京东到家订单交易架构演化
背景
交易系统可能不是技术难度最深的,但是业务复杂度最高的,一个订单从提交到最后真正生产成功要经历几十个系统,涉及的接口交互,MQ等可能达上百个。任何一个环节出问题都会导致这一单的异常,而且交易不像单纯的资讯门户可以靠静态化或者缓存抗住大并发,交易系统里面涉及到大量的资源(库存,优惠券,优惠码等)消费,订单生成等需要写入持久化的操作不是单纯的异步或者缓存化可以解决的,而且对库存等敏感信息不能出现并发扣减等。
细节的设计非常多,下面挑出比较典型的一些方面,给大家介绍下京东到家交易系统的架构设计和关键问题的处理方案。
历程
系统Set化
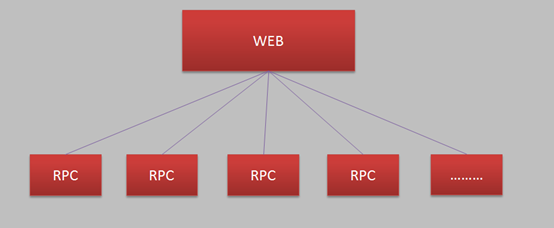
初期的订单系统和首页,单品页,购物车业务逻辑层等都是在一个大项目里。非常适合初期人员少,业务复杂度低,快速迭代,不断探索试错的过程,但是随着业务的发展,出现了以下问题:
- 系统的流量和业务复杂度也越来越大,大家共用一个大项目进行开发部署,相互影响,协调成本变高;
- 不同的业务模块,流量和重要级别不同需要的部署策略和容灾降级限流等措施也不一样,要分而治之;
解决方案
项目Set化,这个过程中要注意Set化的边界问题,粒度太大了效果不好,太小了设计过度了,反而会增加维护和开发成本;
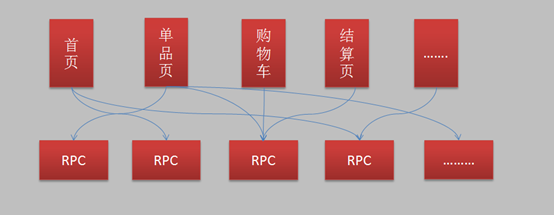
分库分表
问题
随着订单的并发量的不断攀升,特别是在双十一,618等大促的时候,单组DB(一主多从)存在着明显的压力,单个主库的连接数是有限的。大单量,大并发的时候,数据库越来越成为了我们的瓶颈。
解决方案
针对接单数据库我们采取的常规做法分库,根据订单号进行Hash分布到不同的多个数据库中,代码方面我们是继承了Spring的AbstractRoutingDataSource,实现了determineCurrentLookupKey方法。对业务代码只有很少的耦合。
另外下发到个人中心数据库的订单信息,每天不断的累计到DB中,存在以下风险:
- MySQL的单表容量超过单机限制
- 穿透缓存到达DB的数据查询也是非常有问题的。
目前我们采取对个人中心的表按照pin进行分库分表。
但是对于后端生产系统对于订单数据的查询操作,特别是涉及到多条件组合的情况,由于数据量大,多个表数据的关联,无论分不分表或者读写分离对这个场景都不能很好的解决。
这种场景下我们采用了ES,在写入DB的时候同步写入ES。你可能会问ES失败了,数据不一致怎么办,ES失败了DB回滚,Worker标识状态,重新迎接下一次轮询。
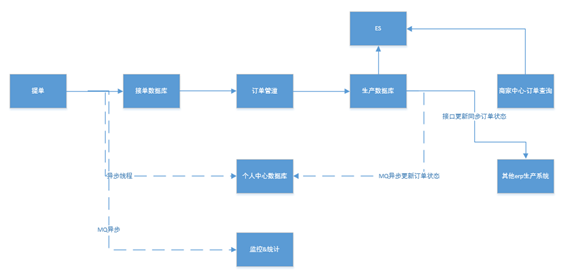
前端下单和后端生产分离
问题
toc端和tob端的业务场景不同,前端对互联网用户的更多的是快速响应,抗住流量压力,而后端的场景需要稳定的全量的数据,要在接单的数据库基础上进行补全数据;两个端职责不同,不能互相影响;
解决方案
ToC和ToB分离,前端App或者H5用户下单和后端订单真正的生产相分离;前端订单系统挂掉了,不影响后端的生产;后端的生产挂了,对用户的下单也是无感知的。只是对配送的时效体验上会有影响,不是阻断性的。
