继续开发调试。但我们鼓励前端工程师自己 mock 数据,为什么呢?
- 更好的了解业务
- 做为数据的第一级消费者,更清楚怎样的数据结构,适合前端页面展示。比如,用数组好,还是用字符串拼接好等等
- mock 效率更高,实现简单:json-server,mockjs
但目前这两种简单的 mock 工具都不是太适合当前公司的项目场景,因为我们公司大部分接口都不是 restful 的,所以用下来遇到两个问题:
- json-server 只支持 restful,而且只能生成 json 文件不够灵活
- mockjs 是比较灵活高效,但做不到数据的持久化
比较完美的方案是两者结合再加上支持非 restful 的 mock,这个可能需要以后自己定制了。PS. 最近 github 上看到了一个利用 service workers 搞出来的一个 mock 服务: service-mocker ,不管是否适用,但要为这样的思路点赞。
url 路由
前端来制定路由,也促使前端工程师更全面深入地了解业务。这属于设计范畴,需要经验加持。
因为具体路由下,基本就是业务逻辑 controller 了:
router.route('/:catalogId')
.get(catalogController.findOne)
.put(validate(paramSchema.updateCatalog), catalogController.update)
.delete(catalogController.remove);
还有一些简单的路由,就是负责页面渲染而已(特别是单页应用,基本上走客户端路由的路子了):
app.get('/', (req, res) => {
res.render('index', {
ip: req.connection.remoteAddress
});
});
服务端模板渲染
对于单页应用来说,服务端模板只是一个壳(shell)而已:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>Single Page Application</title>
<script>window.serverData={foo: '来自服务端数据'}</script>
</head>
<body>
<div id="app"></div>
<script src="//cdn/file-5917b08e4c7569d461b1.js"></script>
</body>
</html>
我们看到这里只通过 window.serverData 提供了简单的服务端数据。
对于多页应用来说,我们会引入 layout, include 等提取公共部分页面以达到最大复用:
./views ├── layout │ ├── default.jade │ ├── bootstrap.jade │ └── ... ├── include │ ├── topnav.jade │ ├── header.jade │ ├── footer.jade │ └── ... ├── templates │ └── ... └── index.jade
上文已提到过 Node 来做服务端模板渲染的有一个好处就是方便与静态资源衔接,是如何做到的呢?首先 web 应用经过前端构建工具 build 之后会生成静态资源映射表: asset-manifest.json ,串联起来大概是这样:
{
"main.css": "static/css/main.ad87bbd6.css",
"main.css.map": "static/css/main.ad87bbd6.css.map",
"main.js": "static/js/main.a3907cec.js",
"main.js.map": "static/js/main.a3907cec.js.map",
"static/media/yay.jpg": "static/media/yay.44dd3333.jpg"
}
const manifest = require('./asset-manifest.json');
app.locals.assets = {
mainCss: manifest['main.css'],
mainJs: manifest['main.js'],
...
