走进大数据之拓扑数据分析方法

文 | 杨晓东
拓扑数据分析(TDA),顾名思义,就是把拓扑学与数据分析结合的一种分析方法,用于深入研究大数据中潜藏的有价值的关系。
相比于主成分分析、聚类分析这些常用的方法,TDA不仅可以有效地捕捉高维数据空间的拓扑信息,而且擅长发现一些用传统方法无法发现的小分类。这种方法也因此曾在基因与癌症研究领域大显身手。
1.什么是拓扑数据分析
拓扑学研究的是一些特殊的几何性质,这些性质在图形连续改变形状后还能继续保持不变,称为“拓扑性质”。而在复杂的高维数据内部也存在着类似的结构性质,我们可以形象地称之为数据的形状(特征)。
和通常研究的成对关系相比,这种相互关系的形状之中可能潜藏了巨大的研究价值。要理解数据的形状,就必须求助于拓扑学。TDA所做的就是抽取这种形状并进行分析。
那么到底如何来刻画数据的形状呢?下图是一个简单的例子:
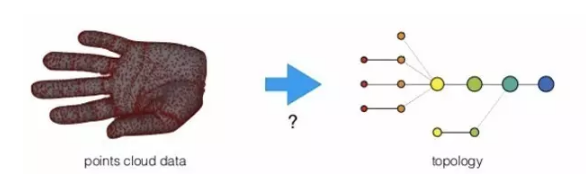
左边是一只手的采样数据点,宏观看来像一只手。右边则是经过拓扑数据分析得到的图,有点像一只手的骨架。从左边到右边,就是一次形状重构的过程。这种重构用了很少量的点和边去刻画原始数据集,同时保留了原始数据的基本特征。
2.拓扑数据分析的三个要点
1)TDA的输入可以是一个距离矩阵,表示任意两数据点之间的距离。
它研究的是与坐标无关的形状,完全不受坐标的限制。这也意味着拓扑形状的构建依赖于距离函数的定义,或者说相似度概念的定义。坐标无关的特性,使得TDA可以整合来自不同平台的数据,尽管这些数据的结构不太一样,你只需要给出合理的距离函数。这是TDA的一个优点,通用性。
举个例子,TDA在癌症分析领域的成功,这种通用性是一个重要原因。因为不同癌症数据集的指标、结构都不尽相同,而TDA可以轻松整合。
2)TDA研究的数据形状,可以容忍数据小范围的变形与失真。
想象在一块橡皮上写了一个字母”A”,你用力挤压拉扯这块橡皮,字母”A”虽然有点扭曲变形,但是“一个三角形带两个脚”这样的基本特征仍然存在。从上面“手”的例子也可以看出,TDA对小误差的容忍度很大。
3)如果我们要粗略的描绘一个湖泊轮廓,最简洁的就是使用一个多边形。
拓扑处理的是抽象的形状,最典型的例子就是用六边形来表示圆,这只需要用到6个点和6条边。
TDA使用这种形式压缩数据,用有限的点和边来表示大量的数据,并且保留了数据重要的特征。
3.拓扑数据分析的主要步骤