我们ToC的订单系统和ToB的是两个不同的独立数据库,互不影响;订单管道的Woker都是基于TBSchedule的分布式管理,多个Woker并行处理,下发时机都在毫秒级;
并行控制提升效率
问题
交易的流程依赖的系统非常多,拿提单按钮来举例,结算页的”提单”按钮,点一次就会触发20+个接口。随着业务复杂度的提升,单纯的串行执行效率越来越低,前端用户的体验越来越差。我们要求TP999在500ms以内的响应速度。
解决方案
我们梳理了服务的依赖关系等,对没有前后依赖的接口进行放到线程池里面异步执行,类似:查询库存,查询商品信息,查询促销信息等都并行执行。此步执行的时间,是并行接口里面最长的一个执行的时间。这样一来整个提单的操作提升了几百毫秒。
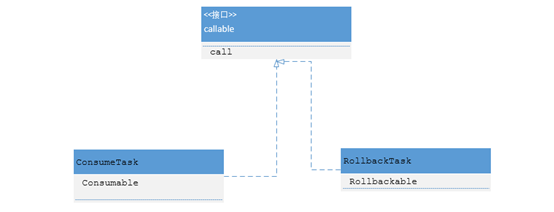
另外资源(库存,优惠券,优惠码,促销等)的消费和回滚,我们也采用了并行的方式,每一种资源类都实现消费和回滚的接口。如下图:
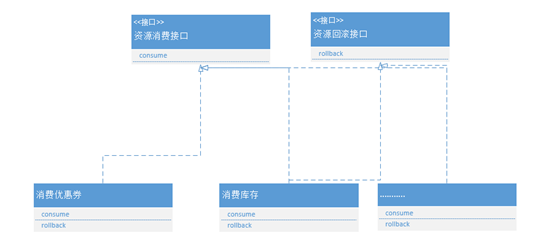
每个资源类都是一个Task的成员变量,Task实现了Callable接口。这样一来,不但整个提单大接口的效率提升了,对于资源消费和回滚环节,程序和业务的扩展性提升了很多。比如新增一种资源,这时候只需实现消费和回滚接口,然后扔到线程池里面就完成了。
异步
在服务端可能需要针对提单请求做一些附属的事情,这些事情其实用户并不关心或者用户不需要立即拿到这些事情的处理结果,这种情况就比较适合用异步的方式处理这些事情,思路就是将订单交易的业务整理出来,哪些是不影响主流程的,例如:发短信,保存最近使用地址,清除购物车商品,下发订单给个人中心等等。这些都是在提单之后的异步线程去做。对于下发给个人中心的操作,如果失败,我们会有Woker补偿机制;
我们这里使用的是线程池的模式进行异步处理的,处理过程中有几个问题需要注意下:
- 线程池的队列不建议使用无界队列,它的默认大小是整数的最大值,这样在突发流量的时候会导致内存暴涨,影响服务;建议使用ArrayBlockingQueue
- 不推荐使用CallerRunsPolicy,即在线程和队列都达到max的时候,退回此请求到主线程。这样在突发流量或者接口提供方性能下降的时候导致主线程数暴增,影响整体服务。可以直接使用拒绝的策略,后续的Woker可以对异常单就行补偿;
依赖治理
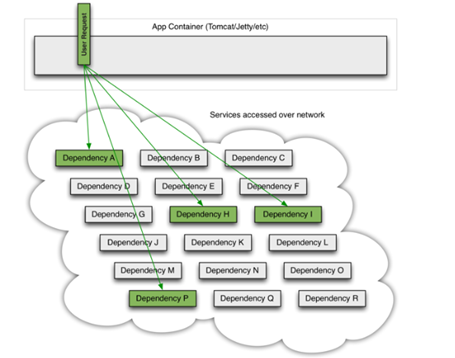
订单交易上百个接口,几十个系统交互。各服务直接的依赖关系如何治理是一个很重要的问题。如下图:
问题
一个服务依赖这么多服务,每个服务除自身的原因外,还受到网络原因等其他外部因素的影响,高并发情况下任何一个依赖的服务的波动都会造成整个大服务的阻塞,进而导致系统“雪崩”。
解决方案
那这些服务特别是不是阻断流程的服务,我们可以采用降级的处理,例如调用超时了给设定默认值,调用量比较大,所依赖的服务严重超时并影响整个调用方时,可以通过配置直接提供有损服务,不调用此服务。
我们解决此类问题是使用自己开发的基于Zookeeper的“鲁班系统”,其原理就是Zookeeper相应的Znode节点下的数据做为对接口的开关或者降级情况的配置等。当相应的节点的数据发生变化的时候,对此节点监听的所有服务器都会受到通知,并将此变更同步到本地的缓存中;本地缓存我们使用的ConcurrentHashMap。当然也可以使用Guava Cache等开源组件,注意并发的场景就可以了;