};
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>Single Page Application</title>
<link rel="stylesheet" href="<%= assets.mainCss %>">
<script>window.serverData={foo: '来自服务端数据'}</script>
</head>
<body>
<div id="app"></div>
<script src="<%= assets.mainJs %>"></script>
</body>
</html>
Web 应用开发层
这一部分应该是前端工程师的专长部分,也是其核心价值的体现之处。
组件化和工程化
web 应用开发主要包含三个部分:html,css 和 js,三者之中,除了 js 在近几年才拥有了模块化机制以外,html 和 css 都是需要手工维护(难以维护),伴随着复制粘贴,时间一久其产生的代码冗余就像是 windows 上的 C 盘空间一样,不断发胖。
所以现代的 web 应用有这样的开发意识:everything in js is the better way. 正是 js 的模块化的可能性,成为了 web 功能模块(包含界面与交互)的组件化实现的基石。可以将 html 和 css 写在 js 之中(JSX),也可以以模板的形式它们三者写一起(Vue):
JSX 写法:
import React, { PropTypes } from 'react';
import styles from './Preview.css';
const Preview = ({url, user}) => {
return (
<div className={styles.card}>
<img src={url} alt="" className={styles.normal}/>
<Profile user={user} />
</div>
);
};
Preview.propTypes = {
url: PropTypes.string,
user: PropTypes.object
};
export default Preview;
Vue 的单文件形式:
<template>
<div id="app">
<img src="./assets/logo.png">
<h1>/</h1>
</div>
</template>
<script>
export default {
name: 'app',
data () {
return {
msg: 'Welcome to Your Vue.js App'
}
}
}
</script>
<style>
#app {
font-family: 'Avenir', Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
h1 {
font-weight: normal;
}
</style>
无论哪种形式,组件都不能直接在浏览器中使用(将来的 Web Components 可以,但可构建的组件绝对是更加有优势)。如果我们将浏览器看作是 web 应用的 runtime 环境,对比于 jvm 是 java 的 runtime,那前端的组件代码都是 java 级别的源码,要类似 java 那样通过构建打成 war 包方可使用。
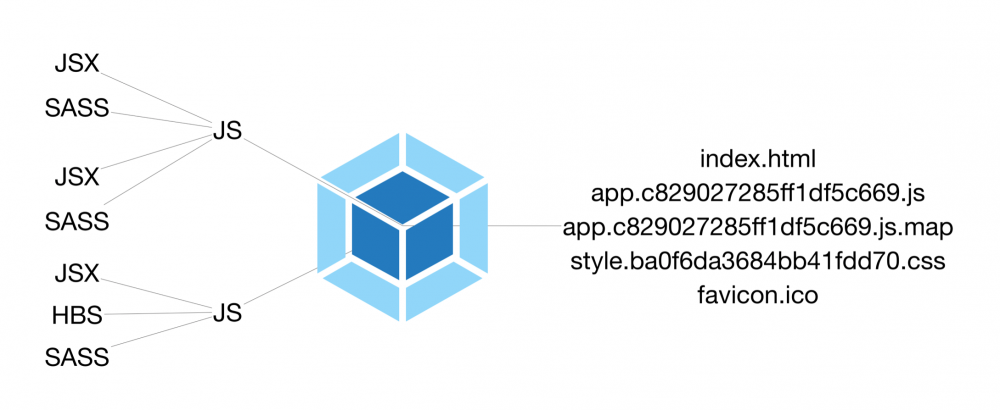
所以,为提升开发效率和代码质量,我们一般不直接写浏览器可读的 html, css 和 js,而是通过可模块化的“高级版” js,将一切资源进行串联,形成一系列业务或非业务组件,它们通过倚赖注入与模块输出、通过编译转换、通过合并或重组,最终生成浏览器可解析的代码。
如何更好的“串联”,这些都是工程问题,也是做为现代前端工程师的必备素质。
MDV