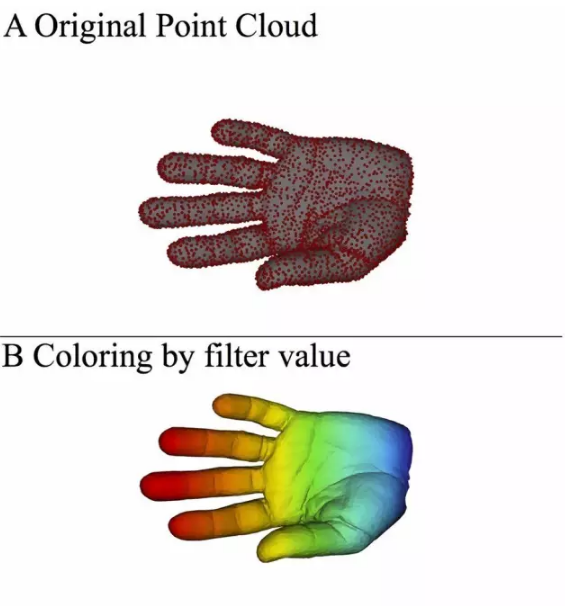
用一个滤波函数对每个数据点计算一个滤波值。这个滤波函数可以是数据矩阵的线性投影,比如PCA。也可以是距离矩阵的密度估计或者中心度指标,比如L-infinity(L-infinity的取值是该点到离它最远的点的距离,是一个中心度指标)。
数据点按照其滤波值,从小到大被分到不同的滤波值区间里。参照下图中“手”被切成等宽的块。但需要注意的是,相邻的滤波值区间设置有一定的重叠区域,也就是重叠区域的点同时属于两个区间(这一点很重要)。
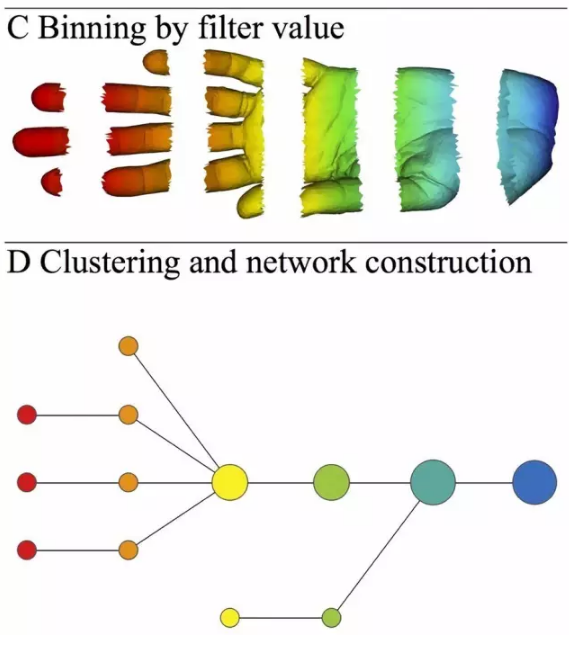
对每个区间里的数据分别做聚类。
把上一步骤中各区间聚类的得到的小类放在一起,每一个小类用一个大小不同的圆表示。若两个类之间存在相同的原始数据点(这就是区间需要相互重叠的原因),则在它们之间加上一条边。
对上述圆和边组成的图形施加一层力学布局,让其达到平衡,就得到最终的“数据图形”。
下图是一个简单的示意图,便于理解:
4.案例:ayasdi公司关于NBA球员的研究
有一份关于NBA球员的数据集,这份数据集编码了球员在场上表现的各个方面,包括篮板、助攻、失误、抢断、封锁、犯规、得分等各项指标的每分钟频率。对这份数据集进行拓扑化后,得到了下面这张图。
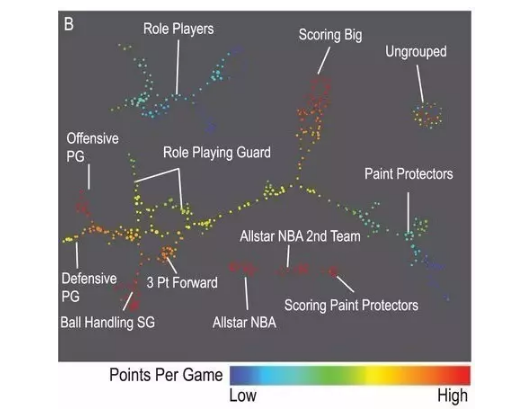
篮球运动员的位置一般分为控球后卫、得分后卫、小前锋、大前锋、中锋。然而在上图的网络中,我们看到了比传统的五个位置更为精细的结构。比如在网络的左侧,守卫被细分成了三个组,攻击守卫、防守守卫、击球守卫。在网络的中下部我们可以看到三个比较小的块,其中有“NBA全明星”(Allstar NBA) 和“NBA全明星第二梯队”(Allstar NBA 2nd Team)。
“NBA全明星”这个组几乎由NBA历史上最优秀的球员组成,“第二梯队”虽然也都是由全能的优秀球员组成但表现上可能不如全明星组。
有意思的是,在全明星组中还有一些不太知名的球员,这些球员也许就是潜在的未来明星球员。
写在最后
拓扑数据分析作为一种强大的工具,已经开始被广泛的应用。在未来基于TDA的算法肯定会不断的提出和完善。目前关于TDA详细的中文资料比较少,附上一份简单的python实现以供交流 >>>
End.
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