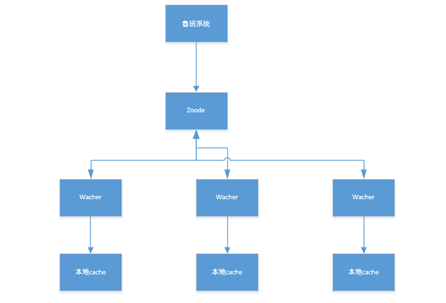
然后再结合我们的UMP监控系统对系统的可用率,调用量等情况进行降级时机的判定,对Zookeeper相应节点的数据做动态配置;

履约
问题
针对订单履约的过程清晰可追溯,我们自己开发了UDP上报系统,对一次提单中操作的所有接口,几十个系统的交互进行了详细记录;
解决方案
出参入参,是否异常,IP等信息均做了上报。通过Spring的AOP方式,开发了一个自定义注解,对添加了注解的方法UDP方式写入到ES集群中;而且我们实现了工具化,任何项目引入我们的Jar包,做简单配置就可以向我们的UDP服务端上报信息了。随着现在的信息量变大,我们正在考虑升级架构,UDP Client端发送信息到Kafka,然后Storm实时在线分析形成最终需要的数据落地到ES集群中;
此系统大大提升了我们定位解决问题的效率。
未来展望
多渠道分拆
微信,app,h5等多渠道隔离,单独部署单独发布。各渠道互不影响。以后再灰度就要单台->单set->单渠道->全量
监控
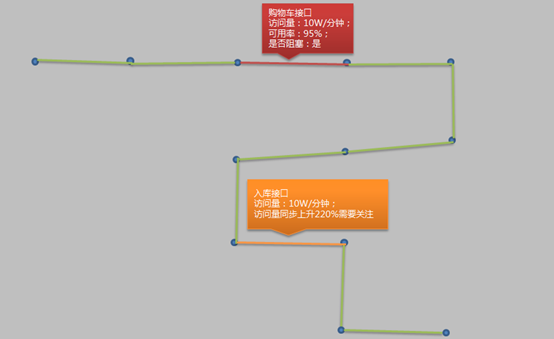
画了一个效果图,服务依赖的治理根据透明可视化。一个大服务依赖的接口众多,如果像下面我画的这个图这样,不同颜色代表不同的接口状态。鼠标附上去会展示详细信息;以后还可以做成,图形和后台服务程序联动,图中的一个节点就是一个服务,通过拖拽等方式,实现和后台程序联动达到降级的效果;
接单xml数据化
如果以后订单量持续增加,每次操作多张表,单量上升的时候系统压力会上升,我们可以对订单库的表数据存储进行XML化,每个订单只操作一张表,存储一条数据,(XML化相对JSON可能解析的时候性能会稍微差一些,但是对于问题的查询可视化程度更高)然后在下发到后台的ToB生产数据库的时候,异步Worker还原成多表;
结算页缓存化
这个其实我们已经有技术方案,流程图已经出来了。后期就会上。目前提单的时候众多参数是从结算页从URL里面带过去的。虽然我们做了数字签名但是,在安全性和接口数据传输效率上还不是最好的。大致方案就是在用户进入结算页后将数据缓存化,当用户刷新结算页的时候,非敏感信息直接从缓存取,不用重复调用接口,提交订单的时候也入参就很简单了,一个Key就可以了。
更多关于达达技术的文章,敬请关注达达技术公众号。

正文到此结束
- 本文标签: 京东 NSA json client Action 服务端 https 集群 数据 解析 dataSource queue 页缓存 ip 互联网 UI App 同步 线程池 MQ db 压力 配置 UDP 开源 文章 AOP node 线程 map 时间 开发 Architect IO 服务器 sql 代码 参数 http 数据缓存 spring 数据库 zookeeper 管理 key ask cache 高并发 rmi 安全 交易系统 XML src ORM 分布式 mysql js
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