MDV = 模型驱动视图 。从 2010 Google 推出 Angular 开始,到 2013 年 Facebook 推出 React,再到最近国人自创的小而美的 Vue,都一路贯穿着 web 开发新的思路:从 手动操作 DOM 到 数据绑定 + Virtual DOM 的转变。这也是 everything in js 体现的极致,把 DOM 操作都干掉了,直接用基于 js plain object 的虚拟 DOM:
var a = React.createElement('a', {
className: 'link',
href: 'https://github.com/facebook/react'
}, 'React');
React 首创的虚拟 DOM 有两大杀手锏大大提升了原生 DOM 操作效率低下的问题(特别是在移动端):batching 和 diff。batching 把所有的 DOM 操作搜集起来,一次性提交给真实的 DOM;diff 算法时间复杂度也从标准的 diff 算法的 O(n 3) 降到了 O(n)。
除了性能提升之外,由于思路的转变,在开发效率上也有很大提升:MDV 模式下很自然的就将 web 页面看做是一台状态机(State Machine),UI = f(state), 界面上的变化皆由状态变化所导致,状态的变化来源一定为 M,即数据模型。我们将手动操作 DOM 的工作交给 MVVM 框架的数据绑定来做,界面的改变由数据的变化而自动完成,不仅十分高效,而且我们对于数据的流向更加清晰可控。在引入严格的函数式编程与不可变数据(immutable.js)后,还能使得结果可预测,方便做单元测试。
当然,除了许多新的概念需要学习之外,组件间的如何通信,异步数据如何管理等一系列问题也是随之而来的一些挑战。
轮子
打造前端组件库,这里的指的组件,可以是无关业务的界面组件,也可能是功能模块,或者两者皆有。其目的就是为了方便复用,便于管理。涉及公司业务的我们定义为 private components,不涉及业务的我们如果做的优秀也可以开源,开源有什么好处?大家都懂的。
另外我们也拥抱业界优秀的开源方案,比如蚂蚁金服的 ant-design,谷歌的 Material-UI 等,在巨人的肩膀上,我们可以更高效更快速地开发我们的项目,迭代我们的产品。
多终端和跨平台
在这里要稍微强调一下我们的客户端也就是浏览器,可以看作是我们前端代码的运行环境。我们可以想像的到,js 这个 10 天之内创造出来的语言之所以能够如此流行而且经久不衰,完全是靠了浏览器这个全球数量最庞大分部最广的天然 js 解析器的功劳。它遍布世界上的每一个角落,你不得不用。所以了解语言宿主,当然也是至关重要的。
根据浏览器内核来分,前端应该关注的终端环境应该包括:
- 移动端:微信 X5 内核,iOS Webkit,Android Webkit
- PC 端:Trident(IE),Gecko(FireFox),Webkit(Safari),Bink(Chrome),Presto(Opera,已放弃)
可以看出来,最主要的战场,是 Webkit(移动端上的 Webkit 主要看系统 SDK)。在国内来说,由于微信的关系,我们还需要比较关注的是 X5(特别是近期的微信小程序推出)。
根据平台来分:
- 移动端:Cordova,React Native,Weex
- 桌面端:node-webkit(NW.js), Electron
- 穿戴设备:WebVR
关于终端适配和跨平台的挑战,前者在于一些兼容性的问题,这个根据之前的工程化的方案,将 html, css, js 视作“编译”资源,在通过“编译工具”构建后,让工具自动地根据不同内核生成相应的适配代码,降低开发成本。后者对前端工程师的要求较高,需要复合性的知识和能力,但带来的收益巨大。值得一提的是 React 的目标宗旨就是:write once,run everywhere,它也正朝着这个方向在不断前进。
总体来说,Web 应用的开发主要技术特点就是(盗了 某熊的全栈之路 的图,哈哈):
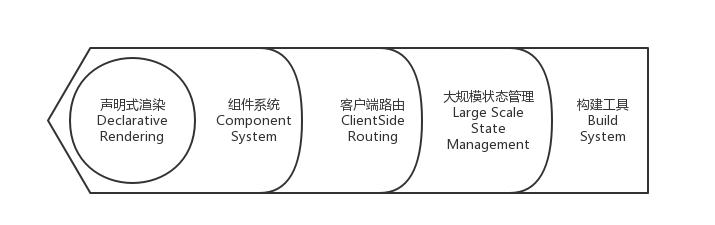
前端运维层
测试
在代码 build 之前有两部操作要做:
- 代码层面的 Lint
- 功能层面的 Unit Test
