假期前的数据库检查之主动优化
快要过年了,很多工作都会放下来,很多计划都会搁置下来,节前的检查还是必要的,尤其是那些看似不起眼的问题尤其需要注意。今天就处理了一起,也算是假期前的性能优化临门一脚。
一、一个不经意的问题?
做例行检查的时候,我基本会看看大体的DB time情况,是否有较大的抖动,归档频率是否频繁,近期是否有监控报警等,当然很多细则不需要一个一个去确认,打开Zabbix里面的zatree或者监控概览列表就能得到不少的信息了,或者跑个批量脚本也能得到不少信息。
我查看了一个套数据库环境,DB time看起来很低,可见资源使用率不高,负载确实也不高。
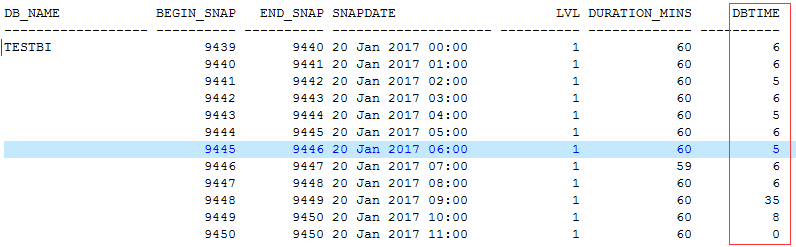
但是下一个指标就让我有些奇怪了,马上警觉起来。
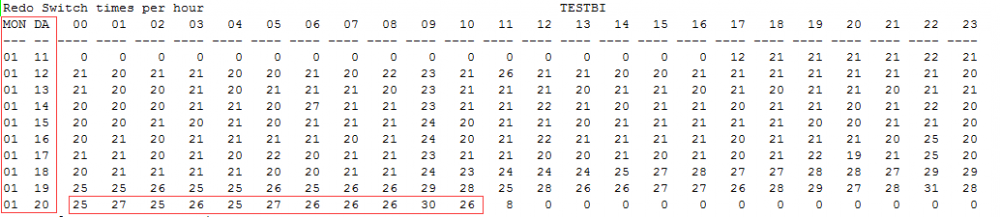
这是什么情况,每个小时的归档切换量有20多次,这个不大正常啊,看看以前,这个列表中列举出了近半个月的情况,可以看到年初的时候是正常的,但是从某一个时间点开始归档量一下子提升了不少,而且看起来很稳定。
毋庸置疑,对于一名DBA来讲,应该得有这样的“嗅觉”。
这是一个看起来不太起眼的问题,但是确实是个问题。
二、前期的分析?
当然这个时候我没有着急去找开发同学,而是自己先分析了一通,看看到底可能是什么原因导致的,抓取了应AWR报告,但是因为负载不高,从报告里面其实看不是很清晰,那么还有什么办法能更直接呢,直接抽取日志。
我们可以使用Logminer来抽取redo日志,看看里面到底都装了些什么,这样问题就很清晰了,这个步骤也算是轻车熟路,可以参考之前的一个链接 Oracle闪回原理-Logminer解读redo(r11笔记第17天)
所以说,我是毫无保留的把脚本贡献出来了,也同时方便了我自己。
打开解析后的日志,我立马明白问题大概的方向了,因为这个问题和之前碰到的另外一个有些类似。
insert导致的性能问题大排查(r11笔记第26天)
但是还是略有一些差别,解析后的redo里面的内容基本都是一些insert,delete操作,而且是同一个表,表的数据量大概是200万左右,总体数据量也没有很明显的抖动,平平稳稳。但是就是这样的插入,删除。
无论如何,问题已经找到了不少的信息,我觉得可以和开发同学谈谈了。
三、开发同学很给力
所以我反馈问题的时候,他们没有条件反射式的抗拒,还是很认真的听了我的描述,而且还对我表示感谢,感谢我发现这类问题。
当然问题的情况可能和我想得也不大一样,快中午了,几个同事开始集五福了,我也凑了凑热闹。然后吃完饭回来,就和开发聊起这个问题,其实我也说得很诚恳,节前检查,发现问题了最好能及时修复,明天我就要开始休假了,吧啦吧啦。
对于这个问题,他们给我的解释是,和上次处理的那个问题还不大一样,因为另外一个系统会实时给他们推送一些近期的数据,所以他们就属于生产者-消费者模式中的消费者,不断的去接受应用这些信息,但是他们也会不断收到一些重复的信息,所以就可能产生大量,频繁的delete,insert操作,而数据量还是稳定不变。
对这个问题的改进,基本就是能够尽可能杜绝这种频繁的改动,从源头上控制还是不大可能了,但是下游可以做到一种逻辑上的过滤,所以和开发同事的沟通之后,他们也主动建议使用merge into的方式,即发现有重复的数据,那就什么都不做,如果是新数据,则插入,这样一来问题就会极大的简化。
所以问题的大体思路就是insert+delete改造成merge into,而且还是开发同学主动提出的,非常难得。
四、问题的修复验证?
修复问题大概需要多少时间呢,开发同学说了一个给力的答案,一个小时以内就修复。所以没过多久,我就看到问题修复了。一个直观的感受就是一个小时以内没有日志切换,如此一来这个问题就得到了极大的环节,从数据库层面所做的事情就很少了。
我也不用花功夫去调节归档删除频率,调节闪回区大小等。
这种主动的优化方式虽然还没有直接修复问题,但是已经极大的缓解了问题,我想DB time只是一个基础的指标,这个指标之下还有很多内容需要挖掘。
能不能给数据库一个基本的指标,就跟游戏里的生命值一样的东西,我估且叫它为生命线吧。能把这些指标值糅合,给数据库一个指标值,我想处理问题也会如虎添翼。
最后给大家一点建议,可能和技术无关,也可能有关,看你的理解了。

现在朋友圈已被沦陷,为了一周还是,你自己想想,深度技术文章你有没有耐心看,收藏了多少而没有看,你自己是否好好总结过。热点事件,大量有趣的时事新闻,你是看看呢,还是逐渐迷失。
说到迷失,我想起了那部美剧。let it go.

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

