微信跨平台组件mars-xlog架构分析及迁移思路
最近微信开源了他们的跨平台组件mars,前段时间看到他们发的 微信终端跨平台组件 mars 系列(一) - 高性能日志模块xlog 就已经有点跃跃欲试了,我们打算学习一下并尝试迁移。
谈谈xlog
在上面提到的文章中他们提出了几种方案:
- 内存缓存,缓存到一定阈值写入文件 优点是效率很高,缺点是在异常情况下 丢日志 ;
- 直接写入文件(普通IO) 优点是不会丢日志,但是效率低下;
- 直接写入文件(mmap) 效率较高,不会丢日志,但是编程要求较高;
微信选择了最后一种方案,关于mmap具体为什么效率高,可以参考 认真分析mmap:是什么 为什么 怎么用 ,这里面说明了mmap之所以快的主要是在读写时能够让用户空间与内核空间更容易地交互。
关于XLOG的性能比对、benchmark可以见上面的文章,或 Mars-benchmark 。
我从源码角度简单描述一下它是怎么做的,每一条日志的处理流程大约是如下流程:

简单来说就是三步:
- 将要打的日志附上各种信息(进程、线程、日期)并格式化。
- 将日志写入高速缓冲区。这块高速缓冲区是使用mmap映射出来的内存区,被映射的磁盘文件是它新建的一个缓存文件,.mmap2后缀(若mmap失败,则用内存缓存代替)。每次打log时首先将它写入高速缓存,这样当使用mmap时可以保证这条log快速地被写入磁盘。
- 当高速缓冲区内容写到一定阈值时(此处为1/3),通知后台线程将缓冲区的内容写入文件。
它使用mmap映射一块固定长度的文件,这样保证每条log第一时间都被写入磁盘,由于每次将log写入目标文件时都会清空高速缓冲区,所以高速缓冲区的内容可以认为没有被写入文件,每次启动时可以检查缓冲区,若有数据则将它先写入目标文件,达到 不丢日志 的效果。这块核心的内容是在 appender.cc/.h 中,大家有兴趣可以对照看看。
一点疑问
当我刚看完这个代码的时候,我心里是有点疑问的,主要在于:
为什么不直接对输出log的文件进行mmap?而是写一块固定区域然后由后台线程读这块缓存区输出目标文件?
首先,我这种说法是可行的,因为 mmap 是指定目标map文件的偏移量,就可以通过代码动态扩展map起点,达到始终map 定长区域 的效果,然后直接对这块map进行输出。
由于mmap是映射固定长度区域,为保证写入顺利,每次在拓展时我们就拓展固定宽度,并且调用 ftruncate 将其使用’/0’字符填满,然后每次从第一个非0字符开始写入。
具体操作如下:
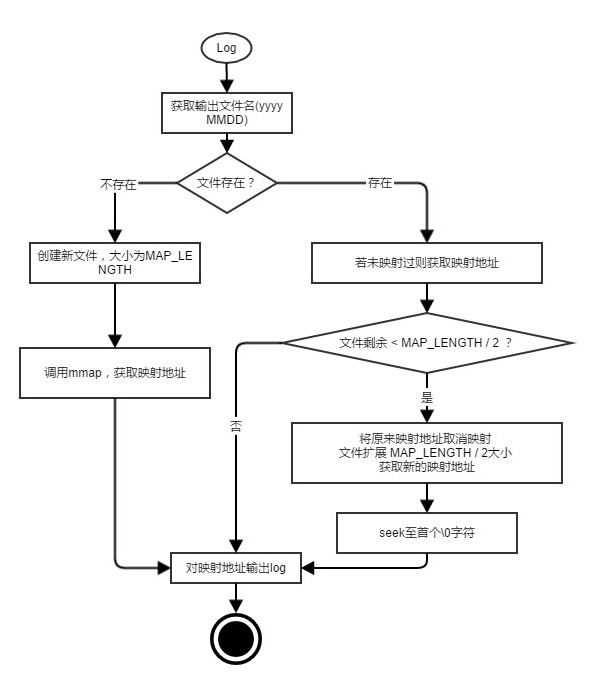
注:
MAP_LENGTH 为map的固定长度区域。每次发现剩余可写空间小于 MAP_LENGH /2时便拓展 MAP_LENGH /2的长度,并把offset设置为(文件大小- MAP_LENGH /2),这样每次map区域都能满足长度为 MAP_LENGTH ,并且动态拓展文件。
但是经过我的实践,这样的效果并不好,原因主要是以下两点:
- 由于目标文件需要动态扩展长度,在map之前需要调用 ftruncate 将其适应到对应长度,这部分会占 一定的开销 ;
- 动态扩展目标文件,每次也是扩展固定的长度,这部分内容会先被填上
0,这样导致了log文件末尾会有多余的0。
让数据说话吧,在迁移xlog之后,我尝试了一下直接map目标文件,动态拓展map的策略,比对xlog方案、Java缓存方案,连续打1000条日志(大约620kb内容),平均5次,几个方案比对下来性能开销如下:
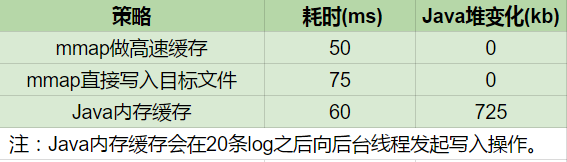
可以看出,确实直接输出目标文件的mmap效率 是不好的 。
迁移思路
要将xlog迁移过来有点麻烦,主要是它带有很多依赖是我不想要的:
- 部分boost,用于filesystem、mmap方面 => 自己手写封装
- 部分common代码,用于线程、互斥锁 => 使用c++11的 thread库 代替
- 里面为了适配跨平台带了很多宏,我们目前只在Android上用,暂时可以去除。
其实它的核心代码不多,所以我决定放弃迁移,学习思路就好了。但是它里面有很多可以借鉴、甚至直接拷贝的好轮子,比如其中的buffer系列:
-
ptrbuffer.cc/.h它用于写入、读取一块 固定长度 的内存区; -
autobuffer.cc/.h它用于写入、读取一块 可变长度 的内存区,它的长度会适应刷入的数据,并且 没有尾部的额外空数据 ;
这两个buffer都是可通用的,它们将内存地址偏移量的各种用法封装地很棒。
在xlog中主要操作的是 log_buffer ,它的作用主要是封装统一接口。因为当mmap失败时,需要使用内存缓存来折中处理,它与mmap的操作相同,都是基于某块内存进行操作。这个 log_buffer 就将对内存的操作交由ptrbuffer,并可以将内容flush到一块autobuffer上。
在需要将内容写到目标文件时,它会通知后台线程将内容刷到autobuffer上,去除尾部的空数据,然后将其写至文件。
在 log_buffer 中写入数据时封装了加密的操作,具体加密实现由 log_crypt.cc/.h 完成,也是可以直接迁移的工具类。
这个思路比较清晰,所以迁移时只要将上面两个可以移植的buffer迁移过来,如果需要加密再移植一下 log_crypt.cc ,基本上很快就就可以写出一套像模像样的xlog出来。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