Lint 是根据代码规范的规则来制定的,不同的场景有不同的规则。比如是 node 环境还是浏览器环境,采用的模块化机制是 commonjs 还是 amd 等,都要分别配置。这里主要是为了保障代码没有明显的错误和拥有一致的风格。

Unit Test 在以往只重界面不重交互(页面状态管理)的传统 web 项目下并不常见,但在一些稍微有点复杂程度的前端项目中,单元测试就显得比较重要了。我之前的公司对项目开发的速度要求比较高,所以这一块比较少做。不过目前一些主流的前端框架都附带测试库与简单例子,比如 create-react-app 就自带了 jest。
CI/CD
前端的布署主要分静态和动态两部分:
- 静态主要是指一些静态资源,布署也比较简单,就是往 CDN 服务器上放即可。
- 动态就是 Node 服务层的东西,关于 Node App 的布署,可参考我之前写的这篇文章。
至于如何做到自动化以提升效率,主要利用 git hooks 通知到 CI 服务器,执行对于脚本来做,这里有许多方案可供选择。我由于在公司一直用的都是 gitlab,所以之前只尝试过 gitlab-ci,能与 Docker 想结合用起来还是比较爽的。
其它比较常见的就是 Jenkins, Travis CI 等。
扩展与稳定性
遇到程序 crash 怎么办?现在 Node 上已经有非常多的进程重启模块,比如 pm2,forever 等。
为了更好的利用 CPU 内核资源,我们还有在单台服务器上启用多个应用实例。大家知道,nginx 或 haproxy 等集群都是一主多从,主机的端口通过负载均衡算法,将请求转发到 slave 机器上。刚说的多台机器是这样的,那在一台机器上起多个实例,对这些实例进行集群管理也是一样的原理。
这里以 pm2 为例:
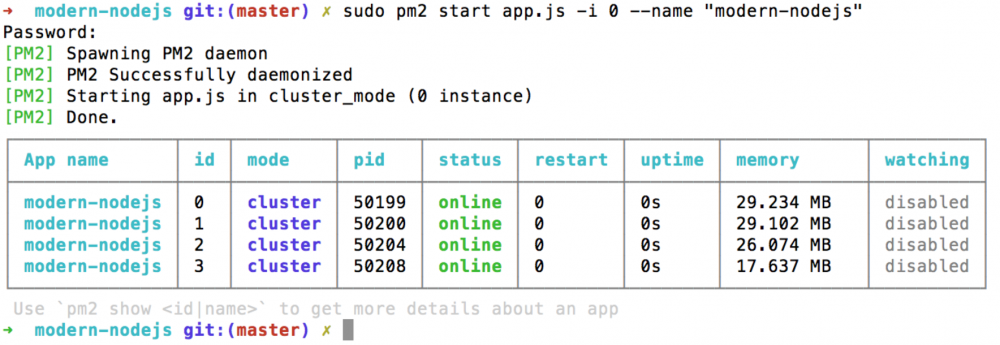
然后我们手动制造一个崩溃,可以看到,可以看到第一个线程,restart显示为1,也就是说当崩溃的时候它会自动创建新的线程来继续服务。
性能日志监控
监控可大可小,往小了说,可以是一个工具,往大了讲,也可以是一套系统,不仅仅可以有可视化的图表,还支持一系列的报警规则。如果公司的人力有限,估计投入产出比不高的,初期可以考虑一些优秀的在线服务,比如:keymetrics.io, Sentry.io 等,这些服务功能强大基本涵盖所有需求,而且易于集成。当然,好用的基本上都是需要付费的。
写在最后
文中没有提到的 Private NPM 和 Private Docker Registry 我用虚线框起来,是就目前来看很难做到,因为我们的代码库是内网的,而且公司目前是阿里云的重度使用者,Docker 要如要投入使用,要是没有自身的 IAAS 基础设施做支持估计也是玩不转。当然,这些都是没几个小公司能玩转的,有机会就尝试,但做为技术人,首要任务还是方案落地和解决实际的业务问题。
正文到此结束
- 本文标签: MQ 测试 自动化 负载均衡 产品 UI 管理 时间 parse Chrome Ajax 数据模型 java Haproxy 定制 node js 炒股 系统架构 Facebook 需求 解析 谷歌 开源 ACE 云 编译 remote https 进程 配置 交易系统 代码 Android key 性能问题 http logo IO 端口 git 线程 map CSS IaaS HTML Docker 开发 主机 ORM 服务器 windows ip find 政策 Bootstrap GitHub App json 分页 src Service Nginx tab shell tar apr IDE Google 域名 实例 快的 build 函数式编程 PHP id 认证 质量 集群 数据 API 空间 DOM 阿里云 schema IOS web 服务端 源码 jenkins CDN cat 调试 RESTful 响应式 Document REST Connection 文章 update
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

